 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMGS-SLAM: Real-time Multi-sensor Gaussian Splatting SLAM
Apr 14, 2026Real-time 3D Gaussian splatting (3DGS)-based Simultaneous Localization and Mapping (SLAM) in large-scale real-world environments remains challenging, as existing methods often struggle to jointly achieve low-latency pose estimation, 3D Gaussian reconstruction in step with incoming sensor streams, and long-term global consistency. In this paper, we present a tightly coupled LiDAR-Inertial-Visual (LIV) 3DGS-based SLAM framework for real-time pose estimation and photorealistic mapping in large-scale real-world scenes. The system executes state estimation and 3D Gaussian primitive initialization in parallel with global Gaussian optimization, thereby enabling continuous dense mapping. To improve Gaussian initialization quality and accelerate optimization convergence, we introduce a cascaded strategy that combines feed-forward predictions with voxel-based principal component analysis (voxel-PCA) geometric priors. To enhance global consistency in large scenes, we further perform loop closure directly on the optimized global Gaussian map by estimating loop constraints through Gaussian-based Generalized Iterative Closest Point (GICP) registration, followed by pose-graph optimization. In addition, we collected challenging large-scale looped outdoor SLAM sequences with hardware-synchronized LiDAR-camera-IMU and ground-truth trajectories to support realistic and comprehensive evaluation. Extensive experiments on both public datasets and our dataset demonstrate that the proposed method achieves a strong balance among real-time efficiency, localization accuracy, and rendering quality across diverse and challenging real-world scenes.
FD-VLA: Force-Distilled Vision-Language-Action Model for Contact-Rich Manipulation
Feb 02, 2026Force sensing is a crucial modality for Vision-Language-Action (VLA) frameworks, as it enables fine-grained perception and dexterous manipulation in contact-rich tasks. We present Force-Distilled VLA (FD-VLA), a novel framework that integrates force awareness into contact-rich manipulation without relying on physical force sensors. The core of our approach is a Force Distillation Module (FDM), which distills force by mapping a learnable query token, conditioned on visual observations and robot states, into a predicted force token aligned with the latent representation of actual force signals. During inference, this distilled force token is injected into the pretrained VLM, enabling force-aware reasoning while preserving the integrity of its vision-language semantics. This design provides two key benefits: first, it allows practical deployment across a wide range of robots that lack expensive or fragile force-torque sensors, thereby reducing hardware cost and complexity; second, the FDM introduces an additional force-vision-state fusion prior to the VLM, which improves cross-modal alignment and enhances perception-action robustness in contact-rich scenarios. Surprisingly, our physical experiments show that the distilled force token outperforms direct sensor force measurements as well as other baselines, which highlights the effectiveness of this force-distilled VLA approach.
Next Patch Prediction for Autoregressive Visual Generation
Dec 19, 2024Autoregressive models, built based on the Next Token Prediction (NTP) paradigm, show great potential in developing a unified framework that integrates both language and vision tasks. In this work, we rethink the NTP for autoregressive image generation and propose a novel Next Patch Prediction (NPP) paradigm. Our key idea is to group and aggregate image tokens into patch tokens containing high information density. With patch tokens as a shorter input sequence, the autoregressive model is trained to predict the next patch, thereby significantly reducing the computational cost. We further propose a multi-scale coarse-to-fine patch grouping strategy that exploits the natural hierarchical property of image data. Experiments on a diverse range of models (100M-1.4B parameters) demonstrate that the next patch prediction paradigm could reduce the training cost to around 0.6 times while improving image generation quality by up to 1.0 FID score on the ImageNet benchmark. We highlight that our method retains the original autoregressive model architecture without introducing additional trainable parameters or specifically designing a custom image tokenizer, thus ensuring flexibility and seamless adaptation to various autoregressive models for visual generation.
