 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing the Teacher-Student Knowledge Discrepancy in Distillation
Mar 31, 2021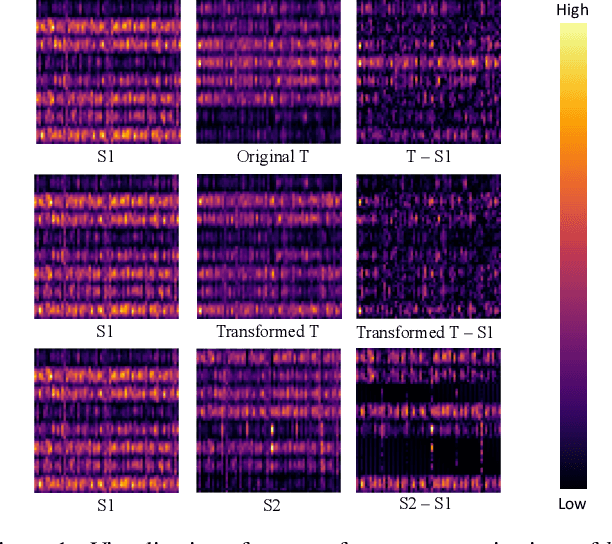

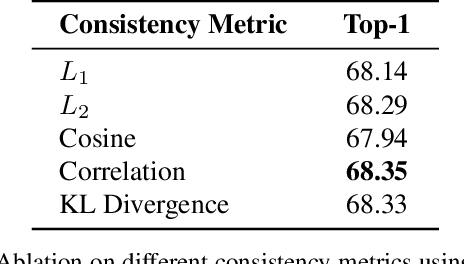
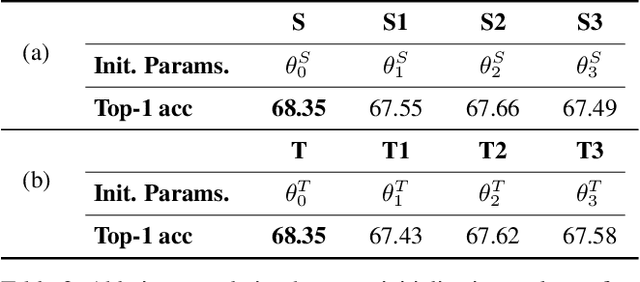
Training a small student network with the guidance of a larger teacher network is an effective way to promote the performance of the student. Despite the different types, the guided knowledge used to distill is always kept unchanged for different teacher and student pairs in previous knowledge distillation methods. However, we find that teacher and student models with different networks or trained from different initialization could have distinct feature representations among different channels. (e.g. the high activated channel for different categories). We name this incongruous representation of channels as teacher-student knowledge discrepancy in the distillation process. Ignoring the knowledge discrepancy problem of teacher and student models will make the learning of student from teacher more difficult. To solve this problem, in this paper, we propose a novel student-dependent distillation method, knowledge consistent distillation, which makes teacher's knowledge more consistent with the student and provides the best suitable knowledge to different student networks for distillation. Extensive experiments on different datasets (CIFAR100, ImageNet, COCO) and tasks (image classification, object detection) reveal the widely existing knowledge discrepancy problem between teachers and students and demonstrate the effectiveness of our proposed method. Our method is very flexible that can be easily combined with other state-of-the-art approaches.
