 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-MAP: General Memory-Augmented Pre-trained Language Model for Domain Tasks
Dec 08, 2022Recently, domain-specific PLMs have been proposed to boost the task performance of specific domains (e.g., biomedical and computer science) by continuing to pre-train general PLMs with domain-specific corpora. However, this Domain-Adaptive Pre-Training (DAPT; Gururangan et al. (2020)) tends to forget the previous general knowledge acquired by general PLMs, which leads to a catastrophic forgetting phenomenon and sub-optimal performance. To alleviate this problem, we propose a new framework of General Memory Augmented Pre-trained Language Model (G-MAP), which augments the domain-specific PLM by a memory representation built from the frozen general PLM without losing any general knowledge. Specifically, we propose a new memory-augmented layer, and based on it, different augmented strategies are explored to build the memory representation and then adaptively fuse it into the domain-specific PLM. We demonstrate the effectiveness of G-MAP on various domains (biomedical and computer science publications, news, and reviews) and different kinds (text classification, QA, NER) of tasks, and the extensive results show that the proposed G-MAP can achieve SOTA results on all tasks.
KPT: Keyword-guided Pre-training for Grounded Dialog Generation
Dec 04, 2022



Incorporating external knowledge into the response generation process is essential to building more helpful and reliable dialog agents. However, collecting knowledge-grounded conversations is often costly, calling for a better pre-trained model for grounded dialog generation that generalizes well w.r.t. different types of knowledge. In this work, we propose KPT (Keyword-guided Pre-Training), a novel self-supervised pre-training method for grounded dialog generation without relying on extra knowledge annotation. Specifically, we use a pre-trained language model to extract the most uncertain tokens in the dialog as keywords. With these keywords, we construct two kinds of knowledge and pre-train a knowledge-grounded response generation model, aiming at handling two different scenarios: (1) the knowledge should be faithfully grounded; (2) it can be selectively used. For the former, the grounding knowledge consists of keywords extracted from the response. For the latter, the grounding knowledge is additionally augmented with keywords extracted from other utterances in the same dialog. Since the knowledge is extracted from the dialog itself, KPT can be easily performed on a large volume and variety of dialogue data. We considered three data sources (open-domain, task-oriented, conversational QA) with a total of 2.5M dialogues. We conduct extensive experiments on various few-shot knowledge-grounded generation tasks, including grounding on dialog acts, knowledge graphs, persona descriptions, and Wikipedia passages. Our comprehensive experiments and analyses demonstrate that KPT consistently outperforms state-of-the-art methods on these tasks with diverse grounding knowledge.
Lexicon-injected Semantic Parsing for Task-Oriented Dialog
Nov 26, 2022



Recently, semantic parsing using hierarchical representations for dialog systems has captured substantial attention. Task-Oriented Parse (TOP), a tree representation with intents and slots as labels of nested tree nodes, has been proposed for parsing user utterances. Previous TOP parsing methods are limited on tackling unseen dynamic slot values (e.g., new songs and locations added), which is an urgent matter for real dialog systems. To mitigate this issue, we first propose a novel span-splitting representation for span-based parser that outperforms existing methods. Then we present a novel lexicon-injected semantic parser, which collects slot labels of tree representation as a lexicon, and injects lexical features to the span representation of parser. An additional slot disambiguation technique is involved to remove inappropriate span match occurrences from the lexicon. Our best parser produces a new state-of-the-art result (87.62%) on the TOP dataset, and demonstrates its adaptability to frequently updated slot lexicon entries in real task-oriented dialog, with no need of retraining.
