 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralGS: Bridging Neural Fields and 3D Gaussian Splatting for Compact 3D Representations
Mar 29, 2025



3D Gaussian Splatting (3DGS) demonstrates superior quality and rendering speed, but with millions of 3D Gaussians and significant storage and transmission costs. Recent 3DGS compression methods mainly concentrate on compressing Scaffold-GS, achieving impressive performance but with an additional voxel structure and a complex encoding and quantization strategy. In this paper, we aim to develop a simple yet effective method called NeuralGS that explores in another way to compress the original 3DGS into a compact representation without the voxel structure and complex quantization strategies. Our observation is that neural fields like NeRF can represent complex 3D scenes with Multi-Layer Perceptron (MLP) neural networks using only a few megabytes. Thus, NeuralGS effectively adopts the neural field representation to encode the attributes of 3D Gaussians with MLPs, only requiring a small storage size even for a large-scale scene. To achieve this, we adopt a clustering strategy and fit the Gaussians with different tiny MLPs for each cluster, based on importance scores of Gaussians as fitting weights. We experiment on multiple datasets, achieving a 45-times average model size reduction without harming the visual quality. The compression performance of our method on original 3DGS is comparable to the dedicated Scaffold-GS-based compression methods, which demonstrate the huge potential of directly compressing original 3DGS with neural fields.
AE-NeRF: Augmenting Event-Based Neural Radiance Fields for Non-ideal Conditions and Larger Scene
Jan 07, 2025Compared to frame-based methods, computational neuromorphic imaging using event cameras offers significant advantages, such as minimal motion blur, enhanced temporal resolution, and high dynamic range. The multi-view consistency of Neural Radiance Fields combined with the unique benefits of event cameras, has spurred recent research into reconstructing NeRF from data captured by moving event cameras. While showing impressive performance, existing methods rely on ideal conditions with the availability of uniform and high-quality event sequences and accurate camera poses, and mainly focus on the object level reconstruction, thus limiting their practical applications. In this work, we propose AE-NeRF to address the challenges of learning event-based NeRF from non-ideal conditions, including non-uniform event sequences, noisy poses, and various scales of scenes. Our method exploits the density of event streams and jointly learn a pose correction module with an event-based NeRF (e-NeRF) framework for robust 3D reconstruction from inaccurate camera poses. To generalize to larger scenes, we propose hierarchical event distillation with a proposal e-NeRF network and a vanilla e-NeRF network to resample and refine the reconstruction process. We further propose an event reconstruction loss and a temporal loss to improve the view consistency of the reconstructed scene. We established a comprehensive benchmark that includes large-scale scenes to simulate practical non-ideal conditions, incorporating both synthetic and challenging real-world event datasets. The experimental results show that our method achieves a new state-of-the-art in event-based 3D reconstruction.
Open-Sora Plan: Open-Source Large Video Generation Model
Nov 28, 2024



We introduce Open-Sora Plan, an open-source project that aims to contribute a large generation model for generating desired high-resolution videos with long durations based on various user inputs. Our project comprises multiple components for the entire video generation process, including a Wavelet-Flow Variational Autoencoder, a Joint Image-Video Skiparse Denoiser, and various condition controllers. Moreover, many assistant strategies for efficient training and inference are designed, and a multi-dimensional data curation pipeline is proposed for obtaining desired high-quality data. Benefiting from efficient thoughts, our Open-Sora Plan achieves impressive video generation results in both qualitative and quantitative evaluations. We hope our careful design and practical experience can inspire the video generation research community. All our codes and model weights are publicly available at \url{https://github.com/PKU-YuanGroup/Open-Sora-Plan}.
Cycle3D: High-quality and Consistent Image-to-3D Generation via Generation-Reconstruction Cycle
Jul 28, 2024



