 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Generative Denoising with Discriminative Objectives Unleashes Diffusion for Visual Perception
Apr 15, 2025



With the success of image generation, generative diffusion models are increasingly adopted for discriminative tasks, as pixel generation provides a unified perception interface. However, directly repurposing the generative denoising process for discriminative objectives reveals critical gaps rarely addressed previously. Generative models tolerate intermediate sampling errors if the final distribution remains plausible, but discriminative tasks require rigorous accuracy throughout, as evidenced in challenging multi-modal tasks like referring image segmentation. Motivated by this gap, we analyze and enhance alignment between generative diffusion processes and perception tasks, focusing on how perception quality evolves during denoising. We find: (1) earlier denoising steps contribute disproportionately to perception quality, prompting us to propose tailored learning objectives reflecting varying timestep contributions; (2) later denoising steps show unexpected perception degradation, highlighting sensitivity to training-denoising distribution shifts, addressed by our diffusion-tailored data augmentation; and (3) generative processes uniquely enable interactivity, serving as controllable user interfaces adaptable to correctional prompts in multi-round interactions. Our insights significantly improve diffusion-based perception models without architectural changes, achieving state-of-the-art performance on depth estimation, referring image segmentation, and generalist perception tasks. Code available at https://github.com/ziqipang/ADDP.
* ICLR 2025
Improving In-Context Learning with Reasoning Distillation
Apr 14, 2025



Language models rely on semantic priors to perform in-context learning, which leads to poor performance on tasks involving inductive reasoning. Instruction-tuning methods based on imitation learning can superficially enhance the in-context learning performance of language models, but they often fail to improve the model's understanding of the underlying rules that connect inputs and outputs in few-shot demonstrations. We propose ReDis, a reasoning distillation technique designed to improve the inductive reasoning capabilities of language models. Through a careful combination of data augmentation, filtering, supervised fine-tuning, and alignment, ReDis achieves significant performance improvements across a diverse range of tasks, including 1D-ARC, List Function, ACRE, and MiniSCAN. Experiments on three language model backbones show that ReDis outperforms equivalent few-shot prompting baselines across all tasks and even surpasses the teacher model, GPT-4o, in some cases. ReDis, based on the LLaMA-3 backbone, achieves relative improvements of 23.2%, 2.8%, and 66.6% over GPT-4o on 1D-ARC, ACRE, and MiniSCAN, respectively, within a similar hypothesis search space. The code, dataset, and model checkpoints will be made available at https://github.com/NafisSadeq/reasoning-distillation.git.
CheatAgent: Attacking LLM-Empowered Recommender Systems via LLM Agent
Apr 13, 2025Recently, Large Language Model (LLM)-empowered recommender systems (RecSys) have brought significant advances in personalized user experience and have attracted considerable attention. Despite the impressive progress, the research question regarding the safety vulnerability of LLM-empowered RecSys still remains largely under-investigated. Given the security and privacy concerns, it is more practical to focus on attacking the black-box RecSys, where attackers can only observe the system's inputs and outputs. However, traditional attack approaches employing reinforcement learning (RL) agents are not effective for attacking LLM-empowered RecSys due to the limited capabilities in processing complex textual inputs, planning, and reasoning. On the other hand, LLMs provide unprecedented opportunities to serve as attack agents to attack RecSys because of their impressive capability in simulating human-like decision-making processes. Therefore, in this paper, we propose a novel attack framework called CheatAgent by harnessing the human-like capabilities of LLMs, where an LLM-based agent is developed to attack LLM-Empowered RecSys. Specifically, our method first identifies the insertion position for maximum impact with minimal input modification. After that, the LLM agent is designed to generate adversarial perturbations to insert at target positions. To further improve the quality of generated perturbations, we utilize the prompt tuning technique to improve attacking strategies via feedback from the victim RecSys iteratively. Extensive experiments across three real-world datasets demonstrate the effectiveness of our proposed attacking method.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
BiasEdit: Debiasing Stereotyped Language Models via Model Editing
Mar 11, 2025



