 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAP-CAP: Advancing High-Quality Data Synthesis for Animal Pose Estimation via a Controllable Image Generation Pipeline
Apr 01, 2025The task of 2D animal pose estimation plays a crucial role in advancing deep learning applications in animal behavior analysis and ecological research. Despite notable progress in some existing approaches, our study reveals that the scarcity of high-quality datasets remains a significant bottleneck, limiting the full potential of current methods. To address this challenge, we propose a novel Controllable Image Generation Pipeline for synthesizing animal pose estimation data, termed AP-CAP. Within this pipeline, we introduce a Multi-Modal Animal Image Generation Model capable of producing images with expected poses. To enhance the quality and diversity of the generated data, we further propose three innovative strategies: (1) Modality-Fusion-Based Animal Image Synthesis Strategy to integrate multi-source appearance representations, (2) Pose-Adjustment-Based Animal Image Synthesis Strategy to dynamically capture diverse pose variations, and (3) Caption-Enhancement-Based Animal Image Synthesis Strategy to enrich visual semantic understanding. Leveraging the proposed model and strategies, we create the MPCH Dataset (Modality-Pose-Caption Hybrid), the first hybrid dataset that innovatively combines synthetic and real data, establishing the largest-scale multi-source heterogeneous benchmark repository for animal pose estimation to date. Extensive experiments demonstrate the superiority of our method in improving both the performance and generalization capability of animal pose estimators.
TASR: Timestep-Aware Diffusion Model for Image Super-Resolution
Dec 04, 2024Diffusion models have recently achieved outstanding results in the field of image super-resolution. These methods typically inject low-resolution (LR) images via ControlNet.In this paper, we first explore the temporal dynamics of information infusion through ControlNet, revealing that the input from LR images predominantly influences the initial stages of the denoising process. Leveraging this insight, we introduce a novel timestep-aware diffusion model that adaptively integrates features from both ControlNet and the pre-trained Stable Diffusion (SD). Our method enhances the transmission of LR information in the early stages of diffusion to guarantee image fidelity and stimulates the generation ability of the SD model itself more in the later stages to enhance the detail of generated images. To train this method, we propose a timestep-aware training strategy that adopts distinct losses at varying timesteps and acts on disparate modules. Experiments on benchmark datasets demonstrate the effectiveness of our method. Code: https://github.com/SleepyLin/TASR
RFSR: Improving ISR Diffusion Models via Reward Feedback Learning
Dec 04, 2024Generative diffusion models (DM) have been extensively utilized in image super-resolution (ISR). Most of the existing methods adopt the denoising loss from DDPMs for model optimization. We posit that introducing reward feedback learning to finetune the existing models can further improve the quality of the generated images. In this paper, we propose a timestep-aware training strategy with reward feedback learning. Specifically, in the initial denoising stages of ISR diffusion, we apply low-frequency constraints to super-resolution (SR) images to maintain structural stability. In the later denoising stages, we use reward feedback learning to improve the perceptual and aesthetic quality of the SR images. In addition, we incorporate Gram-KL regularization to alleviate stylization caused by reward hacking. Our method can be integrated into any diffusion-based ISR model in a plug-and-play manner. Experiments show that ISR diffusion models, when fine-tuned with our method, significantly improve the perceptual and aesthetic quality of SR images, achieving excellent subjective results. Code: https://github.com/sxpro/RFSR
360-Degree Video Super Resolution and Quality Enhancement Challenge: Methods and Results
Nov 11, 2024Omnidirectional (360-degree) video is rapidly gaining popularity due to advancements in immersive technologies like virtual reality (VR) and extended reality (XR). However, real-time streaming of such videos, especially in live mobile scenarios like unmanned aerial vehicles (UAVs), is challenged by limited bandwidth and strict latency constraints. Traditional methods, such as compression and adaptive resolution, help but often compromise video quality and introduce artifacts that degrade the viewer experience. Additionally, the unique spherical geometry of 360-degree video presents challenges not encountered in traditional 2D video. To address these issues, we initiated the 360-degree Video Super Resolution and Quality Enhancement Challenge. This competition encourages participants to develop efficient machine learning solutions to enhance the quality of low-bitrate compressed 360-degree videos, with two tracks focusing on 2x and 4x super-resolution (SR). In this paper, we outline the challenge framework, detailing the two competition tracks and highlighting the SR solutions proposed by the top-performing models. We assess these models within a unified framework, considering quality enhancement, bitrate gain, and computational efficiency. This challenge aims to drive innovation in real-time 360-degree video streaming, improving the quality and accessibility of immersive visual experiences.
Matten: Video Generation with Mamba-Attention
May 05, 2024In this paper, we introduce Matten, a cutting-edge latent diffusion model with Mamba-Attention architecture for video generation. With minimal computational cost, Matten employs spatial-temporal attention for local video content modeling and bidirectional Mamba for global video content modeling. Our comprehensive experimental evaluation demonstrates that Matten has competitive performance with the current Transformer-based and GAN-based models in benchmark performance, achieving superior FVD scores and efficiency. Additionally, we observe a direct positive correlation between the complexity of our designed model and the improvement in video quality, indicating the excellent scalability of Matten.
NTIRE 2024 Challenge on Low Light Image Enhancement: Methods and Results
Apr 22, 2024