Recent 3D large reconstruction models typically employ a two-stage process, including first generate multi-view images by a multi-view diffusion model, and then utilize a feed-forward model to reconstruct images to 3D content.However, multi-view diffusion models often produce low-quality and inconsistent images, adversely affecting the quality of the final 3D reconstruction. To address this issue, we propose a unified 3D generation framework called Cycle3D, which cyclically utilizes a 2D diffusion-based generation module and a feed-forward 3D reconstruction module during the multi-step diffusion process. Concretely, 2D diffusion model is applied for generating high-quality texture, and the reconstruction model guarantees multi-view consistency.Moreover, 2D diffusion model can further control the generated content and inject reference-view information for unseen views, thereby enhancing the diversity and texture consistency of 3D generation during the denoising process. Extensive experiments demonstrate the superior ability of our method to create 3D content with high-quality and consistency compared with state-of-the-art baselines.
Envision3D: One Image to 3D with Anchor Views Interpolation
Mar 13, 2024



We present Envision3D, a novel method for efficiently generating high-quality 3D content from a single image. Recent methods that extract 3D content from multi-view images generated by diffusion models show great potential. However, it is still challenging for diffusion models to generate dense multi-view consistent images, which is crucial for the quality of 3D content extraction. To address this issue, we propose a novel cascade diffusion framework, which decomposes the challenging dense views generation task into two tractable stages, namely anchor views generation and anchor views interpolation. In the first stage, we train the image diffusion model to generate global consistent anchor views conditioning on image-normal pairs. Subsequently, leveraging our video diffusion model fine-tuned on consecutive multi-view images, we conduct interpolation on the previous anchor views to generate extra dense views. This framework yields dense, multi-view consistent images, providing comprehensive 3D information. To further enhance the overall generation quality, we introduce a coarse-to-fine sampling strategy for the reconstruction algorithm to robustly extract textured meshes from the generated dense images. Extensive experiments demonstrate that our method is capable of generating high-quality 3D content in terms of texture and geometry, surpassing previous image-to-3D baseline methods.
LLMBind: A Unified Modality-Task Integration Framework
Mar 08, 2024



While recent progress in multimodal large language models tackles various modality tasks, they posses limited integration capabilities for complex multi-modality tasks, consequently constraining the development of the field. In this work, we take the initiative to explore and propose the LLMBind, a unified framework for modality task integration, which binds Large Language Models and corresponding pre-trained task models with task-specific tokens. Consequently, LLMBind can interpret inputs and produce outputs in versatile combinations of image, text, video, and audio. Specifically, we introduce a Mixture-of-Experts technique to enable effective learning for different multimodal tasks through collaboration among diverse experts. Furthermore, we create a multi-task dataset comprising 400k instruction data, which unlocks the ability for interactive visual generation and editing tasks. Extensive experiments show the effectiveness of our framework across various tasks, including image, video, audio generation, image segmentation, and image editing. More encouragingly, our framework can be easily extended to other modality tasks, showcasing the promising potential of creating a unified AI agent for modeling universal modalities.
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
Feb 04, 2024



Recent advances demonstrate that scaling Large Vision-Language Models (LVLMs) effectively improves downstream task performances. However, existing scaling methods enable all model parameters to be active for each token in the calculation, which brings massive training and inferring costs. In this work, we propose a simple yet effective training strategy MoE-Tuning for LVLMs. This strategy innovatively addresses the common issue of performance degradation in multi-modal sparsity learning, consequently constructing a sparse model with an outrageous number of parameters but a constant computational cost. Furthermore, we present the MoE-LLaVA, a MoE-based sparse LVLM architecture, which uniquely activates only the top-k experts through routers during deployment, keeping the remaining experts inactive. Extensive experiments show the significant performance of MoE-LLaVA in a variety of visual understanding and object hallucination benchmarks. Remarkably, with only approximately 3B sparsely activated parameters, MoE-LLaVA demonstrates performance comparable to the LLaVA-1.5-7B on various visual understanding datasets and even surpasses the LLaVA-1.5-13B in object hallucination benchmark. Through MoE-LLaVA, we aim to establish a baseline for sparse LVLMs and provide valuable insights for future research in developing more efficient and effective multi-modal learning systems. Code is released at \url{https://github.com/PKU-YuanGroup/MoE-LLaVA}.
Repaint123: Fast and High-quality One Image to 3D Generation with Progressive Controllable 2D Repainting
Dec 27, 2023



