 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Reliable LLM-Assisted Rubric Scoring for Constructed Responses: Evidence from Physics Exams
Apr 14, 2026Student responses in STEM assessments are often handwritten and combine symbolic expressions, calculations, and diagrams, creating substantial variation in format and interpretation. Despite their importance for evaluating students' reasoning, such responses are time-consuming to score and prone to rater inconsistency, particularly when partial credit is required. Recent advances in large language models (LLMs) have increased attention to AI-assisted scoring, yet evidence remains limited regarding how rubric design and LLM configurations influence reliability across performance levels. This study examined the reliability of AI-assisted scoring of undergraduate physics constructed responses using GPT-4o. Twenty authentic handwritten exam responses were scored across two rounds by four instructors and by the AI model using skill-based rubrics with differing levels of analytic granularity. Prompting format and temperature settings were systematically varied. Overall, human-AI agreement on total scores was comparable to human inter-rater reliability and was highest for high- and low-performing responses, but declined for mid-level responses involving partial or ambiguous reasoning. Criterion-level analyses showed stronger alignment for clearly defined conceptual skills than for extended procedural judgments. A more fine-grained, checklist-based rubric improved consistency relative to holistic scoring. These findings indicate that reliable AI-assisted scoring depends primarily on clear, well-structured rubrics, while prompting format plays a secondary role and temperature has relatively limited impact. More broadly, the study provides transferable design recommendations for implementing reliable LLM-assisted scoring in STEM contexts through skill-based rubrics and controlled LLM settings.
SenseMath: Do LLMs Have Number Sense? Evaluating Shortcut Use, Judgment, and Generation
Apr 02, 2026Large language models often default to step-by-step computation even when efficient numerical shortcuts are available. This raises a basic question: do they exhibit number sense in a human-like behavioral sense, i.e., the ability to recognize numerical structure, apply shortcuts when appropriate, and avoid them when they are not? We introduce SenseMath, a controlled benchmark for evaluating structure-sensitive numerical reasoning in LLMs. SenseMath contains 4,800 items spanning eight shortcut categories and four digit scales, with matched strong-shortcut, weak-shortcut, and control variants. It supports three evaluation settings of increasing cognitive demand: Shortcut Use (whether models can apply shortcuts on shortcut-amenable problems); Applicability Judgment (whether they can recognize when a shortcut is appropriate or misleading); and Problem Generation (whether they can generate new problem items that correctly admit a given type of shortcut). Our evaluation across five LLMs, ranging from GPT-4o-mini to Llama-3.1-8B, shows a consistent pattern: when explicitly prompted, models readily adopt shortcut strategies and achieve substantial accuracy gains on shortcut-amenable items (up to 15%), yet under standard chain-of-thought prompting they spontaneously employ such strategies in fewer than 40% of cases, even when they demonstrably possess the requisite capability. Moreover, this competence is confined to the Use level; models systematically over-generalise shortcuts to problems where they do not apply, and fail to generate valid shortcut-bearing problems from scratch. Together, these results suggest that current LLMs exhibit procedural shortcut fluency without the structural understanding of when and why shortcuts work that underlies human number sense.
MAGA-Bench: Machine-Augment-Generated Text via Alignment Detection Benchmark
Jan 08, 2026Large Language Models (LLMs) alignment is constantly evolving. Machine-Generated Text (MGT) is becoming increasingly difficult to distinguish from Human-Written Text (HWT). This has exacerbated abuse issues such as fake news and online fraud. Fine-tuned detectors' generalization ability is highly dependent on dataset quality, and simply expanding the sources of MGT is insufficient. Further augment of generation process is required. According to HC-Var's theory, enhancing the alignment of generated text can not only facilitate attacks on existing detectors to test their robustness, but also help improve the generalization ability of detectors fine-tuned on it. Therefore, we propose \textbf{M}achine-\textbf{A}ugment-\textbf{G}enerated Text via \textbf{A}lignment (MAGA). MAGA's pipeline achieves comprehensive alignment from prompt construction to reasoning process, among which \textbf{R}einforced \textbf{L}earning from \textbf{D}etectors \textbf{F}eedback (RLDF), systematically proposed by us, serves as a key component. In our experiments, the RoBERTa detector fine-tuned on MAGA training set achieved an average improvement of 4.60\% in generalization detection AUC. MAGA Dataset caused an average decrease of 8.13\% in the AUC of the selected detectors, expecting to provide indicative significance for future research on the generalization detection ability of detectors.