DreamDance: Animating Human Images by Enriching 3D Geometry Cues from 2D Poses
Nov 30, 2024In this work, we present DreamDance, a novel method for animating human images using only skeleton pose sequences as conditional inputs. Existing approaches struggle with generating coherent, high-quality content in an efficient and user-friendly manner. Concretely, baseline methods relying on only 2D pose guidance lack the cues of 3D information, leading to suboptimal results, while methods using 3D representation as guidance achieve higher quality but involve a cumbersome and time-intensive process. To address these limitations, DreamDance enriches 3D geometry cues from 2D poses by introducing an efficient diffusion model, enabling high-quality human image animation with various guidance. Our key insight is that human images naturally exhibit multiple levels of correlation, progressing from coarse skeleton poses to fine-grained geometry cues, and further from these geometry cues to explicit appearance details. Capturing such correlations could enrich the guidance signals, facilitating intra-frame coherency and inter-frame consistency. Specifically, we construct the TikTok-Dance5K dataset, comprising 5K high-quality dance videos with detailed frame annotations, including human pose, depth, and normal maps. Next, we introduce a Mutually Aligned Geometry Diffusion Model to generate fine-grained depth and normal maps for enriched guidance. Finally, a Cross-domain Controller incorporates multi-level guidance to animate human images effectively with a video diffusion model. Extensive experiments demonstrate that our method achieves state-of-the-art performance in animating human images.
Envision3D: One Image to 3D with Anchor Views Interpolation
Mar 13, 2024



We present Envision3D, a novel method for efficiently generating high-quality 3D content from a single image. Recent methods that extract 3D content from multi-view images generated by diffusion models show great potential. However, it is still challenging for diffusion models to generate dense multi-view consistent images, which is crucial for the quality of 3D content extraction. To address this issue, we propose a novel cascade diffusion framework, which decomposes the challenging dense views generation task into two tractable stages, namely anchor