 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTukaBench: A Culturally Grounded Jailbreak Benchmark for African Languages
May 31, 2026Safety evaluation of Large Language Models (LLMs) remains heavily English-centric, leaving Low-Resource Languages (LRLs), particularly African ones, critically underexplored. We introduce TUKABENCH, a jailbreak benchmark for seven African languages that extends JailbreakBench (JBB) beyond direct translation through four settings: human translation of JBB prompts, English adaptation to African contexts followed by human translation, human-curated prompts validated through interactions with GPT-5.2, and code-switched prompts combining English and African languages, isolating the effect of language, cultural grounding, and prompt evasiveness on model safety. Across closed and open models, prompting in African languages reduces refusal relative to English, with culturally adapted prompts leading to least refusal. The evaluation also surfaces two structural limitations: model comprehension failures and reduced LLM-as-a-judge reliability in LRLs. To capture the first, we introduce Deflection alongside Refused and Jailbroken; to assess the second, we validate outputs with human annotations, showing that judge-human agreement drops in lower-resource languages and less commonly supported scripts.
Can Visual Mamba Improve AI-Generated Image Detection? An In-Depth Investigation
May 14, 2026In recent years, computer vision has witnessed remarkable progress, fueled by the development of innovative architectures such as Convolutional Neural Networks (CNNs), Generative Adversarial Networks (GANs), diffusion-based architectures, Vision Transformers (ViTs), and, more recently, Vision-Language Models (VLMs). This progress has undeniably contributed to creating increasingly realistic and diverse visual content. However, such advancements in image generation also raise concerns about potential misuse in areas such as misinformation, identity theft, and threats to privacy and security. In parallel, Mamba-based architectures have emerged as versatile tools for a range of image analysis tasks, including classification, segmentation, medical imaging, object detection, and image restoration, in this rapidly evolving field. However, their potential for identifying AI-generated images remains relatively unexplored compared to established techniques. This study provides a systematic evaluation and comparative analysis of Vision Mamba models for AI-generated image detection. We benchmark multiple Vision Mamba variants against representative CNNs, ViTs, and VLM-based detectors across diverse datasets and synthetic image sources, focusing on key metrics such as accuracy, efficiency, and generalizability across diverse image types and generative models. Through this comprehensive analysis, we aim to elucidate Vision Mamba's strengths and limitations relative to established methodologies in terms of applicability, accuracy, and efficiency in detecting AI-generated images. Overall, our findings highlight both the promise and current limitations of Vision Mamba as a component in systems designed to distinguish authentic from AI-generated visual content. This research is crucial for enhancing detection in an age where distinguishing between real and AI-generated content is a major challenge.
BYOL: Bring Your Own Language Into LLMs
Jan 15, 2026Large Language Models (LLMs) exhibit strong multilingual capabilities, yet remain fundamentally constrained by the severe imbalance in global language resources. While over 7,000 languages are spoken worldwide, only a small subset (fewer than 100) has sufficient digital presence to meaningfully influence modern LLM training. This disparity leads to systematic underperformance, cultural misalignment, and limited accessibility for speakers of low-resource and extreme-low-resource languages. To address this gap, we introduce Bring Your Own Language (BYOL), a unified framework for scalable, language-aware LLM development tailored to each language's digital footprint. BYOL begins with a language resource classification that maps languages into four tiers (Extreme-Low, Low, Mid, High) using curated web-scale corpora, and uses this classification to select the appropriate integration pathway. For low-resource languages, we propose a full-stack data refinement and expansion pipeline that combines corpus cleaning, synthetic text generation, continual pretraining, and supervised finetuning. Applied to Chichewa and Maori, this pipeline yields language-specific LLMs that achieve approximately 12 percent average improvement over strong multilingual baselines across 12 benchmarks, while preserving English and multilingual capabilities via weight-space model merging. For extreme-low-resource languages, we introduce a translation-mediated inclusion pathway, and show on Inuktitut that a tailored machine translation system improves over a commercial baseline by 4 BLEU, enabling high-accuracy LLM access when direct language modeling is infeasible. Finally, we release human-translated versions of the Global MMLU-Lite benchmark in Chichewa, Maori, and Inuktitut, and make our codebase and models publicly available at https://github.com/microsoft/byol .