Learning Fine-Grained Segmentation of 3D Shapes without Part Labels
Mar 24, 2021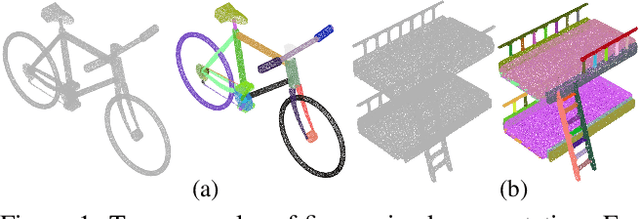
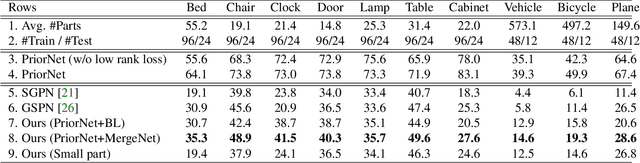
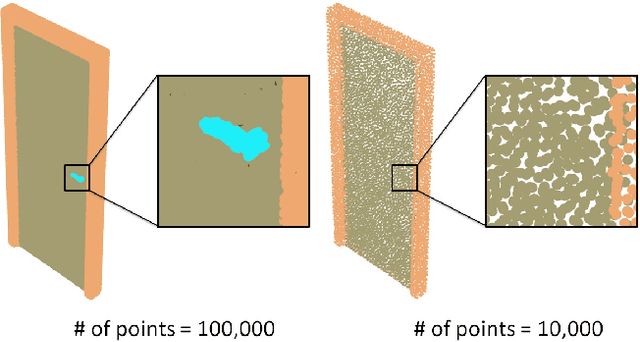
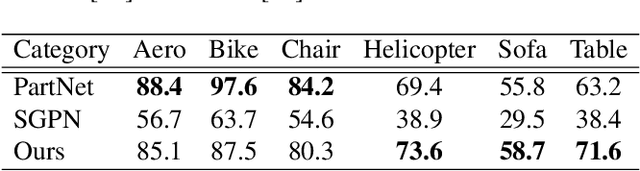
Learning-based 3D shape segmentation is usually formulated as a semantic labeling problem, assuming that all parts of training shapes are annotated with a given set of tags. This assumption, however, is impractical for learning fine-grained segmentation. Although most off-the-shelf CAD models are, by construction, composed of fine-grained parts, they usually miss semantic tags and labeling those fine-grained parts is extremely tedious. We approach the problem with deep clustering, where the key idea is to learn part priors from a shape dataset with fine-grained segmentation but no part labels. Given point sampled 3D shapes, we model the clustering priors of points with a similarity matrix and achieve part segmentation through minimizing a novel low rank loss. To handle highly densely sampled point sets, we adopt a divide-and-conquer strategy. We partition the large point set into a number of blocks. Each block is segmented using a deep-clustering-based part prior network trained in a category-agnostic manner. We then train a graph convolution network to merge the segments of all blocks to form the final segmentation result. Our method is evaluated with a challenging benchmark of fine-grained segmentation, showing state-of-the-art performance.
DivCo: Diverse Conditional Image Synthesis via Contrastive Generative Adversarial Network
Mar 14, 2021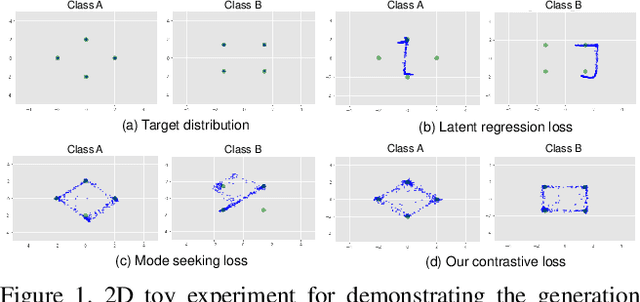
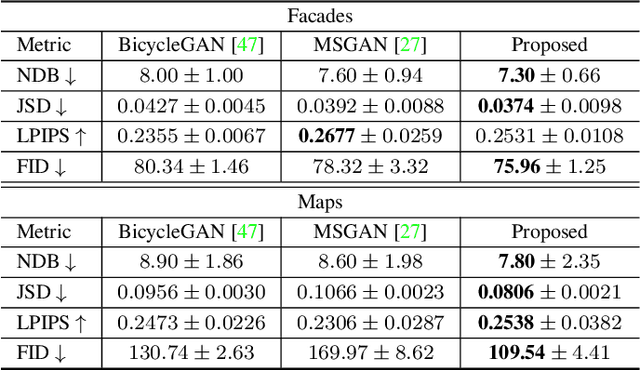
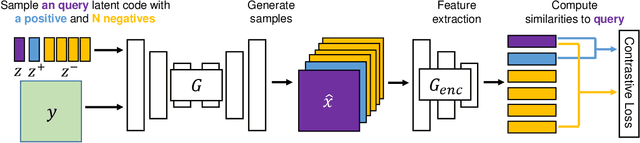
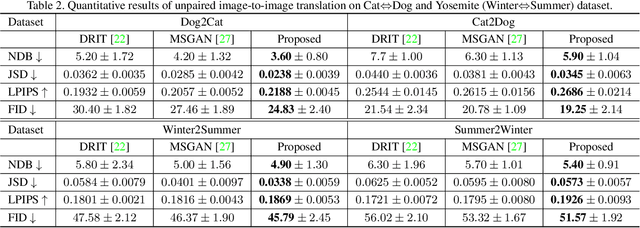
Conditional generative adversarial networks (cGANs) target at synthesizing diverse images given the input conditions and latent codes, but unfortunately, they usually suffer from the issue of mode collapse. To solve this issue, previous works mainly focused on encouraging the correlation between the latent codes and their generated images, while ignoring the relations between images generated from various latent codes. The recent MSGAN tried to encourage the diversity of the generated image but only considers "negative" relations between the image pairs. In this paper, we propose a novel DivCo framework to properly constrain both "positive" and "negative" relations between the generated images specified in the latent space. To the best of our knowledge, this is the first attempt to use contrastive learning for diverse conditional image synthesis. A novel latent-augmented contrastive loss is introduced, which encourages images generated from adjacent latent codes to be similar and those generated from distinct latent codes to be dissimilar. The proposed latent-augmented contrastive loss is well compatible with various cGAN architectures. Extensive experiments demonstrate that the proposed DivCo can produce more diverse images than state-of-the-art methods without sacrificing visual quality in multiple unpaired and paired image generation tasks.