views generation and anchor views interpolation. In the first stage, we train the image diffusion model to generate global consistent anchor views conditioning on image-normal pairs. Subsequently, leveraging our video diffusion model fine-tuned on consecutive multi-view images, we conduct interpolation on the previous anchor views to generate extra dense views. This framework yields dense, multi-view consistent images, providing comprehensive 3D information. To further enhance the overall generation quality, we introduce a coarse-to-fine sampling strategy for the reconstruction algorithm to robustly extract textured meshes from the generated dense images. Extensive experiments demonstrate that our method is capable of generating high-quality 3D content in terms of texture and geometry, surpassing previous image-to-3D baseline methods.
Masked Autoencoders for Point Cloud Self-supervised Learning
Mar 28, 2022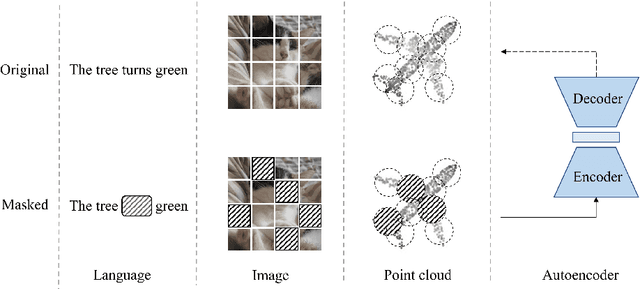
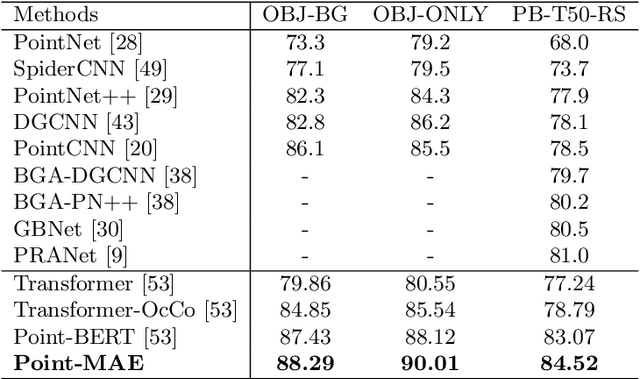
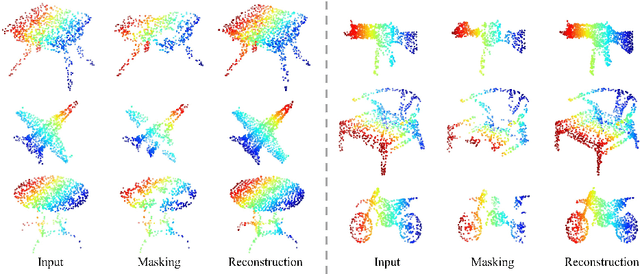
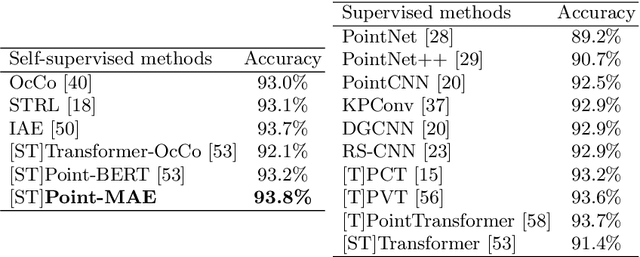
As a promising scheme of self-supervised learning, masked autoencoding has significantly advanced natural language processing and computer vision. Inspired by this, we propose a neat scheme of masked autoencoders for point cloud self-supervised learning, addressing the challenges posed by point cloud's properties, including leakage of location information and uneven information density. Concretely, we divide the input point cloud into irregular point patches and randomly mask them at a high ratio. Then, a standard Transformer based autoencoder, with an asymmetric design and a shifting mask tokens operation, learns high-level latent features from unmasked point patches, aiming to reconstruct the masked point patches. Extensive experiments show that our approach is efficient during pre-training and generalizes well on various downstream tasks. Specifically, our pre-trained models achieve 85.18% accuracy on ScanObjectNN and 94.04% accuracy on ModelNet40, outperforming all the other self-supervised learning methods. We show with our scheme, a simple architecture entirely based on standard Transformers can surpass dedicated Transformer models from supervised learning. Our approach also advances state-of-the-art accuracies by 1.5%-2.3% in the few-shot object classification. Furthermore, our work inspires the feasibility of applying unified architectures from languages and images to the point cloud.