This paper reviews the NTIRE 2024 low light image enhancement challenge, highlighting the proposed solutions and results. The aim of this challenge is to discover an effective network design or solution capable of generating brighter, clearer, and visually appealing results when dealing with a variety of conditions, including ultra-high resolution (4K and beyond), non-uniform illumination, backlighting, extreme darkness, and night scenes. A notable total of 428 participants registered for the challenge, with 22 teams ultimately making valid submissions. This paper meticulously evaluates the state-of-the-art advancements in enhancing low-light images, reflecting the significant progress and creativity in this field.
Hybrid Transformer and CNN Attention Network for Stereo Image Super-resolution
May 09, 2023Multi-stage strategies are frequently employed in image restoration tasks. While transformer-based methods have exhibited high efficiency in single-image super-resolution tasks, they have not yet shown significant advantages over CNN-based methods in stereo super-resolution tasks. This can be attributed to two key factors: first, current single-image super-resolution transformers are unable to leverage the complementary stereo information during the process; second, the performance of transformers is typically reliant on sufficient data, which is absent in common stereo-image super-resolution algorithms. To address these issues, we propose a Hybrid Transformer and CNN Attention Network (HTCAN), which utilizes a transformer-based network for single-image enhancement and a CNN-based network for stereo information fusion. Furthermore, we employ a multi-patch training strategy and larger window sizes to activate more input pixels for super-resolution. We also revisit other advanced techniques, such as data augmentation, data ensemble, and model ensemble to reduce overfitting and data bias. Finally, our approach achieved a score of 23.90dB and emerged as the winner in Track 1 of the NTIRE 2023 Stereo Image Super-Resolution Challenge.
OPDN: Omnidirectional Position-aware Deformable Network for Omnidirectional Image Super-Resolution
Apr 26, 2023



360{\deg} omnidirectional images have gained research attention due to their immersive and interactive experience, particularly in AR/VR applications. However, they suffer from lower angular resolution due to being captured by fisheye lenses with the same sensor size for capturing planar images. To solve the above issues, we propose a two-stage framework for 360{\deg} omnidirectional image superresolution. The first stage employs two branches: model A, which incorporates omnidirectional position-aware deformable blocks (OPDB) and Fourier upsampling, and model B, which adds a spatial frequency fusion module (SFF) to model A. Model A aims to enhance the feature extraction ability of 360{\deg} image positional information, while Model B further focuses on the high-frequency information of 360{\deg} images. The second stage performs same-resolution enhancement based on the structure of model A with a pixel unshuffle operation. In addition, we collected data from YouTube to improve the fitting ability of the transformer, and created pseudo low-resolution images using a degradation network. Our proposed method achieves superior performance and wins the NTIRE 2023 challenge of 360{\deg} omnidirectional image super-resolution.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022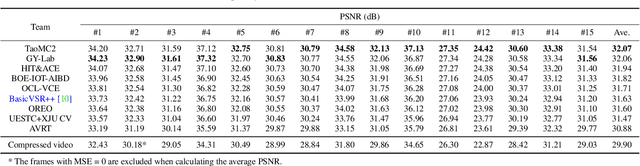
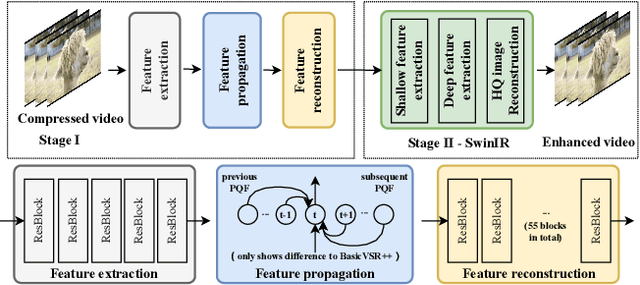
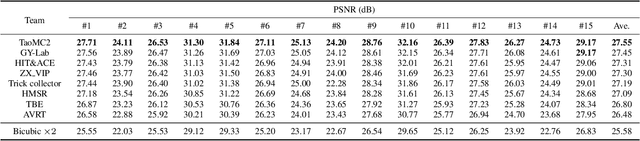

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
Enhance Images as You Like with Unpaired Learning
Oct 04, 2021

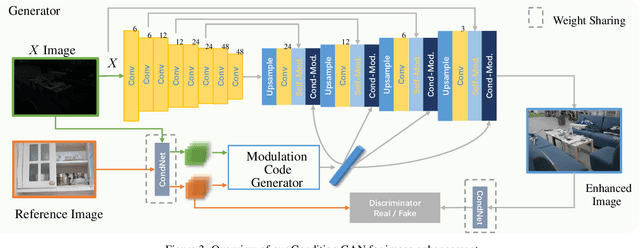
Low-light image enhancement exhibits an ill-posed nature, as a given image may have many enhanced versions, yet recent studies focus on building a deterministic mapping from input to an enhanced version. In contrast, we propose a lightweight one-path conditional generative adversarial network (cGAN) to learn a one-to-many relation from low-light to normal-light image space, given only sets of low- and normal-light training images without any correspondence. By formulating this ill-posed problem as a modulation code learning task, our network learns to generate a collection of enhanced images from a given input conditioned on various reference images. Therefore our inference model easily adapts to various user preferences, provided with a few favorable photos from each user. Our model achieves competitive visual and quantitative results on par with fully supervised methods on both noisy and clean datasets, while being 6 to 10 times lighter than state-of-the-art generative adversarial networks (GANs) approaches.