Previous studies have established that language models manifest stereotyped biases. Existing debiasing strategies, such as retraining a model with counterfactual data, representation projection, and prompting often fail to efficiently eliminate bias or directly alter the models' biased internal representations. To address these issues, we propose BiasEdit, an efficient model editing method to remove stereotypical bias from language models through lightweight networks that act as editors to generate parameter updates. BiasEdit employs a debiasing loss guiding editor networks to conduct local edits on partial parameters of a language model for debiasing while preserving the language modeling abilities during editing through a retention loss. Experiments on StereoSet and Crows-Pairs demonstrate the effectiveness, efficiency, and robustness of BiasEdit in eliminating bias compared to tangental debiasing baselines and little to no impact on the language models' general capabilities. In addition, we conduct bias tracing to probe bias in various modules and explore bias editing impacts on different components of language models.
Multi-Robot System for Cooperative Exploration in Unknown Environments: A Survey
Mar 10, 2025With the advancement of multi-robot technology, cooperative exploration tasks have garnered increasing attention. This paper presents a comprehensive review of multi-robot cooperative exploration systems. First, we review the evolution of robotic exploration and introduce a modular research framework tailored for multi-robot cooperative exploration. Based on this framework, we systematically categorize and summarize key system components. As a foundational module for multi-robot exploration, the localization and mapping module is primarily introduced by focusing on global and relative pose estimation, as well as multi-robot map merging techniques. The cooperative motion module is further divided into learning-based approaches and multi-stage planning, with the latter encompassing target generation, task allocation, and motion planning strategies. Given the communication constraints of real-world environments, we also analyze the communication module, emphasizing how robots exchange information within local communication ranges and under limited transmission capabilities. Finally, we discuss the challenges and future research directions for multi-robot cooperative exploration in light of real-world trends. This review aims to serve as a valuable reference for researchers and practitioners in the field.
MathFimer: Enhancing Mathematical Reasoning by Expanding Reasoning Steps through Fill-in-the-Middle Task
Feb 17, 2025



Mathematical reasoning represents a critical frontier in advancing large language models (LLMs). While step-by-step approaches have emerged as the dominant paradigm for mathematical problem-solving in LLMs, the quality of reasoning steps in training data fundamentally constrains the performance of the models. Recent studies has demonstrated that more detailed intermediate steps can enhance model performance, yet existing methods for step expansion either require more powerful external models or incur substantial computational costs. In this paper, we introduce MathFimer, a novel framework for mathematical reasoning step expansion inspired by the "Fill-in-the-middle" task from code completion. By decomposing solution chains into prefix-suffix pairs and training models to reconstruct missing intermediate steps, we develop a specialized model, MathFimer-7B, on our carefully curated NuminaMath-FIM dataset. We then apply these models to enhance existing mathematical reasoning datasets by inserting detailed intermediate steps into their solution chains, creating MathFimer-expanded versions. Through comprehensive experiments on multiple mathematical reasoning datasets, including MathInstruct, MetaMathQA and etc., we demonstrate that models trained on MathFimer-expanded data consistently outperform their counterparts trained on original data across various benchmarks such as GSM8K and MATH. Our approach offers a practical, scalable solution for enhancing mathematical reasoning capabilities in LLMs without relying on powerful external models or expensive inference procedures.
Teaching LLMs According to Their Aptitude: Adaptive Reasoning for Mathematical Problem Solving
Feb 17, 2025