PV-RCNN++: Point-Voxel Feature Set Abstraction With Local Vector Representation for 3D Object Detection
Jan 31, 2021
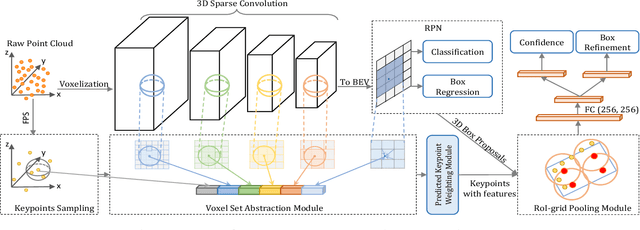
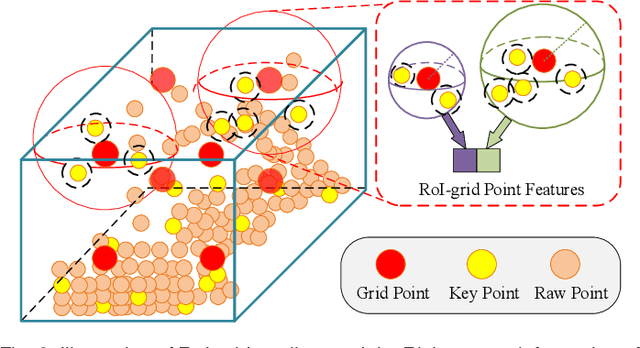

3D object detection is receiving increasing attention from both industry and academia thanks to its wide applications in various fields. In this paper, we propose the Point-Voxel Region based Convolution Neural Networks (PV-RCNNs) for accurate 3D detection from point clouds. First, we propose a novel 3D object detector, PV-RCNN-v1, which employs the voxel-to-keypoint scene encoding and keypoint-to-grid RoI feature abstraction two novel steps. These two steps deeply incorporate both 3D voxel CNN and PointNet-based set abstraction for learning discriminative point-cloud features. Second, we propose a more advanced framework, PV-RCNN-v2, for more efficient and accurate 3D detection. It consists of two major improvements, where the first one is the sectorized proposal-centric strategy for efficiently producing more representative and uniformly distributed keypoints, and the second one is the VectorPool aggregation to replace set abstraction for better aggregating local point-cloud features with much less resource consumption. With these two major modifications, our PV-RCNN-v2 runs more than twice as fast as the v1 version while still achieving better performance on the large-scale Waymo Open Dataset with 150m * 150m detection range. Extensive experiments demonstrate that our proposed PV-RCNNs significantly outperform previous state-of-the-art 3D detection methods on both the Waymo Open Dataset and the highly-competitive KITTI benchmark.