Label Mask AutoEncoder(L-MAE): A Pure Transformer Method to Augment Semantic Segmentation Datasets
Nov 21, 2022



Semantic segmentation models based on the conventional neural network can achieve remarkable performance in such tasks, while the dataset is crucial to the training model process. Significant progress in expanding datasets has been made in semi-supervised semantic segmentation recently. However, completing the pixel-level information remains challenging due to possible missing in a label. Inspired by Mask AutoEncoder, we present a simple yet effective Pixel-Level completion method, Label Mask AutoEncoder(L-MAE), that fully uses the existing information in the label to predict results. The proposed model adopts the fusion strategy that stacks the label and the corresponding image, namely Fuse Map. Moreover, since some of the image information is lost when masking the Fuse Map, direct reconstruction may lead to poor performance. Our proposed Image Patch Supplement algorithm can supplement the missing information, as the experiment shows, an average of 4.1% mIoU can be improved. The Pascal VOC2012 dataset (224 crop size, 20 classes) and the Cityscape dataset (448 crop size, 19 classes) are used in the comparative experiments. With the Mask Ratio setting to 50%, in terms of the prediction region, the proposed model achieves 91.0% and 86.4% of mIoU on Pascal VOC 2012 and Cityscape, respectively, outperforming other current supervised semantic segmentation models. Our code and models are available at https://github.com/jjrccop/Label-Mask-Auto-Encoder.
Pre-training Language Models with Deterministic Factual Knowledge
Oct 20, 2022
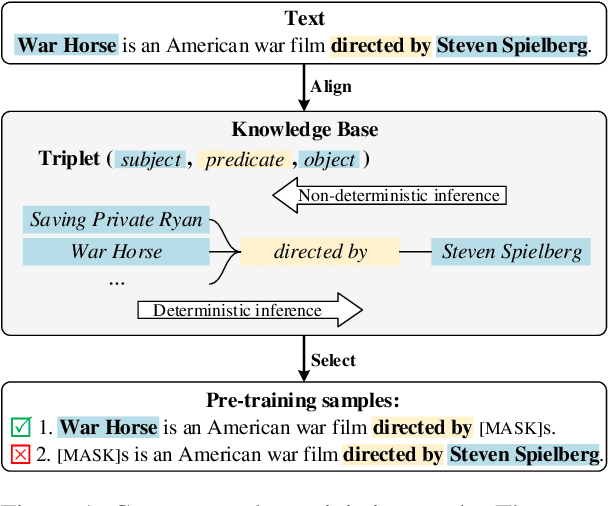

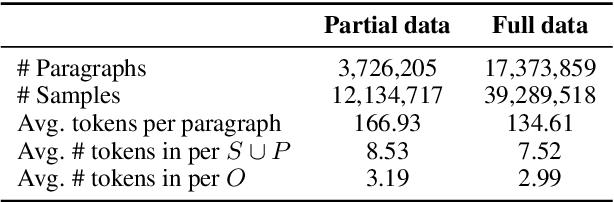
Previous works show that Pre-trained Language Models (PLMs) can capture factual knowledge. However, some analyses reveal that PLMs fail to perform it robustly, e.g., being sensitive to the changes of prompts when extracting factual knowledge. To mitigate this issue, we propose to let PLMs learn the deterministic relationship between the remaining context and the masked content. The deterministic relationship ensures that the masked factual content can be deterministically inferable based on the existing clues in the context. That would provide more stable patterns for PLMs to capture factual knowledge than randomly masking. Two pre-training tasks are further introduced to motivate PLMs to rely on the deterministic relationship when filling masks. Specifically, we use an external Knowledge Base (KB) to identify deterministic relationships and continuously pre-train PLMs with the proposed methods. The factual knowledge probing experiments indicate that the continuously pre-trained PLMs achieve better robustness in factual knowledge capturing. Further experiments on question-answering datasets show that trying to learn a deterministic relationship with the proposed methods can also help other knowledge-intensive tasks.
