 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject-Centric Stereo Ranging for Autonomous Driving: From Dense Disparity to Census-Based Template Matching
Apr 09, 2026Accurate depth estimation is critical for autonomous driving perception systems, particularly for long range vehicle detection on highways. Traditional dense stereo matching methods such as Block Matching (BM) and Semi Global Matching (SGM) produce per pixel disparity maps but suffer from high computational cost, sensitivity to radiometric differences between stereo cameras, and poor accuracy at long range where disparity values are small. In this report, we present a comprehensive stereo ranging system that integrates three complementary depth estimation approaches: dense BM/SGM disparity, object centric Census based template matching, and monocular geometric priors, within a unified detection ranging tracking pipeline. Our key contribution is a novel object centric Census based template matching algorithm that performs GPU accelerated sparse stereo matching directly within detected bounding boxes, employing a far close divide and conquer strategy, forward backward verification, occlusion aware sampling, and robust multi block aggregation. We further describe an online calibration refinement framework that combines auto rectification offset search, radar stereo voting based disparity correction, and object level radar stereo association for continuous extrinsic drift compensation. The complete system achieves real time performance through asynchronous GPU pipeline design and delivers robust ranging across diverse driving conditions including nighttime, rain, and varying illumination.
DO3D: Self-supervised Learning of Decomposed Object-aware 3D Motion and Depth from Monocular Videos
Mar 09, 2024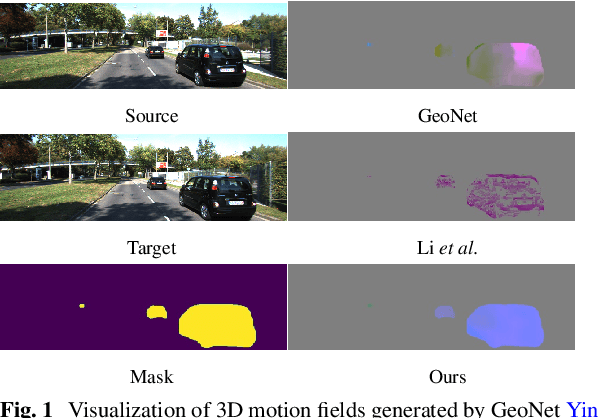
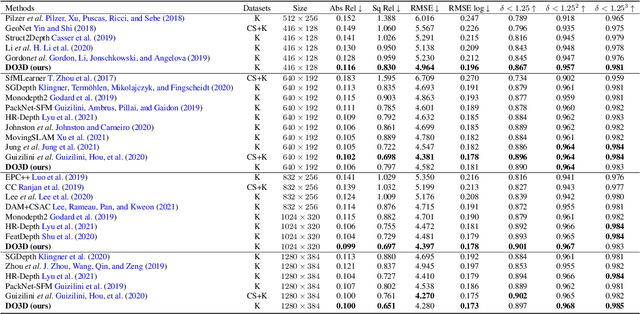
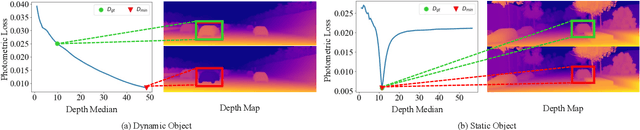

Although considerable advancements have been attained in self-supervised depth estimation from monocular videos, most existing methods often treat all objects in a video as static entities, which however violates the dynamic nature of real-world scenes and fails to model the geometry and motion of moving objects. In this paper, we propose a self-supervised method to jointly learn 3D motion and depth from monocular videos. Our system contains a depth estimation module to predict depth, and a new decomposed object-wise 3D motion (DO3D) estimation module to predict ego-motion and 3D object motion. Depth and motion networks work collaboratively to faithfully model the geometry and dynamics of real-world scenes, which, in turn, benefits both depth and 3D motion estimation. Their predictions are further combined to synthesize a novel video frame for self-supervised training. As a core component of our framework, DO3D is a new motion disentanglement module that learns to predict camera ego-motion and instance-aware 3D object motion separately. To alleviate the difficulties in estimating non-rigid 3D object motions, they are decomposed to object-wise 6-DoF global transformations and a pixel-wise local 3D motion deformation field. Qualitative and quantitative experiments are conducted on three benchmark datasets, including KITTI, Cityscapes, and VKITTI2, where our model delivers superior performance in all evaluated settings. For the depth estimation task, our model outperforms all compared research works in the high-resolution setting, attaining an absolute relative depth error (abs rel) of 0.099 on the KITTI benchmark. Besides, our optical flow estimation results (an overall EPE of 7.09 on KITTI) also surpass state-of-the-art methods and largely improve the estimation of dynamic regions, demonstrating the effectiveness of our motion model. Our code will be available.
DualBEV: CNN is All You Need in View Transformation
Mar 08, 2024Camera-based Bird's-Eye-View (BEV) perception often struggles between adopting 3D-to-2D or 2D-to-3D view transformation (VT). The 3D-to-2D VT typically employs resource intensive Transformer to establish robust correspondences between 3D and 2D feature, while the 2D-to-3D VT utilizes the Lift-Splat-Shoot (LSS) pipeline for real-time application, potentially missing distant information. To address these limitations, we propose DualBEV, a unified framework that utilizes a shared CNN-based feature transformation incorporating three probabilistic measurements for both strategies. By considering dual-view correspondences in one-stage, DualBEV effectively bridges the gap between these strategies, harnessing their individual strengths. Our method achieves state-of-the-art performance without Transformer, delivering comparable efficiency to the LSS approach, with 55.2% mAP and 63.4% NDS on the nuScenes test set. Code will be released at https://github.com/PeidongLi/DualBEV.