AfriqueLLM: How Data Mixing and Model Architecture Impact Continued Pre-training for African Languages
Jan 10, 2026Large language models (LLMs) are increasingly multilingual, yet open models continue to underperform relative to proprietary systems, with the gap most pronounced for African languages. Continued pre-training (CPT) offers a practical route to language adaptation, but improvements on demanding capabilities such as mathematical reasoning often remain limited. This limitation is driven in part by the uneven domain coverage and missing task-relevant knowledge that characterize many low-resource language corpora. We present \texttt{AfriqueLLM}, a suite of open LLMs adapted to 20 African languages through CPT on 26B tokens. We perform a comprehensive empirical study across five base models spanning sizes and architectures, including Llama 3.1, Gemma 3, and Qwen 3, and systematically analyze how CPT data composition shapes downstream performance. In particular, we vary mixtures that include math, code, and synthetic translated data, and evaluate the resulting models on a range of multilingual benchmarks. Our results identify data composition as the primary driver of CPT gains. Adding math, code, and synthetic translated data yields consistent improvements, including on reasoning-oriented evaluations. Within a fixed architecture, larger models typically improve performance, but architectural choices dominate scale when comparing across model families. Moreover, strong multilingual performance in the base model does not reliably predict post-CPT outcomes; robust architectures coupled with task-aligned data provide a more dependable recipe. Finally, our best models improve long-context performance, including document-level translation. Models have been released on [Huggingface](https://huggingface.co/collections/McGill-NLP/afriquellm).
Designing Object Detection Models for TinyML: Foundations, Comparative Analysis, Challenges, and Emerging Solutions
Aug 11, 2025



Object detection (OD) has become vital for numerous computer vision applications, but deploying it on resource-constrained IoT devices presents a significant challenge. These devices, often powered by energy-efficient microcontrollers, struggle to handle the computational load of deep learning-based OD models. This issue is compounded by the rapid proliferation of IoT devices, predicted to surpass 150 billion by 2030. TinyML offers a compelling solution by enabling OD on ultra-low-power devices, paving the way for efficient and real-time processing at the edge. Although numerous survey papers have been published on this topic, they often overlook the optimization challenges associated with deploying OD models in TinyML environments. To address this gap, this survey paper provides a detailed analysis of key optimization techniques for deploying OD models on resource-constrained devices. These techniques include quantization, pruning, knowledge distillation, and neural architecture search. Furthermore, we explore both theoretical approaches and practical implementations, bridging the gap between academic research and real-world edge artificial intelligence deployment. Finally, we compare the key performance indicators (KPIs) of existing OD implementations on microcontroller devices, highlighting the achieved maturity level of these solutions in terms of both prediction accuracy and efficiency. We also provide a public repository to continually track developments in this fast-evolving field: https://github.com/christophezei/Optimizing-Object-Detection-Models-for-TinyML-A-Comprehensive-Survey.
RAVID: Retrieval-Augmented Visual Detection: A Knowledge-Driven Approach for AI-Generated Image Identification
Aug 05, 2025In this paper, we introduce RAVID, the first framework for AI-generated image detection that leverages visual retrieval-augmented generation (RAG). While RAG methods have shown promise in mitigating factual inaccuracies in foundation models, they have primarily focused on text, leaving visual knowledge underexplored. Meanwhile, existing detection methods, which struggle with generalization and robustness, often rely on low-level artifacts and model-specific features, limiting their adaptability. To address this, RAVID dynamically retrieves relevant images to enhance detection. Our approach utilizes a fine-tuned CLIP image encoder, RAVID CLIP, enhanced with category-related prompts to improve representation learning. We further integrate a vision-language model (VLM) to fuse retrieved images with the query, enriching the input and improving accuracy. Given a query image, RAVID generates an embedding using RAVID CLIP, retrieves the most relevant images from a database, and combines these with the query image to form an enriched input for a VLM (e.g., Qwen-VL or Openflamingo). Experiments on the UniversalFakeDetect benchmark, which covers 19 generative models, show that RAVID achieves state-of-the-art performance with an average accuracy of 93.85%. RAVID also outperforms traditional methods in terms of robustness, maintaining high accuracy even under image degradations such as Gaussian blur and JPEG compression. Specifically, RAVID achieves an average accuracy of 80.27% under degradation conditions, compared to 63.44% for the state-of-the-art model C2P-CLIP, demonstrating consistent improvements in both Gaussian blur and JPEG compression scenarios. The code will be publicly available upon acceptance.