PanGu-Coder: Program Synthesis with Function-Level Language Modeling
Jul 22, 2022
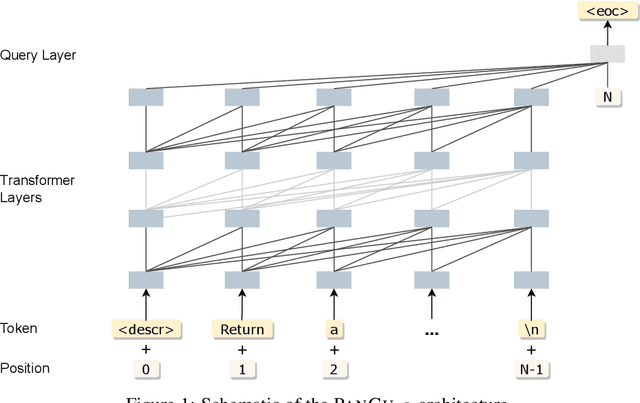
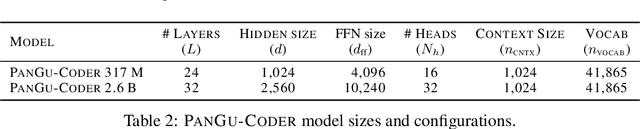
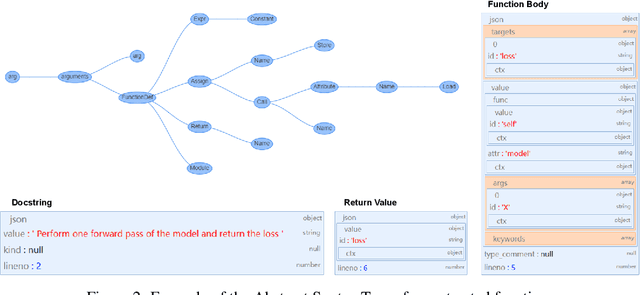
We present PanGu-Coder, a pretrained decoder-only language model adopting the PanGu-Alpha architecture for text-to-code generation, i.e. the synthesis of programming language solutions given a natural language problem description. We train PanGu-Coder using a two-stage strategy: the first stage employs Causal Language Modelling (CLM) to pre-train on raw programming language data, while the second stage uses a combination of Causal Language Modelling and Masked Language Modelling (MLM) training objectives that focus on the downstream task of text-to-code generation and train on loosely curated pairs of natural language program definitions and code functions. Finally, we discuss PanGu-Coder-FT, which is fine-tuned on a combination of competitive programming problems and code with continuous integration tests. We evaluate PanGu-Coder with a focus on whether it generates functionally correct programs and demonstrate that it achieves equivalent or better performance than similarly sized models, such as CodeX, while attending a smaller context window and training on less data.
Boosting Graph Structure Learning with Dummy Nodes
Jun 17, 2022
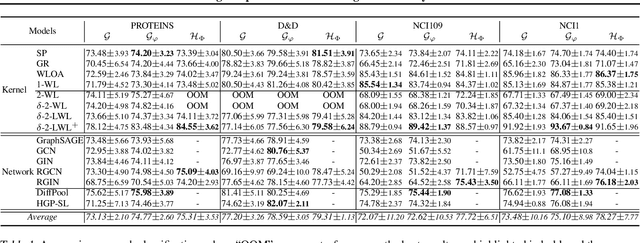
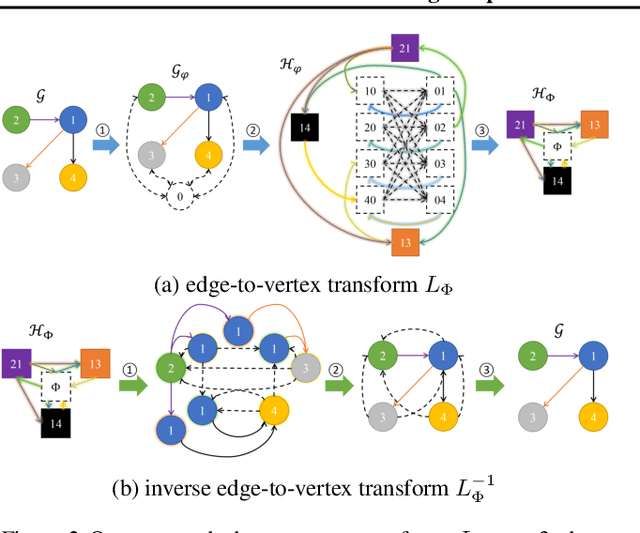
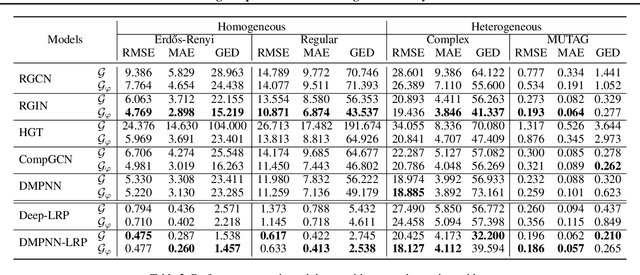
With the development of graph kernels and graph representation learning, many superior methods have been proposed to handle scalability and oversmoothing issues on graph structure learning. However, most of those strategies are designed based on practical experience rather than theoretical analysis. In this paper, we use a particular dummy node connecting to all existing vertices without affecting original vertex and edge properties. We further prove that such the dummy node can help build an efficient monomorphic edge-to-vertex transform and an epimorphic inverse to recover the original graph back. It also indicates that adding dummy nodes can preserve local and global structures for better graph representation learning. We extend graph kernels and graph neural networks with dummy nodes and conduct experiments on graph classification and subgraph isomorphism matching tasks. Empirical results demonstrate that taking graphs with dummy nodes as input significantly boosts graph structure learning, and using their edge-to-vertex graphs can also achieve similar results. We also discuss the gain of expressive power from the dummy in neural networks.