Recent one image to 3D generation methods commonly adopt Score Distillation Sampling (SDS). Despite the impressive results, there are multiple deficiencies including multi-view inconsistency, over-saturated and over-smoothed textures, as well as the slow generation speed. To address these deficiencies, we present Repaint123 to alleviate multi-view bias as well as texture degradation and speed up the generation process. The core idea is to combine the powerful image generation capability of the 2D diffusion model and the texture alignment ability of the repainting strategy for generating high-quality multi-view images with consistency. We further propose visibility-aware adaptive repainting strength for overlap regions to enhance the generated image quality in the repainting process. The generated high-quality and multi-view consistent images enable the use of simple Mean Square Error (MSE) loss for fast 3D content generation. We conduct extensive experiments and show that our method has a superior ability to generate high-quality 3D content with multi-view consistency and fine textures in 2 minutes from scratch. Our project page is available at https://pku-yuangroup.github.io/repaint123/.
LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment
Oct 14, 2023



The video-language (VL) pretraining has achieved remarkable improvement in multiple downstream tasks. However, the current VL pretraining framework is hard to extend to multiple modalities (N modalities, N>=3) beyond vision and language. We thus propose LanguageBind, taking the language as the bind across different modalities because the language modality is well-explored and contains rich semantics. Specifically, we freeze the language encoder acquired by VL pretraining, then train encoders for other modalities with contrastive learning. As a result, all modalities are mapped to a shared feature space, implementing multi-modal semantic alignment. While LanguageBind ensures that we can extend VL modalities to N modalities, we also need a high-quality dataset with alignment data pairs centered on language. We thus propose VIDAL-10M with Video, Infrared, Depth, Audio and their corresponding Language, naming as VIDAL-10M. In our VIDAL-10M, all videos are from short video platforms with complete semantics rather than truncated segments from long