 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Code Graphs and Large Language Models for Better Code Understanding
Dec 08, 2025



Large Language Models (LLMs) have demonstrated remarkable performance in code intelligence tasks such as code generation, summarization, and translation. However, their reliance on linearized token sequences limits their ability to understand the structural semantics of programs. While prior studies have explored graphaugmented prompting and structure-aware pretraining, they either suffer from prompt length constraints or require task-specific architectural changes that are incompatible with large-scale instructionfollowing LLMs. To address these limitations, this paper proposes CGBridge, a novel plug-and-play method that enhances LLMs with Code Graph information through an external, trainable Bridge module. CGBridge first pre-trains a code graph encoder via selfsupervised learning on a large-scale dataset of 270K code graphs to learn structural code semantics. It then trains an external module to bridge the modality gap among code, graph, and text by aligning their semantics through cross-modal attention mechanisms. Finally, the bridge module generates structure-informed prompts, which are injected into a frozen LLM, and is fine-tuned for downstream code intelligence tasks. Experiments show that CGBridge achieves notable improvements over both the original model and the graphaugmented prompting method. Specifically, it yields a 16.19% and 9.12% relative gain in LLM-as-a-Judge on code summarization, and a 9.84% and 38.87% relative gain in Execution Accuracy on code translation. Moreover, CGBridge achieves over 4x faster inference than LoRA-tuned models, demonstrating both effectiveness and efficiency in structure-aware code understanding.
nvAgent: Automated Data Visualization from Natural Language via Collaborative Agent Workflow
Feb 07, 2025



Natural Language to Visualization (NL2Vis) seeks to convert natural-language descriptions into visual representations of given tables, empowering users to derive insights from large-scale data. Recent advancements in Large Language Models (LLMs) show promise in automating code generation to transform tabular data into accessible visualizations. However, they often struggle with complex queries that require reasoning across multiple tables. To address this limitation, we propose a collaborative agent workflow, termed nvAgent, for NL2Vis. Specifically, nvAgent comprises three agents: a processor agent for database processing and context filtering, a composer agent for planning visualization generation, and a validator agent for code translation and output verification. Comprehensive evaluations on the new VisEval benchmark demonstrate that nvAgent consistently surpasses state-of-the-art baselines, achieving a 7.88% improvement in single-table and a 9.23% improvement in multi-table scenarios. Qualitative analyses further highlight that nvAgent maintains nearly a 20% performance margin over previous models, underscoring its capacity to produce high-quality visual representations from complex, heterogeneous data sources.
GUI-WORLD: A Dataset for GUI-oriented Multimodal LLM-based Agents
Jun 16, 2024



Recently, Multimodal Large Language Models (MLLMs) have been used as agents to control keyboard and mouse inputs by directly perceiving the Graphical User Interface (GUI) and generating corresponding code. However, current agents primarily exhibit excellent understanding capabilities in static environments and are predominantly applied in relatively simple domains, such as Web or mobile interfaces. We argue that a robust GUI agent should be capable of perceiving temporal information on the GUI, including dynamic Web content and multi-step tasks. Additionally, it should possess a comprehensive understanding of various GUI scenarios, including desktop software and multi-window interactions. To this end, this paper introduces a new dataset, termed GUI-World, which features meticulously crafted Human-MLLM annotations, extensively covering six GUI scenarios and eight types of GUI-oriented questions in three formats. We evaluate the capabilities of current state-of-the-art MLLMs, including ImageLLMs and VideoLLMs, in understanding various types of GUI content, especially dynamic and sequential content. Our findings reveal that ImageLLMs struggle with dynamic GUI content without manually annotated keyframes or operation history. On the other hand, VideoLLMs fall short in all GUI-oriented tasks given the sparse GUI video dataset. Based on GUI-World, we take the initial step of leveraging a fine-tuned VideoLLM as a GUI agent, demonstrating an improved understanding of various GUI tasks. However, due to the limitations in the performance of base LLMs, we conclude that using VideoLLMs as GUI agents remains a significant challenge. We believe our work provides valuable insights for future research in dynamic GUI content understanding. The code and dataset are publicly available at our project homepage: https://gui-world.github.io/.
VISION2UI: A Real-World Dataset with Layout for Code Generation from UI Designs
Apr 09, 2024Automatically generating UI code from webpage design visions can significantly alleviate the burden of developers, enabling beginner developers or designers to directly generate Web pages from design diagrams. Currently, prior research has accomplished the objective of generating UI code from rudimentary design visions or sketches through designing deep neural networks. Inspired by the groundbreaking advancements achieved by Multimodal Large Language Models (MLLMs), the automatic generation of UI code from high-fidelity design images is now emerging as a viable possibility. Nevertheless, our investigation reveals that existing MLLMs are hampered by the scarcity of authentic, high-quality, and large-scale datasets, leading to unsatisfactory performance in automated UI code generation. To mitigate this gap, we present a novel dataset, termed VISION2UI, extracted from real-world scenarios, augmented with comprehensive layout information, tailored specifically for finetuning MLLMs in UI code generation. Specifically, this dataset is derived through a series of operations, encompassing collecting, cleaning, and filtering of the open-source Common Crawl dataset. In order to uphold its quality, a neural scorer trained on labeled samples is utilized to refine the data, retaining higher-quality instances. Ultimately, this process yields a dataset comprising 2,000 (Much more is coming soon) parallel samples encompassing design visions and UI code. The dataset is available at https://huggingface.co/datasets/xcodemind/vision2ui.
Stock Trading Optimization through Model-based Reinforcement Learning with Resistance Support Relative Strength
May 30, 2022