DeeCLIP: A Robust and Generalizable Transformer-Based Framework for Detecting AI-Generated Images
Apr 28, 2025This paper introduces DeeCLIP, a novel framework for detecting AI-generated images using CLIP-ViT and fusion learning. Despite significant advancements in generative models capable of creating highly photorealistic images, existing detection methods often struggle to generalize across different models and are highly sensitive to minor perturbations. To address these challenges, DeeCLIP incorporates DeeFuser, a fusion module that combines high-level and low-level features, improving robustness against degradations such as compression and blurring. Additionally, we apply triplet loss to refine the embedding space, enhancing the model's ability to distinguish between real and synthetic content. To further enable lightweight adaptation while preserving pre-trained knowledge, we adopt parameter-efficient fine-tuning using low-rank adaptation (LoRA) within the CLIP-ViT backbone. This approach supports effective zero-shot learning without sacrificing generalization. Trained exclusively on 4-class ProGAN data, DeeCLIP achieves an average accuracy of 89.00% on 19 test subsets composed of generative adversarial network (GAN) and diffusion models. Despite having fewer trainable parameters, DeeCLIP outperforms existing methods, demonstrating superior robustness against various generative models and real-world distortions. The code is publicly available at https://github.com/Mamadou-Keita/DeeCLIP for research purposes.
Can LLMs Revolutionize the Design of Explainable and Efficient TinyML Models?
Apr 13, 2025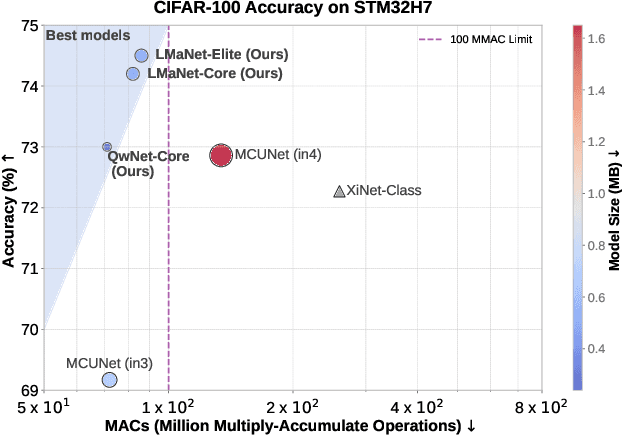

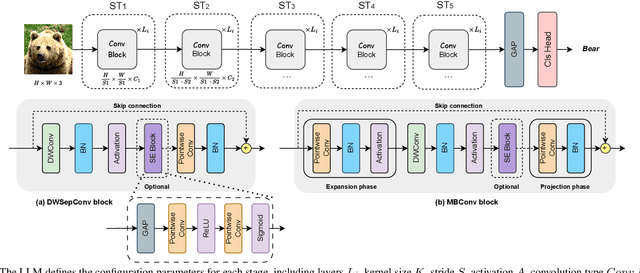

This paper introduces a novel framework for designing efficient neural network architectures specifically tailored to tiny machine learning (TinyML) platforms. By leveraging large language models (LLMs) for neural architecture search (NAS), a vision transformer (ViT)-based knowledge distillation (KD) strategy, and an explainability module, the approach strikes an optimal balance between accuracy, computational efficiency, and memory usage. The LLM-guided search explores a hierarchical search space, refining candidate architectures through Pareto optimization based on accuracy, multiply-accumulate operations (MACs), and memory metrics. The best-performing architectures are further fine-tuned using logits-based KD with a pre-trained ViT-B/16 model, which enhances generalization without increasing model size. Evaluated on the CIFAR-100 dataset and deployed on an STM32H7 microcontroller (MCU), the three proposed models, LMaNet-Elite, LMaNet-Core, and QwNet-Core, achieve accuracy scores of 74.50%, 74.20% and 73.00%, respectively. All three models surpass current state-of-the-art (SOTA) models, such as MCUNet-in3/in4 (69.62% / 72.86%) and XiNet (72.27%), while maintaining a low computational cost of less than 100 million MACs and adhering to the stringent 320 KB static random-access memory (SRAM) constraint. These results demonstrate the efficiency and performance of the proposed framework for TinyML platforms, underscoring the potential of combining LLM-driven search, Pareto optimization, KD, and explainability to develop accurate, efficient, and interpretable models. This approach opens new possibilities in NAS, enabling the design of efficient architectures specifically suited for TinyML.
