 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Predictive Control with Deep Koopman Operators for Autonomous Vehicle Motion Planning
Jun 06, 2026Model Predictive Control (MPC) is widely used for autonomous-vehicle (AV) motion planning, but its real-time applicability is often limited by the need for accurate models and online solution of nonlinear, nonconvex optimization problems in dynamic road environments. Actor-critic reinforcement learning offers a promising alternative for online policy generation, yet its policy-learning process often lacks explicit control-theoretic structure. This article proposes a learning predictive control (LPC) framework with deep Koopman operators for efficient real-time motion planning under nonconvex constraints. To address nonlinear and uncertain vehicle dynamics, a deep-Koopman-based predictor is used to lift the system into an interpretable linear observable space in a data-driven manner. Unlike traditional MPC, which computes open-loop control sequences, the proposed LPC framework yields a closed-loop state-feedback policy within each prediction interval through receding-horizon actor-critic learning. To ensure safety under nonconvex environmental constraints, LPC constructs convex local surrogate representations of obstacles and defines corresponding potential-field functions. These functions and their gradients are directly embedded into the actor-critic structure, enabling efficient, safety-aware policy learning. Extensive simulations and real-world experiments on the HongQi-EHS3 platform demonstrate favorable performance in diverse obstacle-avoidance scenarios in terms of safety, computational efficiency, and driving comfort, compared with benchmark methods such as CBF-MPC and LMPCC.
Ranking Constraints via Topological Dual-Directional Search in Evolutionary Multi-Objective Optimization
Apr 06, 2026Existing evolutionary algorithms for Constrained Multi-objective Optimization Problems (CMOPs) typically treat all constraints uniformly, overlooking their distinct geometric relationships with the true Constrained Pareto Front (CPF). In reality, constraints play different roles: some directly shape the final CPF, some create infeasible obstacles, while others are irrelevant. To exploit this insight, we propose a novel algorithm named RCCMO, which sequentially performs unconstrained exploration, single-constraint exploitation, and full-constraint refinement. The core innovation of RCCMO lies in a constraint prioritization method derived from these geometric insights, seamlessly coupled with a unique dual-directional search mechanism. Specifically, RCCMO first prioritizes constraints that constitute the final CPF, approaching them from the evolutionary direction (optimizing objectives) to locate the CPF directly shaped by single-constraint boundaries. Subsequently, for constraints that merely hinder the population's progress, RCCMO searches from the anti-evolutionary direction (targeting the infeasible boundaries where hindering constraints intersect with the CPF) to effectively discover how these constraints obstruct and form the final CPF. Meanwhile, irrelevant constraints are intentionally bypassed. Furthermore, a series of specialized mechanisms are proposed to accelerate the algorithm's execution, reduce heuristic misjudgments, and dynamically adjust search directions in real time. Extensive experiments on 5 benchmark test suites and 29 real-world CMOPs demonstrate that RCCMO significantly outperforms seven state-of-the-art algorithms.
1.x-Distill: Breaking the Diversity, Quality, and Efficiency Barrier in Distribution Matching Distillation
Apr 05, 2026Diffusion models produce high-quality text-to-image results, but their iterative denoising is computationally expensive.Distribution Matching Distillation (DMD) emerges as a promising path to few-step distillation, but suffers from diversity collapse and fidelity degradation when reduced to two steps or fewer. We present 1.x-Distill, the first fractional-step distillation framework that breaks the integer-step constraint of prior few-step methods and establishes 1.x-step generation as a practical regime for distilled diffusion models.Specifically, we first analyze the overlooked role of teacher CFG in DMD and introduce a simple yet effective modification to suppress mode collapse. Then, to improve performance under extreme steps, we introduce Stagewise Focused Distillation, a two-stage strategy that learns coarse structure through diversity-preserving distribution matching and refines details with inference-consistent adversarial distillation. Furthermore, we design a lightweight compensation module for Distill--Cache co-Training, which naturally incorporates block-level caching into our distillation pipeline.Experiments on SD3-Medium and SD3.5-Large show that 1.x-Distill surpasses prior few-step methods, achieving better quality and diversity at 1.67 and 1.74 effective NFEs, respectively, with up to 33x speedup over original 28x2 NFE sampling.