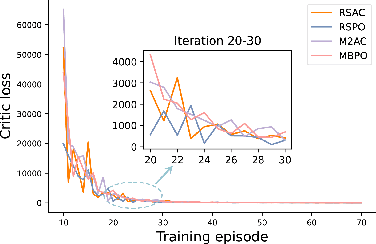
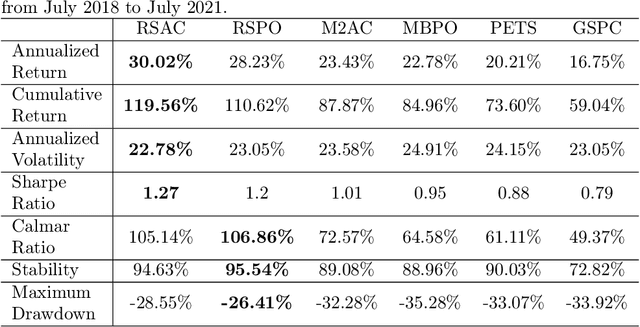
Reinforcement learning (RL) is gaining attention by more and more researchers in quantitative finance as the agent-environment interaction framework is aligned with decision making process in many business problems. Most of the current financial applications using RL algorithms are based on model-free method, which still faces stability and adaptivity challenges. As lots of cutting-edge model-based reinforcement learning (MBRL) algorithms mature in applications such as video games or robotics, we design a new approach that leverages resistance and support (RS) level as regularization terms for action in MBRL, to improve the algorithm's efficiency and stability. From the experiment results, we can see RS level, as a market timing technique, enhances the performance of pure MBRL models in terms of various measurements and obtains better profit gain with less riskiness. Besides, our proposed method even resists big drop (less maximum drawdown) during COVID-19 pandemic period when the financial market got unpredictable crisis. Explanations on why control of resistance and support level can boost MBRL is also investigated through numerical experiments, such as loss of actor-critic network and prediction error of the transition dynamical model. It shows that RS indicators indeed help the MBRL algorithms to converge faster at early stage and obtain smaller critic loss as training episodes increase.
Cross-Language Binary-Source Code Matching with Intermediate Representations
Jan 19, 2022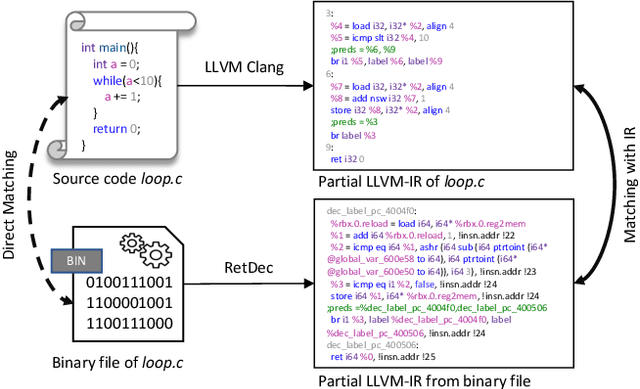
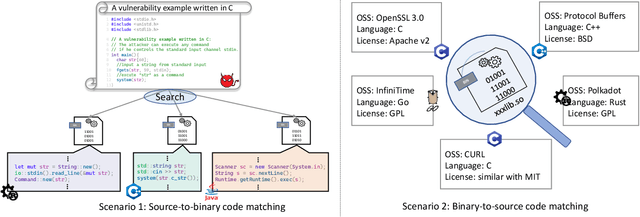
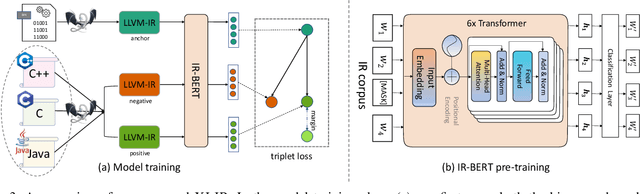
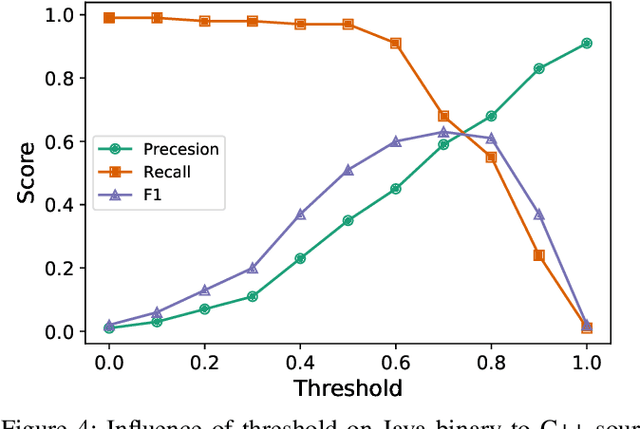
Binary-source code matching plays an important role in many security and software engineering related tasks such as malware detection, reverse engineering and vulnerability assessment. Currently, several approaches have been proposed for binary-source code matching by jointly learning the embeddings of binary code and source code in a common vector space. Despite much effort, existing approaches target on matching the binary code and source code written in a single programming language. However, in practice, software applications are often written in different programming languages to cater for different requirements and computing platforms. Matching binary and source code across programming languages introduces additional challenges when maintaining multi-language and multi-platform applications. To this end, this paper formulates the problem of cross-language binary-source code matching, and develops a new dataset for this new problem. We present a novel approach XLIR, which is a Transformer-based neural network by learning the intermediate representations for both binary and source code. To validate the effectiveness of XLIR, comprehensive experiments are conducted on two tasks of cross-language binary-source code matching, and cross-language source-source code matching, on top of our curated dataset. Experimental results and analysis show that our proposed XLIR with intermediate representations significantly outperforms other state-of-the-art models in both of the two tasks.