videos, and all the video, depth, infrared, and audio modalities are aligned to their textual descriptions. After pretraining on VIDAL-10M, we outperform ImageBind by 5.8% R@1 on the MSR-VTT dataset with only 15% of the parameters in the zero-shot video-text retrieval task. Beyond this, our LanguageBind has greatly improved in the zero-shot video, audio, depth, and infrared understanding tasks. For instance, LanguageBind surpassing InterVideo by 1.9% on MSR-VTT, 8.8% on MSVD, 6.3% on DiDeMo, and 4.4% on ActivityNet. On the LLVIP and NYU-D datasets, LanguageBind outperforms ImageBind with 23.8% and 11.1% top-1 accuracy. Code address: https://github.com/PKU-YuanGroup/LanguageBind.
Learnable Privacy-Preserving Anonymization for Pedestrian Images
Jul 24, 2022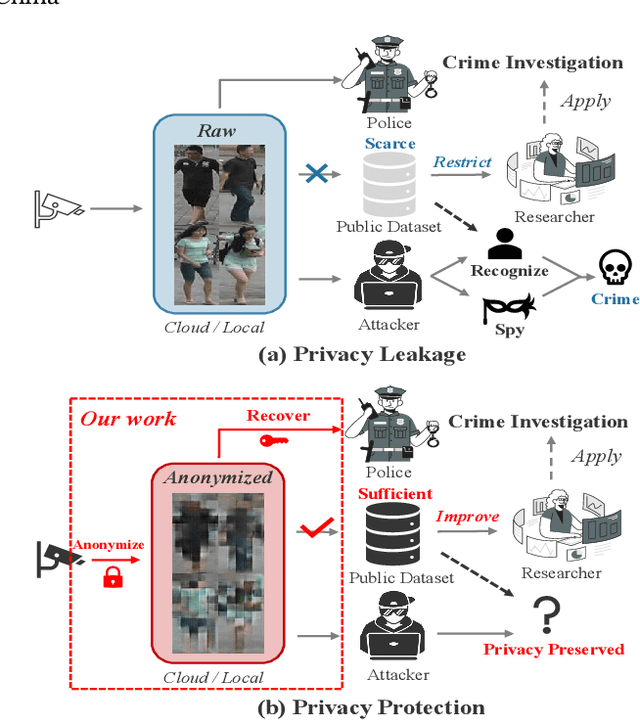
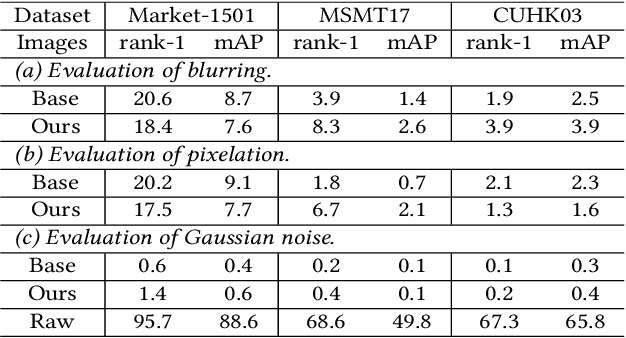
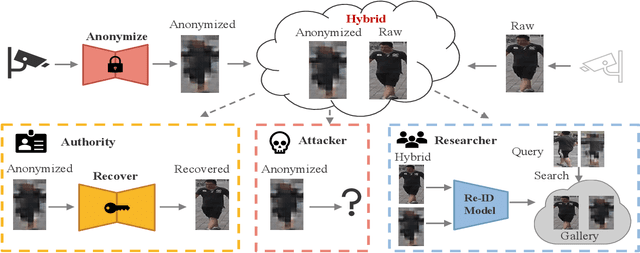
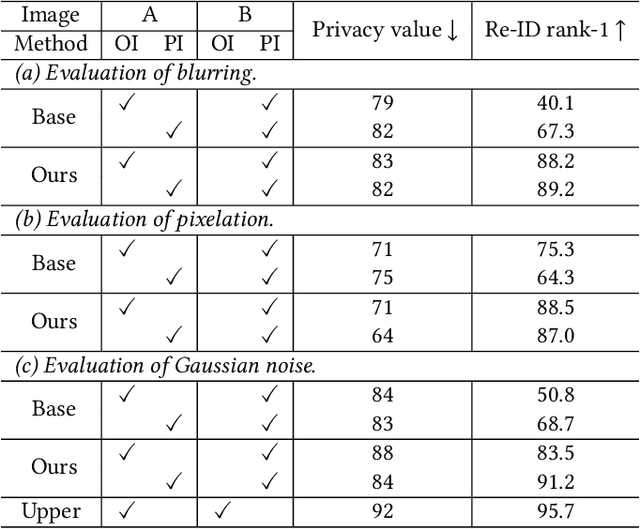
This paper studies a novel privacy-preserving anonymization problem for pedestrian images, which preserves personal identity information (PII) for authorized models and prevents PII from being recognized by third parties. Conventional anonymization methods unavoidably cause semantic information loss, leading to limited data utility. Besides, existing learned anonymization techniques, while retaining various identity-irrelevant utilities, will change the pedestrian identity, and thus are unsuitable for training robust re-identification models. To explore the privacy-utility trade-off for pedestrian images, we propose a joint learning reversible anonymization framework, which can reversibly generate full-body anonymous images with little performance drop on person re-identification tasks. The core idea is that we adopt desensitized images generated by conventional methods as the initial privacy-preserving supervision and jointly train an anonymization encoder with a recovery decoder and an identity-invariant model. We further propose a progressive training strategy to improve the performance, which iteratively upgrades the initial anonymization supervision. Experiments further demonstrate the effectiveness of our anonymized pedestrian images for privacy protection, which boosts the re-identification performance while preserving privacy. Code is available at \url{https://github.com/whuzjw/privacy-reid}.