Existing approaches to mathematical reasoning with large language models (LLMs) rely on Chain-of-Thought (CoT) for generalizability or Tool-Integrated Reasoning (TIR) for precise computation. While efforts have been made to combine these methods, they primarily rely on post-selection or predefined strategies, leaving an open question: whether LLMs can autonomously adapt their reasoning strategy based on their inherent capabilities. In this work, we propose TATA (Teaching LLMs According to Their Aptitude), an adaptive framework that enables LLMs to personalize their reasoning strategy spontaneously, aligning it with their intrinsic aptitude. TATA incorporates base-LLM-aware data selection during supervised fine-tuning (SFT) to tailor training data to the model's unique abilities. This approach equips LLMs to autonomously determine and apply the appropriate reasoning strategy at test time. We evaluate TATA through extensive experiments on six mathematical reasoning benchmarks, using both general-purpose and math-specialized LLMs. Empirical results demonstrate that TATA effectively combines the complementary strengths of CoT and TIR, achieving superior or comparable performance with improved inference efficiency compared to TIR alone. Further analysis underscores the critical role of aptitude-aware data selection in enabling LLMs to make effective and adaptive reasoning decisions and align reasoning strategies with model capabilities.
Skill Expansion and Composition in Parameter Space
Feb 09, 2025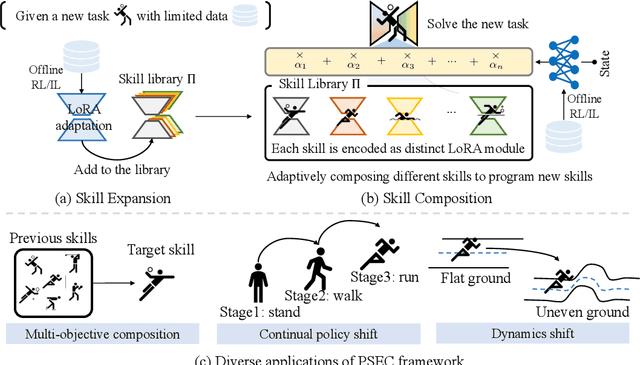
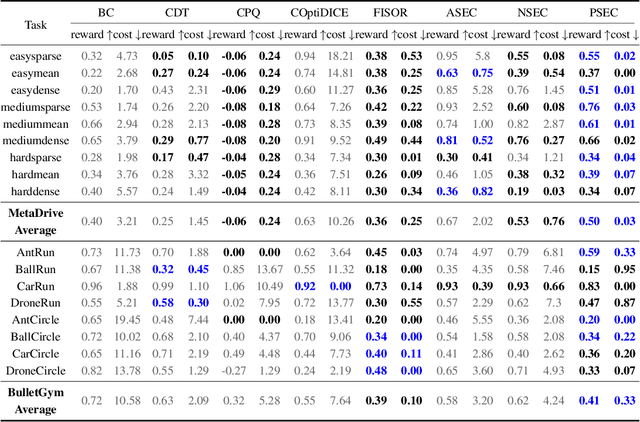
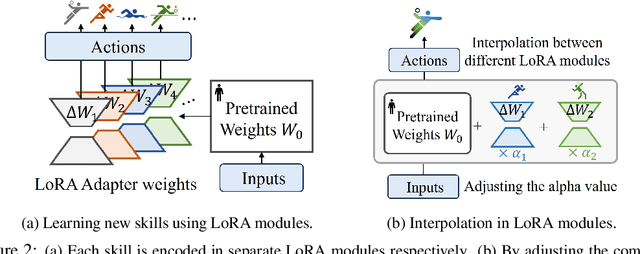
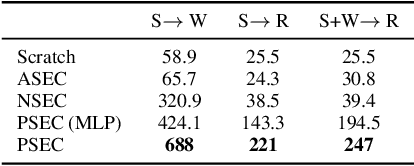
Humans excel at reusing prior knowledge to address new challenges and developing skills while solving problems. This paradigm becomes increasingly popular in the development of autonomous agents, as it develops systems that can self-evolve in response to new challenges like human beings. However, previous methods suffer from limited training efficiency when expanding new skills and fail to fully leverage prior knowledge to facilitate new task learning. In this paper, we propose Parametric Skill Expansion and Composition (PSEC), a new framework designed to iteratively evolve the agents' capabilities and efficiently address new challenges by maintaining a manageable skill library. This library can progressively integrate skill primitives as plug-and-play Low-Rank Adaptation (LoRA) modules in parameter-efficient finetuning, facilitating efficient and flexible skill expansion. This structure also enables the direct skill compositions in parameter space by merging LoRA modules that encode different skills, leveraging shared information across skills to effectively program new skills. Based on this, we propose a context-aware module to dynamically activate different skills to collaboratively handle new tasks. Empowering diverse applications including multi-objective composition, dynamics shift, and continual policy shift, the results on D4RL, DSRL benchmarks, and the DeepMind Control Suite show that PSEC exhibits superior capacity to leverage prior knowledge to efficiently tackle new challenges, as well as expand its skill libraries to evolve the capabilities. Project website: https://ltlhuuu.github.io/PSEC/.
UGMathBench: A Diverse and Dynamic Benchmark for Undergraduate-Level Mathematical Reasoning with Large Language Models
Jan 23, 2025Large Language Models (LLMs) have made significant strides in mathematical reasoning, underscoring the need for a comprehensive and fair evaluation of their capabilities. However, existing benchmarks often fall short, either lacking extensive coverage of undergraduate-level mathematical problems or probably suffering from test-set contamination. To address these issues, we introduce UGMathBench, a diverse and dynamic benchmark specifically designed for evaluating undergraduate-level mathematical reasoning with LLMs. UGMathBench comprises 5,062 problems across 16 subjects and 111 topics, featuring 10 distinct answer types. Each problem includes three randomized versions, with additional versions planned for release as leading open-source LLMs become saturated in UGMathBench. Furthermore, we propose two key metrics: effective accuracy (EAcc), which measures the percentage of correctly solved problems across all three versions, and reasoning gap ($\Delta$), which assesses reasoning robustness by calculating the difference between the average accuracy across all versions and EAcc. Our extensive evaluation of 23 leading LLMs reveals that the highest EAcc achieved is 56.3\% by OpenAI-o1-mini, with large $\Delta$ values observed across different models. This highlights the need for future research aimed at developing "large reasoning models" with high EAcc and $\Delta = 0$. We anticipate that the release of UGMathBench, along with its detailed evaluation codes, will serve as a valuable resource to advance the development of LLMs in solving mathematical problems.
* Accepted to ICLR 2025