VADER: Towards Causal Video Anomaly Understanding with Relation-Aware Large Language Models
Nov 10, 2025



Video anomaly understanding (VAU) aims to provide detailed interpretation and semantic comprehension of anomalous events within videos, addressing limitations of traditional methods that focus solely on detecting and localizing anomalies. However, existing approaches often neglect the deeper causal relationships and interactions between objects, which are critical for understanding anomalous behaviors. In this paper, we propose VADER, an LLM-driven framework for Video Anomaly unDErstanding, which integrates keyframe object Relation features with visual cues to enhance anomaly comprehension from video. Specifically, VADER first applies an Anomaly Scorer to assign per-frame anomaly scores, followed by a Context-AwarE Sampling (CAES) strategy to capture the causal context of each anomalous event. A Relation Feature Extractor and a COntrastive Relation Encoder (CORE) jointly model dynamic object interactions, producing compact relational representations for downstream reasoning. These visual and relational cues are integrated with LLMs to generate detailed, causally grounded descriptions and support robust anomaly-related question answering. Experiments on multiple real-world VAU benchmarks demonstrate that VADER achieves strong results across anomaly description, explanation, and causal reasoning tasks, advancing the frontier of explainable video anomaly analysis.
MovieCORE: COgnitive REasoning in Movies
Aug 26, 2025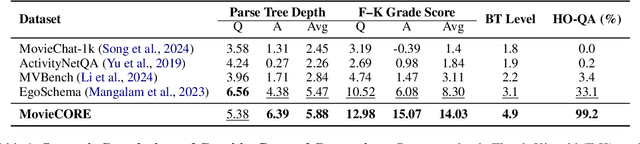
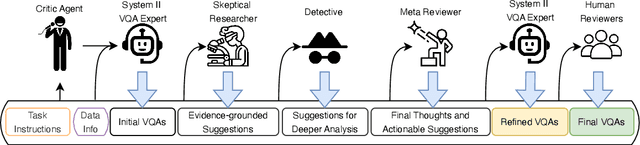
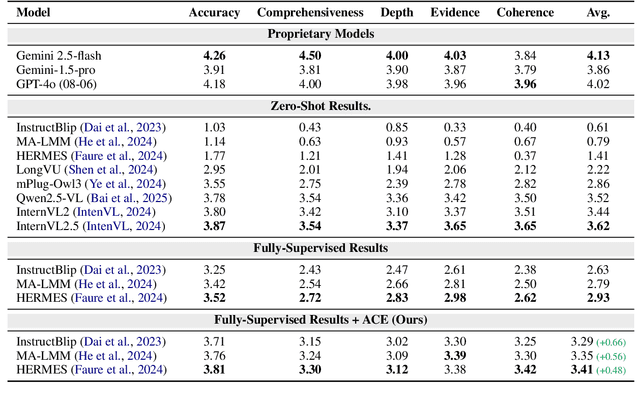

This paper introduces MovieCORE, a novel video question answering (VQA) dataset designed to probe deeper cognitive understanding of movie content. Unlike existing datasets that focus on surface-level comprehension, MovieCORE emphasizes questions that engage System-2 thinking while remaining specific to the video material. We present an innovative agentic brainstorming approach, utilizing multiple large language models (LLMs) as thought agents to generate and refine high-quality question-answer pairs. To evaluate dataset quality, we develop a set of cognitive tests assessing depth, thought-provocation potential, and syntactic complexity. We also propose a comprehensive evaluation scheme for assessing VQA model performance on deeper cognitive tasks. To address the limitations of existing video-language models (VLMs), we introduce an agentic enhancement module, Agentic Choice Enhancement (ACE), which improves model reasoning capabilities post-training by up to 25%. Our work contributes to advancing movie understanding in AI systems and provides valuable insights into the capabilities and limitations of current VQA models when faced with more challenging, nuanced questions about cinematic content. Our project page, dataset and code can be found at https://joslefaure.github.io/assets/html/moviecore.html.