Advancing THz Radio Map Construction and Obstacle Sensing: An Integrated Generative Framework in ISAC
Mar 29, 2025Integrated sensing and communication (ISAC) in the terahertz (THz) band enables obstacle detection, which in turn facilitates efficient beam management to mitigate THz signal blockage. Simultaneously, a THz radio map, which captures signal propagation characteristics through the distribution of received signal strength (RSS), is well-suited for sensing, as it inherently contains obstacle-related information and reflects the unique properties of the THz channel. This means that communication-assisted sensing in ISAC can be effectively achieved using a THz radio map. However, constructing a radio map presents significant challenges due to the sparse deployment of THz sensors and their limited ability to accurately measure the RSS distribution, which directly affects obstacle sensing. In this paper, we formulate an integrated problem for the first time, leveraging the mutual enhancement between sensed obstacles and the constructed THz radio maps. To address this challenge while improving generalization, we propose an integration framework based on a conditional generative adversarial network (CGAN), which uncovers the manifold structure of THz radio maps embedded with obstacle information. Furthermore, recognizing the shared environmental semantics across THz radio maps from different beam directions, we introduce a novel voting-based sensing scheme, where obstacles are detected by aggregating votes from THz radio maps generated by the CGAN. Simulation results demonstrate that the proposed framework outperforms non-integrated baselines in both radio map construction and obstacle sensing, achieving up to 44.3% and 90.6% reductions in mean squared error (MSE), respectively, in a real-world scenario. These results validate the effectiveness of the proposed voting-based scheme.
Energy-Latency Attacks: A New Adversarial Threat to Deep Learning
Mar 06, 2025The growing computational demand for deep neural networks ( DNNs) has raised concerns about their energy consumption and carbon footprint, particularly as the size and complexity of the models continue to increase. To address these challenges, energy-efficient hardware and custom accelerators have become essential. Additionally, adaptable DNN s are being developed to dynamically balance performance and efficiency. The use of these strategies became more common to enable sustainable AI deployment. However, these efficiency-focused designs may also introduce vulnerabilities, as attackers can potentially exploit them to increase latency and energy usage by triggering their worst-case-performance scenarios. This new type of attack, called energy-latency attacks, has recently gained significant research attention, focusing on the vulnerability of DNN s to this emerging attack paradigm, which can trigger denial-of-service ( DoS) attacks. This paper provides a comprehensive overview of current research on energy-latency attacks, categorizing them using the established taxonomy for traditional adversarial attacks. We explore different metrics used to measure the success of these attacks and provide an analysis and comparison of existing attack strategies. We also analyze existing defense mechanisms and highlight current challenges and potential areas for future research in this developing field. The GitHub page for this work can be accessed at https://github.com/hbrachemi/Survey_energy_attacks/