 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResistive Memory-based Neural Differential Equation Solver for Score-based Diffusion Model
Apr 08, 2024



Human brains image complicated scenes when reading a novel. Replicating this imagination is one of the ultimate goals of AI-Generated Content (AIGC). However, current AIGC methods, such as score-based diffusion, are still deficient in terms of rapidity and efficiency. This deficiency is rooted in the difference between the brain and digital computers. Digital computers have physically separated storage and processing units, resulting in frequent data transfers during iterative calculations, incurring large time and energy overheads. This issue is further intensified by the conversion of inherently continuous and analog generation dynamics, which can be formulated by neural differential equations, into discrete and digital operations. Inspired by the brain, we propose a time-continuous and analog in-memory neural differential equation solver for score-based diffusion, employing emerging resistive memory. The integration of storage and computation within resistive memory synapses surmount the von Neumann bottleneck, benefiting the generative speed and energy efficiency. The closed-loop feedback integrator is time-continuous, analog, and compact, physically implementing an infinite-depth neural network. Moreover, the software-hardware co-design is intrinsically robust to analog noise. We experimentally validate our solution with 180 nm resistive memory in-memory computing macros. Demonstrating equivalent generative quality to the software baseline, our system achieved remarkable enhancements in generative speed for both unconditional and conditional generation tasks, by factors of 64.8 and 156.5, respectively. Moreover, it accomplished reductions in energy consumption by factors of 5.2 and 4.1. Our approach heralds a new horizon for hardware solutions in edge computing for generative AI applications.
Total-Decom: Decomposed 3D Scene Reconstruction with Minimal Interaction
Mar 30, 2024



Scene reconstruction from multi-view images is a fundamental problem in computer vision and graphics. Recent neural implicit surface reconstruction methods have achieved high-quality results; however, editing and manipulating the 3D geometry of reconstructed scenes remains challenging due to the absence of naturally decomposed object entities and complex object/background compositions. In this paper, we present Total-Decom, a novel method for decomposed 3D reconstruction with minimal human interaction. Our approach seamlessly integrates the Segment Anything Model (SAM) with hybrid implicit-explicit neural surface representations and a mesh-based region-growing technique for accurate 3D object decomposition. Total-Decom requires minimal human annotations while providing users with real-time control over the granularity and quality of decomposition. We extensively evaluate our method on benchmark datasets and demonstrate its potential for downstream applications, such as animation and scene editing. The code is available at https://github.com/CVMI-Lab/Total-Decom.git.
3DGSR: Implicit Surface Reconstruction with 3D Gaussian Splatting
Mar 30, 2024In this paper, we present an implicit surface reconstruction method with 3D Gaussian Splatting (3DGS), namely 3DGSR, that allows for accurate 3D reconstruction with intricate details while inheriting the high efficiency and rendering quality of 3DGS. The key insight is incorporating an implicit signed distance field (SDF) within 3D Gaussians to enable them to be aligned and jointly optimized. First, we introduce a differentiable SDF-to-opacity transformation function that converts SDF values into corresponding Gaussians' opacities. This function connects the SDF and 3D Gaussians, allowing for unified optimization and enforcing surface constraints on the 3D Gaussians. During learning, optimizing the 3D Gaussians provides supervisory signals for SDF learning, enabling the reconstruction of intricate details. However, this only provides sparse supervisory signals to the SDF at locations occupied by Gaussians, which is insufficient for learning a continuous SDF. Then, to address this limitation, we incorporate volumetric rendering and align the rendered geometric attributes (depth, normal) with those derived from 3D Gaussians. This consistency regularization introduces supervisory signals to locations not covered by discrete 3D Gaussians, effectively eliminating redundant surfaces outside the Gaussian sampling range. Our extensive experimental results demonstrate that our 3DGSR method enables high-quality 3D surface reconstruction while preserving the efficiency and rendering quality of 3DGS. Besides, our method competes favorably with leading surface reconstruction techniques while offering a more efficient learning process and much better rendering qualities. The code will be available at https://github.com/CVMI-Lab/3DGSR.
Can 3D Vision-Language Models Truly Understand Natural Language?
Mar 28, 2024