FreeTransfer-X: Safe and Label-Free Cross-Lingual Transfer from Off-the-Shelf Models
Jun 14, 2022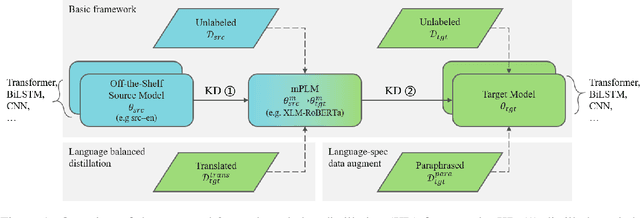
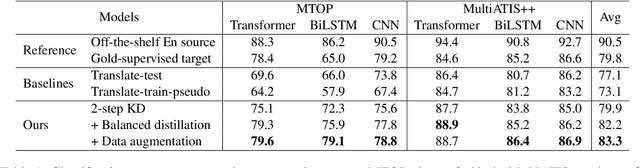
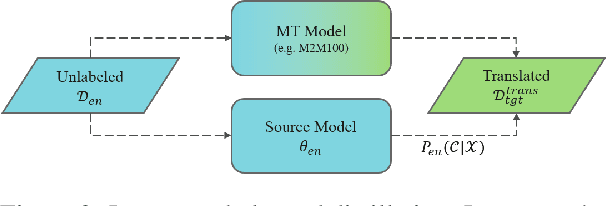
Cross-lingual transfer (CLT) is of various applications. However, labeled cross-lingual corpus is expensive or even inaccessible, especially in the fields where labels are private, such as diagnostic results of symptoms in medicine and user profiles in business. Nevertheless, there are off-the-shelf models in these sensitive fields. Instead of pursuing the original labels, a workaround for CLT is to transfer knowledge from the off-the-shelf models without labels. To this end, we define a novel CLT problem named FreeTransfer-X that aims to achieve knowledge transfer from the off-the-shelf models in rich-resource languages. To address the problem, we propose a 2-step knowledge distillation (KD, Hinton et al., 2015) framework based on multilingual pre-trained language models (mPLM). The significant improvement over strong neural machine translation (NMT) baselines demonstrates the effectiveness of the proposed method. In addition to reducing annotation cost and protecting private labels, the proposed method is compatible with different networks and easy to be deployed. Finally, a range of analyses indicate the great potential of the proposed method.