FineMedLM-o1: Enhancing the Medical Reasoning Ability of LLM from Supervised Fine-Tuning to Test-Time Training
Jan 16, 2025Recent advancements in large language models (LLMs) have shown promise in medical applications such as disease diagnosis and treatment planning. However, most existing medical LLMs struggle with the advanced reasoning required for complex clinical scenarios, such as differential diagnosis or personalized treatment suggestions. We proposed FineMedLM-o1, which leverages high-quality synthetic medical data and long-form reasoning data for Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO), enabling advanced dialogue and deep reasoning capabilities. Additionally, we introduced Test-Time Training (TTT) in the medical domain for the first time, facilitating domain adaptation and ensuring reliable, accurate reasoning. Experimental results demonstrate that FineMedLM-o1 achieves a 23% average performance improvement over prior models on key medical benchmarks. Furthermore, the introduction of TTT provides an additional 14% performance boost, highlighting its effectiveness in enhancing medical reasoning capabilities. To support this process, we also proposed a novel method for synthesizing medical dialogue. Compared to other open-source datasets, our dataset stands out as superior in both quality and complexity. The project and data will be released on GitHub.
CT2C-QA: Multimodal Question Answering over Chinese Text, Table and Chart
Oct 28, 2024Multimodal Question Answering (MMQA) is crucial as it enables comprehensive understanding and accurate responses by integrating insights from diverse data representations such as tables, charts, and text. Most existing researches in MMQA only focus on two modalities such as image-text QA, table-text QA and chart-text QA, and there remains a notable scarcity in studies that investigate the joint analysis of text, tables, and charts. In this paper, we present C$\text{T}^2$C-QA, a pioneering Chinese reasoning-based QA dataset that includes an extensive collection of text, tables, and charts, meticulously compiled from 200 selectively sourced webpages. Our dataset simulates real webpages and serves as a great test for the capability of the model to analyze and reason with multimodal data, because the answer to a question could appear in various modalities, or even potentially not exist at all. Additionally, we present AED (\textbf{A}llocating, \textbf{E}xpert and \textbf{D}esicion), a multi-agent system implemented through collaborative deployment, information interaction, and collective decision-making among different agents. Specifically, the Assignment Agent is in charge of selecting and activating expert agents, including those proficient in text, tables, and charts. The Decision Agent bears the responsibility of delivering the final verdict, drawing upon the analytical insights provided by these expert agents. We execute a comprehensive analysis, comparing AED with various state-of-the-art models in MMQA, including GPT-4. The experimental outcomes demonstrate that current methodologies, including GPT-4, are yet to meet the benchmarks set by our dataset.
ADSNet: Cross-Domain LTV Prediction with an Adaptive Siamese Network in Advertising
Jun 15, 2024



Advertising platforms have evolved in estimating Lifetime Value (LTV) to better align with advertisers' true performance metric. However, the sparsity of real-world LTV data presents a significant challenge to LTV predictive model(i.e., pLTV), severely limiting the their capabilities. Therefore, we propose to utilize external data, in addition to the internal data of advertising platform, to expand the size of purchase samples and enhance the LTV prediction model of the advertising platform. To tackle the issue of data distribution shift between internal and external platforms, we introduce an Adaptive Difference Siamese Network (ADSNet), which employs cross-domain transfer learning to prevent negative transfer. Specifically, ADSNet is designed to learn information that is beneficial to the target domain. We introduce a gain evaluation strategy to calculate information gain, aiding the model in learning helpful information for the target domain and providing the ability to reject noisy samples, thus avoiding negative transfer. Additionally, we also design a Domain Adaptation Module as a bridge to connect different domains, reduce the distribution distance between them, and enhance the consistency of representation space distribution. We conduct extensive offline experiments and online A/B tests on a real advertising platform. Our proposed ADSNet method outperforms other methods, improving GINI by 2$\%$. The ablation study highlights the importance of the gain evaluation strategy in negative gain sample rejection and improving model performance. Additionally, ADSNet significantly improves long-tail prediction. The online A/B tests confirm ADSNet's efficacy, increasing online LTV by 3.47$\%$ and GMV by 3.89$\%$.