Rapid advancements in 3D vision-language (3D-VL) tasks have opened up new avenues for human interaction with embodied agents or robots using natural language. Despite this progress, we find a notable limitation: existing 3D-VL models exhibit sensitivity to the styles of language input, struggling to understand sentences with the same semantic meaning but written in different variants. This observation raises a critical question: Can 3D vision-language models truly understand natural language? To test the language understandability of 3D-VL models, we first propose a language robustness task for systematically assessing 3D-VL models across various tasks, benchmarking their performance when presented with different language style variants. Importantly, these variants are commonly encountered in applications requiring direct interaction with humans, such as embodied robotics, given the diversity and unpredictability of human language. We propose a 3D Language Robustness Dataset, designed based on the characteristics of human language, to facilitate the systematic study of robustness. Our comprehensive evaluation uncovers a significant drop in the performance of all existing models across various 3D-VL tasks. Even the state-of-the-art 3D-LLM fails to understand some variants of the same sentences. Further in-depth analysis suggests that the existing models have a fragile and biased fusion module, which stems from the low diversity of the existing dataset. Finally, we propose a training-free module driven by LLM, which improves language robustness. Datasets and code will be available at github.
Classes Are Not Equal: An Empirical Study on Image Recognition Fairness
Mar 13, 2024In this paper, we present an empirical study on image recognition fairness, i.e., extreme class accuracy disparity on balanced data like ImageNet. We experimentally demonstrate that classes are not equal and the fairness issue is prevalent for image classification models across various datasets, network architectures, and model capacities. Moreover, several intriguing properties of fairness are identified. First, the unfairness lies in problematic representation rather than classifier bias. Second, with the proposed concept of Model Prediction Bias, we investigate the origins of problematic representation during optimization. Our findings reveal that models tend to exhibit greater prediction biases for classes that are more challenging to recognize. It means that more other classes will be confused with harder classes. Then the False Positives (FPs) will dominate the learning in optimization, thus leading to their poor accuracy. Further, we conclude that data augmentation and representation learning algorithms improve overall performance by promoting fairness to some degree in image classification. The Code is available at https://github.com/dvlab-research/Parametric-Contrastive-Learning.
DO3D: Self-supervised Learning of Decomposed Object-aware 3D Motion and Depth from Monocular Videos
Mar 09, 2024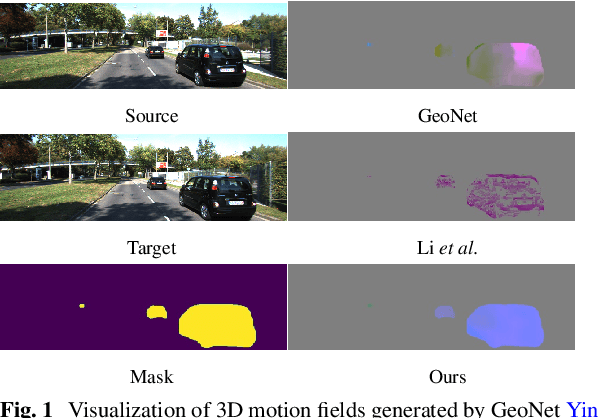
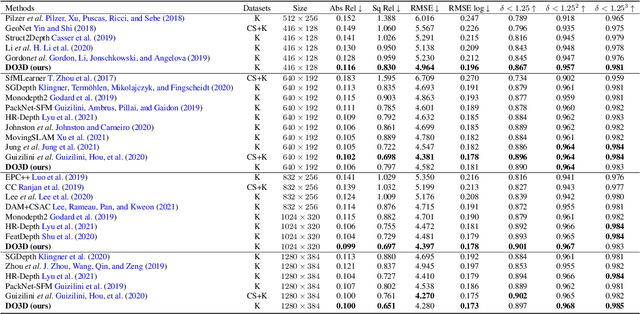
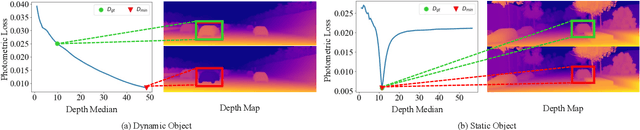

Although considerable advancements have been attained in self-supervised depth estimation from monocular videos, most existing methods often treat all objects in a video as static entities, which however violates the dynamic nature of real-world scenes and fails to model the geometry and motion of moving objects. In this paper, we propose a self-supervised method to jointly learn 3D motion and depth from monocular videos. Our system contains a depth estimation module to predict depth, and a new decomposed object-wise 3D motion (DO3D) estimation module to predict ego-motion and 3D object motion. Depth and motion networks work collaboratively to faithfully model the geometry and dynamics of real-world scenes, which, in turn, benefits both depth and 3D motion estimation. Their predictions are further combined to synthesize a novel video frame for self-supervised training. As a core component of our framework, DO3D is a new motion disentanglement module that learns to predict camera ego-motion and instance-aware 3D object motion separately. To alleviate the difficulties in estimating non-rigid 3D object motions, they are decomposed to object-wise 6-DoF global transformations and a pixel-wise local 3D motion deformation field. Qualitative and quantitative experiments are conducted on three benchmark datasets, including KITTI, Cityscapes, and VKITTI2, where our model delivers superior performance in all evaluated settings. For the depth estimation task, our model outperforms all compared research works in the high-resolution setting, attaining an absolute relative depth error (abs rel) of 0.099 on the KITTI benchmark. Besides, our optical flow estimation results (an overall EPE of 7.09 on KITTI) also surpass state-of-the-art methods and largely improve the estimation of dynamic regions, demonstrating the effectiveness of our motion model. Our code will be available.
Spec-Gaussian: Anisotropic View-Dependent Appearance for 3D Gaussian Splatting
Feb 24, 2024