Adversarial images for the primate brain
Nov 11, 2020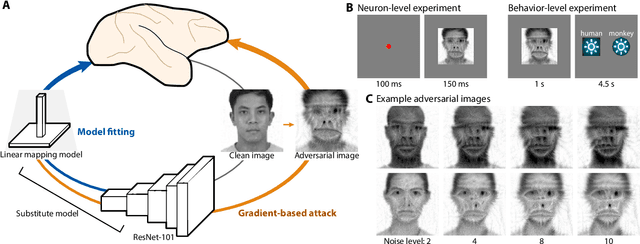
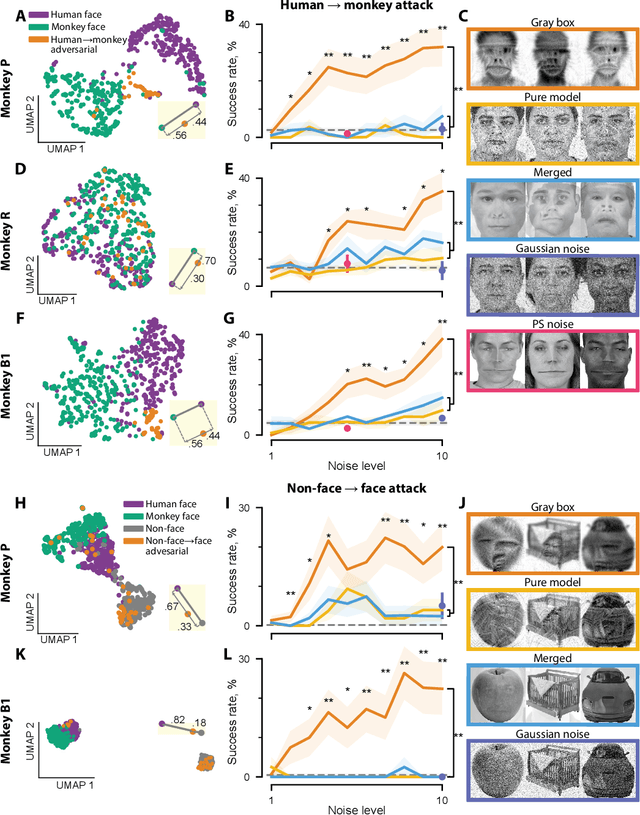
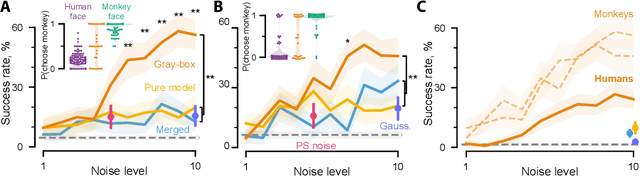
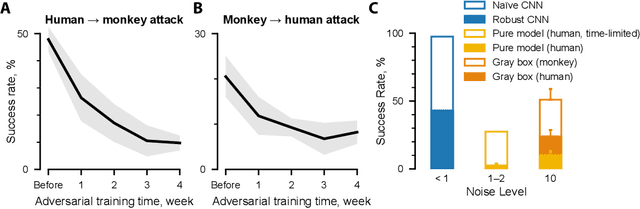
Deep artificial neural networks have been proposed as a model of primate vision. However, these networks are vulnerable to adversarial attacks, whereby introducing minimal noise can fool networks into misclassifying images. Primate vision is thought to be robust to such adversarial images. We evaluated this assumption by designing adversarial images to fool primate vision. To do so, we first trained a model to predict responses of face-selective neurons in macaque inferior temporal cortex. Next, we modified images, such as human faces, to match their model-predicted neuronal responses to a target category, such as monkey faces. These adversarial images elicited neuronal responses similar to the target category. Remarkably, the same images fooled monkeys and humans at the behavioral level. These results challenge fundamental assumptions about the similarity between computer and primate vision and show that a model of neuronal activity can selectively direct primate visual behavior.
A Simple Baseline for Pose Tracking in Videos of Crowded Scenes
Oct 21, 2020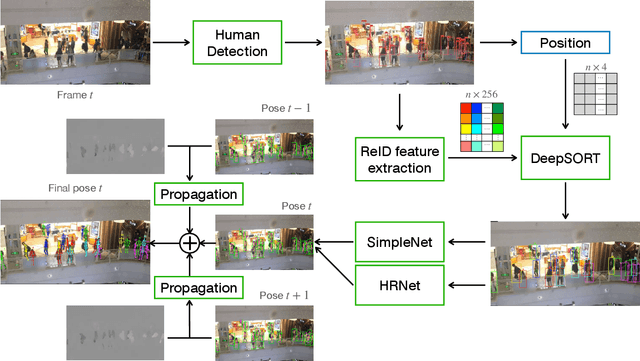
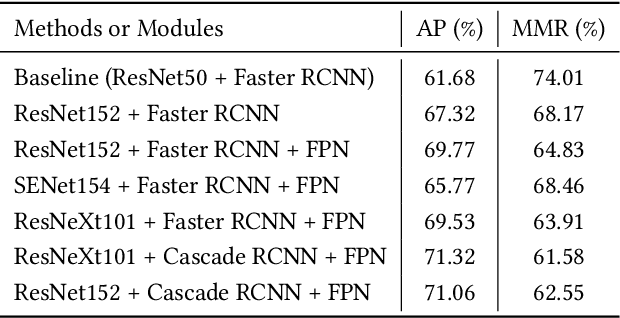
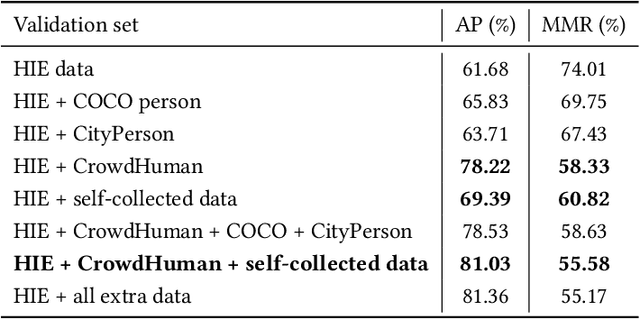

This paper presents our solution to ACM MM challenge: Large-scale Human-centric Video Analysis in Complex Events\cite{lin2020human}; specifically, here we focus on Track3: Crowd Pose Tracking in Complex Events. Remarkable progress has been made in multi-pose training in recent years. However, how to track the human pose in crowded and complex environments has not been well addressed. We formulate the problem as several subproblems to be solved. First, we use a multi-object tracking method to assign human ID to each bounding box generated by the detection model. After that, a pose is generated to each bounding box with ID. At last, optical flow is used to take advantage of the temporal information in the videos and generate the final pose tracking result.