Modality-Aware Contrastive Instance Learning with Self-Distillation for Weakly-Supervised Audio-Visual Violence Detection
Jul 12, 2022



Weakly-supervised audio-visual violence detection aims to distinguish snippets containing multimodal violence events with video-level labels. Many prior works perform audio-visual integration and interaction in an early or intermediate manner, yet overlooking the modality heterogeneousness over the weakly-supervised setting. In this paper, we analyze the modality asynchrony and undifferentiated instances phenomena of the multiple instance learning (MIL) procedure, and further investigate its negative impact on weakly-supervised audio-visual learning. To address these issues, we propose a modality-aware contrastive instance learning with self-distillation (MACIL-SD) strategy. Specifically, we leverage a lightweight two-stream network to generate audio and visual bags, in which unimodal background, violent, and normal instances are clustered into semi-bags in an unsupervised way. Then audio and visual violent semi-bag representations are assembled as positive pairs, and violent semi-bags are combined with background and normal instances in the opposite modality as contrastive negative pairs. Furthermore, a self-distillation module is applied to transfer unimodal visual knowledge to the audio-visual model, which alleviates noises and closes the semantic gap between unimodal and multimodal features. Experiments show that our framework outperforms previous methods with lower complexity on the large-scale XD-Violence dataset. Results also demonstrate that our proposed approach can be used as plug-in modules to enhance other networks. Codes are available at https://github.com/JustinYuu/MACIL_SD.
IDEA: Increasing Text Diversity via Online Multi-Label Recognition for Vision-Language Pre-training
Jul 12, 2022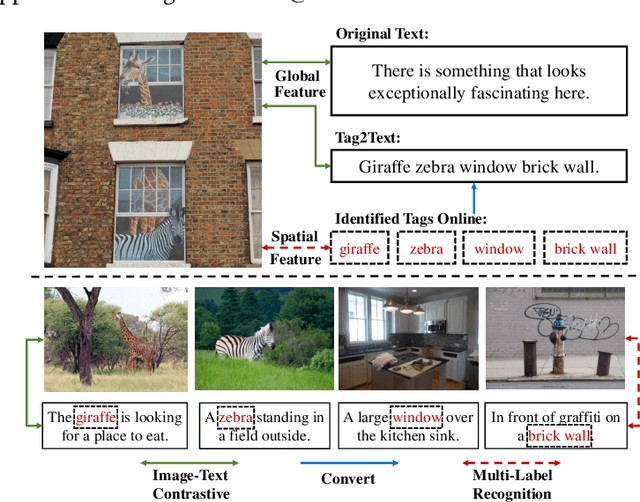
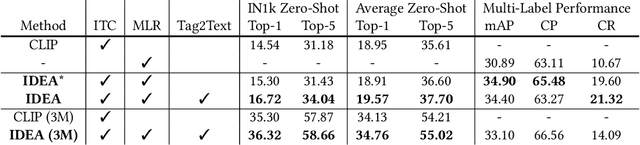
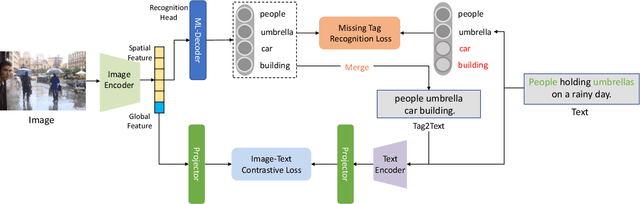
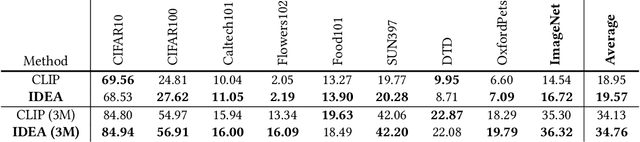
Vision-Language Pre-training (VLP) with large-scale image-text pairs has demonstrated superior performance in various fields. However, the image-text pairs co-occurrent on the Internet typically lack explicit alignment information, which is suboptimal for VLP. Existing methods proposed to adopt an off-the-shelf object detector to utilize additional image tag information. However, the object detector is time-consuming and can only identify the pre-defined object categories, limiting the model capacity. Inspired by the observation that the texts incorporate incomplete fine-grained image information, we introduce IDEA, which stands for increasing text diversity via online multi-label recognition for VLP. IDEA shows that multi-label learning with image tags extracted from the texts can be jointly optimized during VLP. Moreover, IDEA can identify valuable image tags online to provide more explicit textual supervision. Comprehensive experiments demonstrate that IDEA can significantly boost the performance on multiple downstream datasets with a small extra computational cost.