Tencent Advertising Algorithm Challenge 2025: All-Modality Generative Recommendation
Apr 04, 2026Generative recommender systems are rapidly emerging as a new paradigm for recommendation, where collaborative identifiers and/or multi-modal content are mapped into discrete token spaces and user behavior is modelled with autoregressive sequence models. Despite progress on multi-modal recommendation datasets, there is still a lack of public benchmarks that jointly offer large-scale, realistic and fully all-modality data designed specifically for generative recommendation (GR) in industrial advertising. To foster research in this direction, we organised the Tencent Advertising Algorithm Challenge 2025, a global competition built on top of two all-modality datasets for GR: TencentGR-1M and TencentGR-10M. Both datasets are constructed from real de-identified Tencent Ads logs and contain rich collaborative IDs and multi-modal representations extracted with state-of-the-art embedding models. The preliminary track (TencentGR-1M) provides 1 million user sequences with up to 100 interacted items each, where each interaction is labeled with exposure and click signals, while the final track (TencentGR-10M) scales this to 10 million users and explicitly distinguishes between click and conversion events at both the sequence and target level. This paper presents the task definition, data construction process, feature schema, baseline GR model, evaluation protocol, and key findings from top-ranked and award-winning solutions. Our datasets focus on multi-modal sequence generation in an advertising setting and introduce weighted evaluation for high-value conversion events. We release our datasets at https://huggingface.co/datasets/TAAC2025 and baseline implementations at https://github.com/TencentAdvertisingAlgorithmCompetition/baseline_2025 to enable future research on all-modality generative recommendation at an industrial scale. The official website is https://algo.qq.com/2025.
MemTrust: A Zero-Trust Architecture for Unified AI Memory System
Jan 11, 2026AI memory systems are evolving toward unified context layers that enable efficient cross-agent collaboration and multi-tool workflows, facilitating better accumulation of personal data and learning of user preferences. However, centralization creates a trust crisis where users must entrust cloud providers with sensitive digital memory data. We identify a core tension between personalization demands and data sovereignty: centralized memory systems enable efficient cross-agent collaboration but expose users' sensitive data to cloud provider risks, while private deployments provide security but limit collaboration. To resolve this tension, we aim to achieve local-equivalent security while enabling superior maintenance efficiency and collaborative capabilities. We propose a five-layer architecture abstracting common functional components of AI memory systems: Storage, Extraction, Learning, Retrieval, and Governance. By applying TEE protection to each layer, we establish a trustworthy framework. Based on this, we design MemTrust, a hardware-backed zero-trust architecture that provides cryptographic guarantees across all layers. Our contributions include the five-layer abstraction, "Context from MemTrust" protocol for cross-application sharing, side-channel hardened retrieval with obfuscated access patterns, and comprehensive security analysis. The architecture enables third-party developers to port existing systems with acceptable development costs, achieving system-wide trustworthiness. We believe that AI memory plays a crucial role in enhancing the efficiency and collaboration of agents and AI tools. AI memory will become the foundational infrastructure for AI agents, and MemTrust serves as a universal trusted framework for AI memory systems, with the goal of becoming the infrastructure of memory infrastructure.
Decoupling Constraint from Two Direction in Evolutionary Constrained Multi-objective Optimization
Dec 30, 2025Real-world Constrained Multi-objective Optimization Problems (CMOPs) often contain multiple constraints, and understanding and utilizing the coupling between these constraints is crucial for solving CMOPs. However, existing Constrained Multi-objective Evolutionary Algorithms (CMOEAs) typically ignore these couplings and treat all constraints as a single aggregate, which lacks interpretability regarding the specific geometric roles of constraints. To address this limitation, we first analyze how different constraints interact and show that the final Constrained Pareto Front (CPF) depends not only on the Pareto fronts of individual constraints but also on the boundaries of infeasible regions. This insight implies that CMOPs with different coupling types must be solved from different search directions. Accordingly, we propose a novel algorithm named Decoupling Constraint from Two Directions (DCF2D). This method periodically detects constraint couplings and spawns an auxiliary population for each relevant constraint with an appropriate search direction. Extensive experiments on seven challenging CMOP benchmark suites and on a collection of real-world CMOPs demonstrate that DCF2D outperforms five state-of-the-art CMOEAs, including existing decoupling-based methods.