Revisit Knowledge Distillation: a Teacher-free Framework
Sep 25, 2019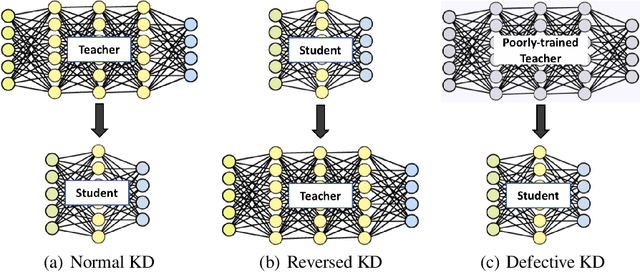

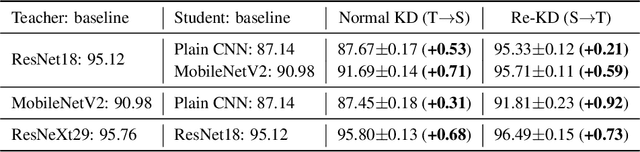
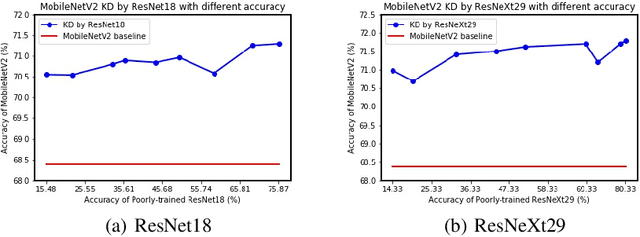
Knowledge Distillation (KD) aims to distill the knowledge of a cumbersome teacher model into a lightweight student model. Its success is generally attributed to the privileged information on similarities among categories provided by the teacher model, and in this sense, only strong teacher models are deployed to teach weaker students in practice. In this work, we challenge this common belief by following experimental observations: 1) beyond the acknowledgment that the teacher can improve the student, the student can also enhance the teacher significantly by reversing the KD procedure; 2) a poorly-trained teacher with much lower accuracy than the student can still improve the latter significantly. To explain these observations, we provide a theoretical analysis of the relationships between KD and label smoothing regularization. We prove that 1) KD is a type of learned label smoothing regularization and 2) label smoothing regularization provides a virtual teacher model for KD. From these results, we argue that the success of KD is not fully due to the similarity information between categories, but also to the regularization of soft targets, which is equally or even more important. Based on these analyses, we further propose a novel Teacher-free Knowledge Distillation (Tf-KD) framework, where a student model learns from itself or manually-designed regularization distribution. The Tf-KD achieves comparable performance with normal KD from a superior teacher, which is well applied when teacher model is unavailable. Meanwhile, Tf-KD is generic and can be directly deployed for training deep neural networks. Without any extra computation cost, Tf-KD achieves up to 0.65\% improvement on ImageNet over well-established baseline models, which is superior to label smoothing regularization. The codes are in: \url{https://github.com/yuanli2333/Teacher-free-Knowledge-Distillation}