Deeper vs Wider: A Revisit of Transformer Configuration
May 24, 2022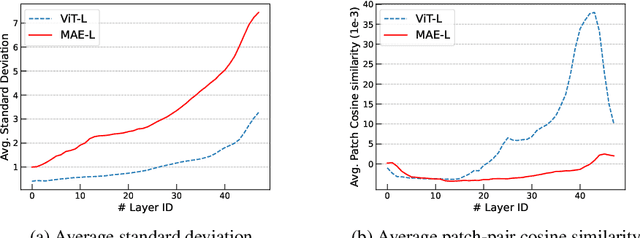
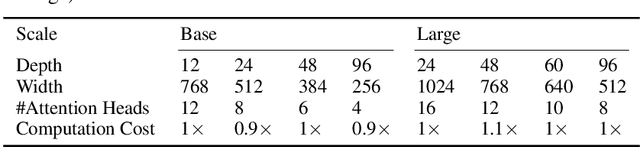
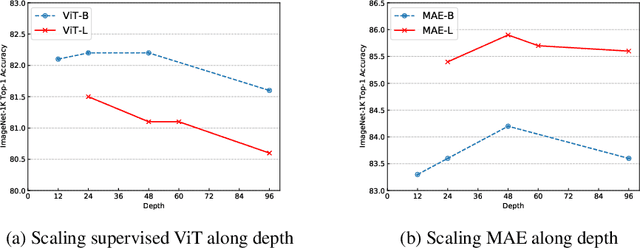

Transformer-based models have delivered impressive results on many tasks, particularly vision and language tasks. In many model training situations, conventional configurations are typically adopted. For example, we often set the base model with hidden dimensions (i.e. model width) to be 768 and the number of transformer layers (i.e. model depth) to be 12. In this paper, we revisit these conventional configurations. Through theoretical analysis and experimental evaluation, we show that the masked autoencoder is effective in alleviating the over-smoothing issue in deep transformer training. Based on this finding, we propose Bamboo, an idea of using deeper and narrower transformer configurations, for masked autoencoder training. On ImageNet, with such a simple change in configuration, re-designed model achieves 87.1% top-1 accuracy and outperforms SoTA models like MAE and BEiT. On language tasks, re-designed model outperforms BERT with default setting by 1.1 points on average, on GLUE datasets.
PERT: A New Solution to Pinyin to Character Conversion Task
May 24, 2022
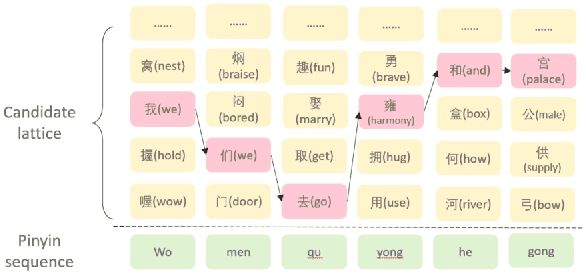
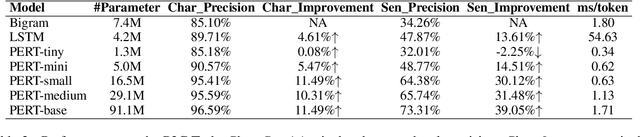
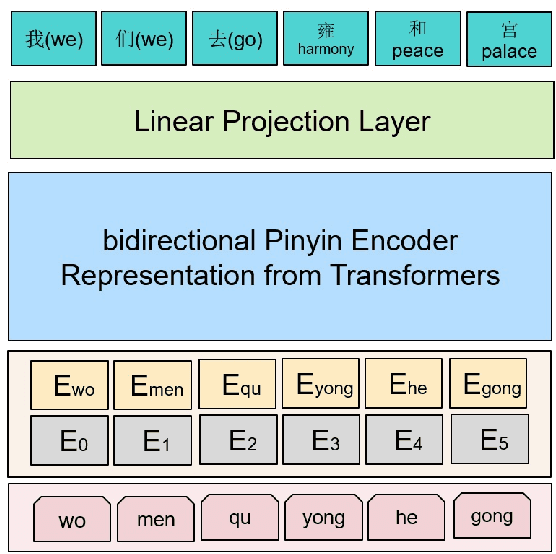
Pinyin to Character conversion (P2C) task is the key task of Input Method Engine (IME) in commercial input software for Asian languages, such as Chinese, Japanese, Thai language and so on. It's usually treated as sequence labelling task and resolved by language model, i.e. n-gram or RNN. However, the low capacity of the n-gram or RNN limits its performance. This paper introduces a new solution named PERT which stands for bidirectional Pinyin Encoder Representations from Transformers. It achieves significant improvement of performance over baselines. Furthermore, we combine PERT with n-gram under a Markov framework, and improve performance further. Lastly, the external lexicon is incorporated into PERT so as to resolve the OOD issue of IME.