 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsset Harvester: Extracting 3D Assets from Autonomous Driving Logs for Simulation
Apr 20, 2026Closed-loop simulation is a core component of autonomous vehicle (AV) development, enabling scalable testing, training, and safety validation before real-world deployment. Neural scene reconstruction converts driving logs into interactive 3D environments for simulation, but it does not produce complete 3D object assets required for agent manipulation and large-viewpoint novel-view synthesis. To address this challenge, we present Asset Harvester, an image-to-3D model and end-to-end pipeline that converts sparse, in-the-wild object observations from real driving logs into complete, simulation-ready assets. Rather than relying on a single model component, we developed a system-level design for real-world AV data that combines large-scale curation of object-centric training tuples, geometry-aware preprocessing across heterogeneous sensors, and a robust training recipe that couples sparse-view-conditioned multiview generation with 3D Gaussian lifting. Within this system, SparseViewDiT is explicitly designed to address limited-angle views and other real-world data challenges. Together with hybrid data curation, augmentation, and self-distillation, this system enables scalable conversion of sparse AV object observations into reusable 3D assets.
Enhance Images as You Like with Unpaired Learning
Oct 04, 2021
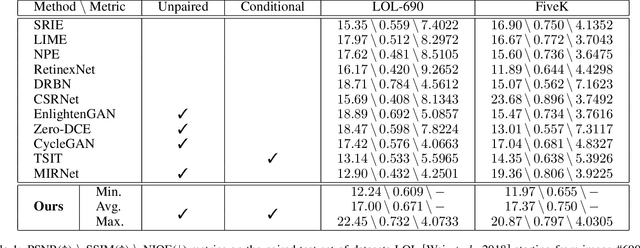

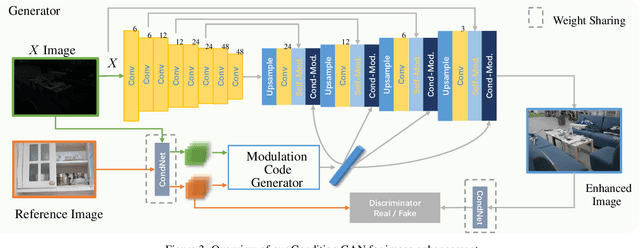
Low-light image enhancement exhibits an ill-posed nature, as a given image may have many enhanced versions, yet recent studies focus on building a deterministic mapping from input to an enhanced version. In contrast, we propose a lightweight one-path conditional generative adversarial network (cGAN) to learn a one-to-many relation from low-light to normal-light image space, given only sets of low- and normal-light training images without any correspondence. By formulating this ill-posed problem as a modulation code learning task, our network learns to generate a collection of enhanced images from a given input conditioned on various reference images. Therefore our inference model easily adapts to various user preferences, provided with a few favorable photos from each user. Our model achieves competitive visual and quantitative results on par with fully supervised methods on both noisy and clean datasets, while being 6 to 10 times lighter than state-of-the-art generative adversarial networks (GANs) approaches.