No Cache Left Idle: Accelerating diffusion model via Extreme-slimming Caching
Dec 14, 2025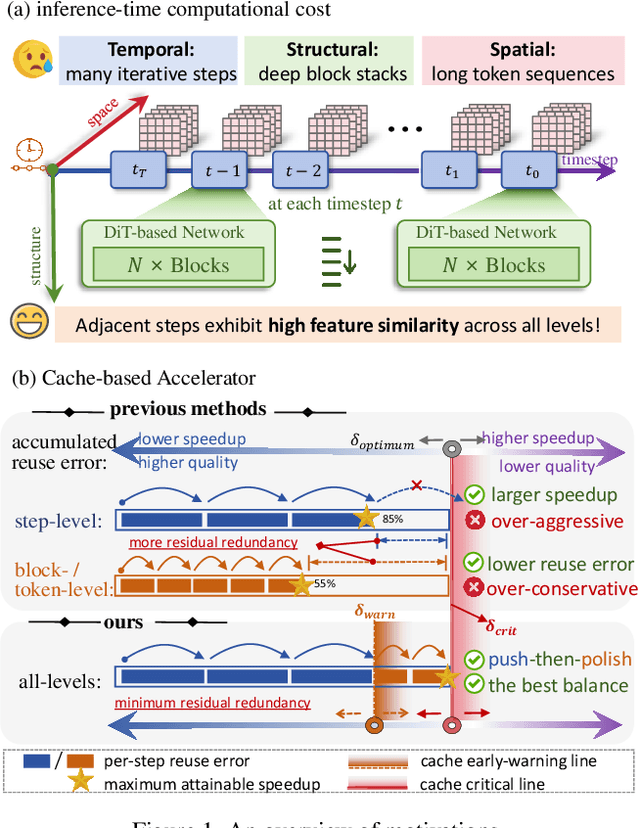
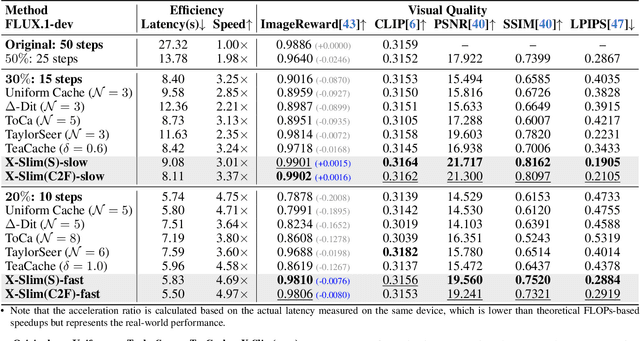
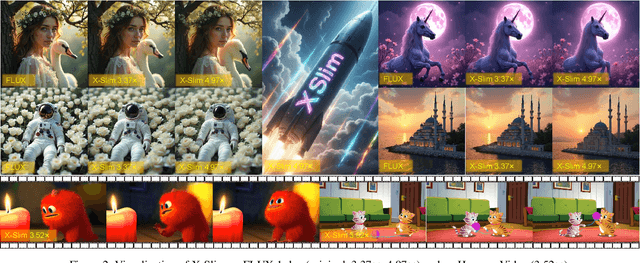
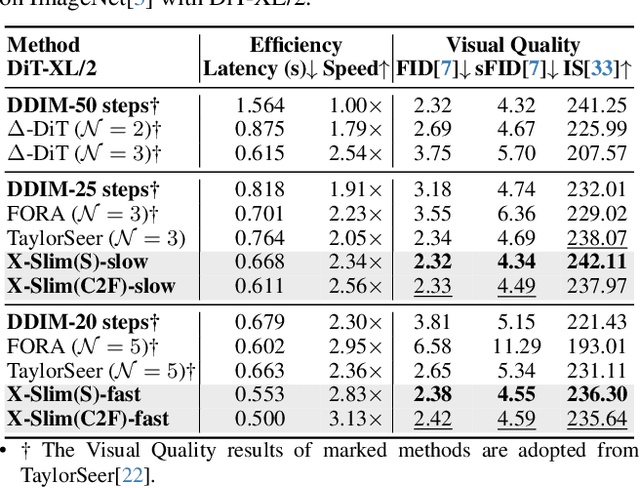
Diffusion models achieve remarkable generative quality, but computational overhead scales with step count, model depth, and sequence length. Feature caching is effective since adjacent timesteps yield highly similar features. However, an inherent trade-off remains: aggressive timestep reuse offers large speedups but can easily cross the critical line, hurting fidelity, while block- or token-level reuse is safer but yields limited computational savings. We present X-Slim (eXtreme-Slimming Caching), a training-free, cache-based accelerator that, to our knowledge, is the first unified framework to exploit cacheable redundancy across timesteps, structure (blocks), and space (tokens). Rather than simply mixing levels, X-Slim introduces a dual-threshold controller that turns caching into a push-then-polish process: it first pushes reuse at the timestep level up to an early-warning line, then switches to lightweight block- and token-level refresh to polish the remaining redundancy, and triggers full inference once the critical line is crossed to reset accumulated error. At each level, context-aware indicators decide when and where to cache. Across diverse tasks, X-Slim advances the speed-quality frontier. On FLUX.1-dev and HunyuanVideo, it reduces latency by up to 4.97x and 3.52x with minimal perceptual loss. On DiT-XL/2, it reaches 3.13x acceleration and improves FID by 2.42 over prior methods.