The recent advancements in 3D Gaussian splatting (3D-GS) have not only facilitated real-time rendering through modern GPU rasterization pipelines but have also attained state-of-the-art rendering quality. Nevertheless, despite its exceptional rendering quality and performance on standard datasets, 3D-GS frequently encounters difficulties in accurately modeling specular and anisotropic components. This issue stems from the limited ability of spherical harmonics (SH) to represent high-frequency information. To overcome this challenge, we introduce Spec-Gaussian, an approach that utilizes an anisotropic spherical Gaussian (ASG) appearance field instead of SH for modeling the view-dependent appearance of each 3D Gaussian. Additionally, we have developed a coarse-to-fine training strategy to improve learning efficiency and eliminate floaters caused by overfitting in real-world scenes. Our experimental results demonstrate that our method surpasses existing approaches in terms of rendering quality. Thanks to ASG, we have significantly improved the ability of 3D-GS to model scenes with specular and anisotropic components without increasing the number of 3D Gaussians. This improvement extends the applicability of 3D GS to handle intricate scenarios with specular and anisotropic surfaces.
Debiasing Text-to-Image Diffusion Models
Feb 22, 2024Learning-based Text-to-Image (TTI) models like Stable Diffusion have revolutionized the way visual content is generated in various domains. However, recent research has shown that nonnegligible social bias exists in current state-of-the-art TTI systems, which raises important concerns. In this work, we target resolving the social bias in TTI diffusion models. We begin by formalizing the problem setting and use the text descriptions of bias groups to establish an unsafe direction for guiding the diffusion process. Next, we simplify the problem into a weight optimization problem and attempt a Reinforcement solver, Policy Gradient, which shows sub-optimal performance with slow convergence. Further, to overcome limitations, we propose an iterative distribution alignment (IDA) method. Despite its simplicity, we show that IDA shows efficiency and fast convergence in resolving the social bias in TTI diffusion models. Our code will be released.
EscherNet: A Generative Model for Scalable View Synthesis
Feb 06, 2024We introduce EscherNet, a multi-view conditioned diffusion model for view synthesis. EscherNet learns implicit and generative 3D representations coupled with a specialised camera positional encoding, allowing precise and continuous relative control of the camera transformation between an arbitrary number of reference and target views. EscherNet offers exceptional generality, flexibility, and scalability in view synthesis -- it can generate more than 100 consistent target views simultaneously on a single consumer-grade GPU, despite being trained with a fixed number of 3 reference views to 3 target views. As a result, EscherNet not only addresses zero-shot novel view synthesis, but also naturally unifies single- and multi-image 3D reconstruction, combining these diverse tasks into a single, cohesive framework. Our extensive experiments demonstrate that EscherNet achieves state-of-the-art performance in multiple benchmarks, even when compared to methods specifically tailored for each individual problem. This remarkable versatility opens up new directions for designing scalable neural architectures for 3D vision. Project page: \url{https://kxhit.github.io/EscherNet}.
BiLLM: Pushing the Limit of Post-Training Quantization for LLMs
Feb 06, 2024Pretrained large language models (LLMs) exhibit exceptional general language processing capabilities but come with significant demands on memory and computational resources. As a powerful compression technology, binarization can extremely reduce model weights to a mere 1 bit, lowering the expensive computation and memory requirements. However, existing quantization techniques fall short of maintaining LLM performance under ultra-low bit-widths. In response to this challenge, we present BiLLM, a groundbreaking 1-bit post-training quantization scheme tailored for pretrained LLMs. Based on the weight distribution of LLMs, BiLLM first identifies and structurally selects salient weights, and minimizes the compression loss through an effective binary residual approximation strategy. Moreover, considering the bell-shaped distribution of the non-salient weights, we propose an optimal splitting search to group and binarize them accurately. BiLLM achieving for the first time high-accuracy inference (e.g. 8.41 perplexity on LLaMA2-70B) with only 1.08-bit weights across various LLMs families and evaluation metrics, outperforms SOTA quantization methods of LLM by significant margins. Moreover, BiLLM enables the binarization process of the LLM with 7 billion weights within 0.5 hours on a single GPU, demonstrating satisfactory time efficiency.