UPETrack: Unidirectional Position Estimation for Tracking Occluded Deformable Linear Objects
Dec 10, 2025Real-time state tracking of Deformable Linear Objects (DLOs) is critical for enabling robotic manipulation of DLOs in industrial assembly, medical procedures, and daily-life applications. However, the high-dimensional configuration space, nonlinear dynamics, and frequent partial occlusions present fundamental barriers to robust real-time DLO tracking. To address these limitations, this study introduces UPETrack, a geometry-driven framework based on Unidirectional Position Estimation (UPE), which facilitates tracking without the requirement for physical modeling, virtual simulation, or visual markers. The framework operates in two phases: (1) visible segment tracking is based on a Gaussian Mixture Model (GMM) fitted via the Expectation Maximization (EM) algorithm, and (2) occlusion region prediction employing UPE algorithm we proposed. UPE leverages the geometric continuity inherent in DLO shapes and their temporal evolution patterns to derive a closed-form positional estimator through three principal mechanisms: (i) local linear combination displacement term, (ii) proximal linear constraint term, and (iii) historical curvature term. This analytical formulation allows efficient and stable estimation of occluded nodes through explicit linear combinations of geometric components, eliminating the need for additional iterative optimization. Experimental results demonstrate that UPETrack surpasses two state-of-the-art tracking algorithms, including TrackDLO and CDCPD2, in both positioning accuracy and computational efficiency.
Omne-R1: Learning to Reason with Memory for Multi-hop Question Answering
Aug 24, 2025This paper introduces Omne-R1, a novel approach designed to enhance multi-hop question answering capabilities on schema-free knowledge graphs by integrating advanced reasoning models. Our method employs a multi-stage training workflow, including two reinforcement learning phases and one supervised fine-tuning phase. We address the challenge of limited suitable knowledge graphs and QA data by constructing domain-independent knowledge graphs and auto-generating QA pairs. Experimental results show significant improvements in answering multi-hop questions, with notable performance gains on more complex 3+ hop questions. Our proposed training framework demonstrates strong generalization abilities across diverse knowledge domains.
Alita: Generalist Agent Enabling Scalable Agentic Reasoning with Minimal Predefinition and Maximal Self-Evolution
May 26, 2025



Recent advances in large language models (LLMs) have enabled agents to autonomously perform complex, open-ended tasks. However, many existing frameworks depend heavily on manually predefined tools and workflows, which hinder their adaptability, scalability, and generalization across domains. In this work, we introduce Alita--a generalist agent designed with the principle of "Simplicity is the ultimate sophistication," enabling scalable agentic reasoning through minimal predefinition and maximal self-evolution. For minimal predefinition, Alita is equipped with only one component for direct problem-solving, making it much simpler and neater than previous approaches that relied heavily on hand-crafted, elaborate tools and workflows. This clean design enhances its potential to generalize to challenging questions, without being limited by tools. For Maximal self-evolution, we enable the creativity of Alita by providing a suite of general-purpose components to autonomously construct, refine, and reuse external capabilities by generating task-related model context protocols (MCPs) from open source, which contributes to scalable agentic reasoning. Notably, Alita achieves 75.15% pass@1 and 87.27% pass@3 accuracy, which is top-ranking among general-purpose agents, on the GAIA benchmark validation dataset, 74.00% and 52.00% pass@1, respectively, on Mathvista and PathVQA, outperforming many agent systems with far greater complexity. More details will be updated at $\href{https://github.com/CharlesQ9/Alita}{https://github.com/CharlesQ9/Alita}$.