Probabilistic Graph Attention Network with Conditional Kernels for Pixel-Wise Prediction
Jan 08, 2021
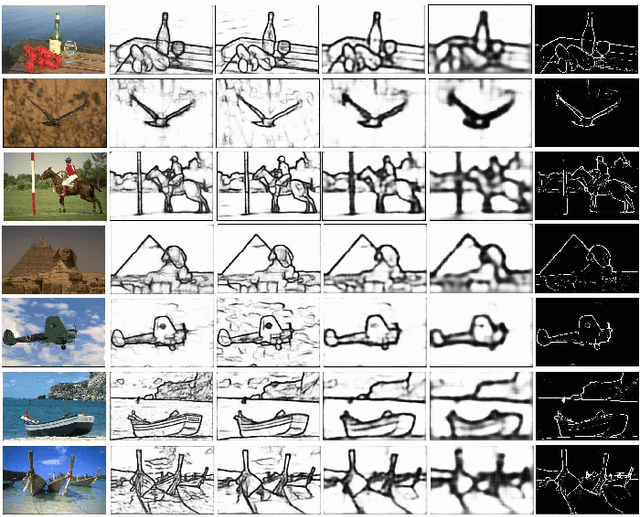
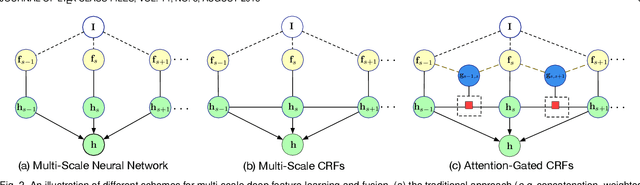
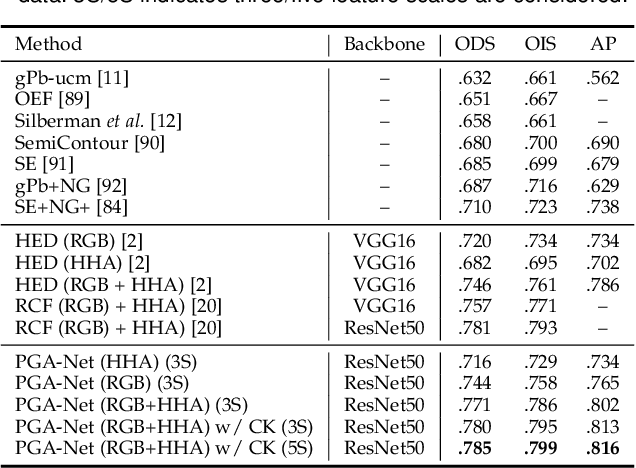
Multi-scale representations deeply learned via convolutional neural networks have shown tremendous importance for various pixel-level prediction problems. In this paper we present a novel approach that advances the state of the art on pixel-level prediction in a fundamental aspect, i.e. structured multi-scale features learning and fusion. In contrast to previous works directly considering multi-scale feature maps obtained from the inner layers of a primary CNN architecture, and simply fusing the features with weighted averaging or concatenation, we propose a probabilistic graph attention network structure based on a novel Attention-Gated Conditional Random Fields (AG-CRFs) model for learning and fusing multi-scale representations in a principled manner. In order to further improve the learning capacity of the network structure, we propose to exploit feature dependant conditional kernels within the deep probabilistic framework. Extensive experiments are conducted on four publicly available datasets (i.e. BSDS500, NYUD-V2, KITTI, and Pascal-Context) and on three challenging pixel-wise prediction problems involving both discrete and continuous labels (i.e. monocular depth estimation, object contour prediction, and semantic segmentation). Quantitative and qualitative results demonstrate the effectiveness of the proposed latent AG-CRF model and the overall probabilistic graph attention network with feature conditional kernels for structured feature learning and pixel-wise prediction.
A Holistically-Guided Decoder for Deep Representation Learning with Applications to Semantic Segmentation and Object Detection
Dec 18, 2020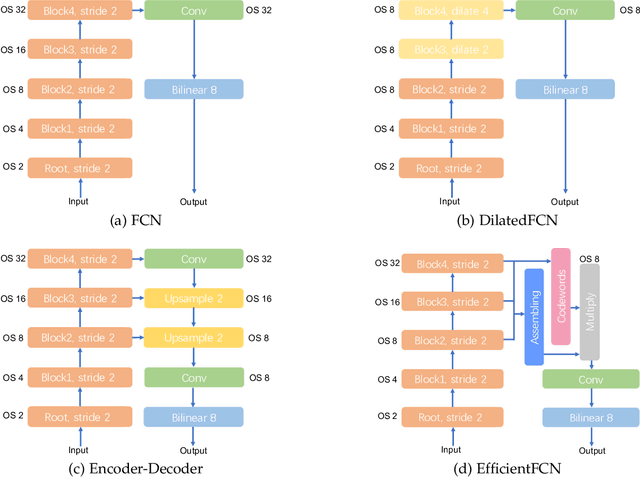
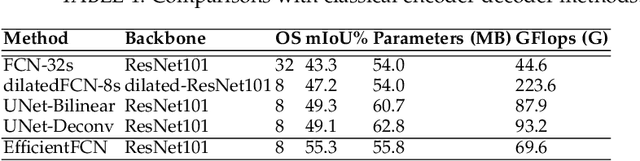
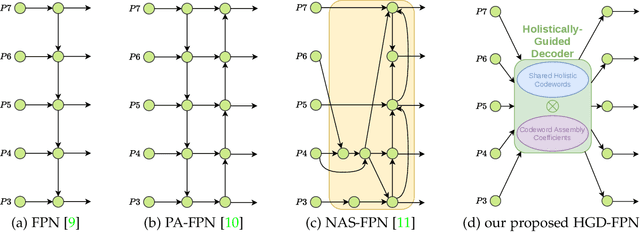
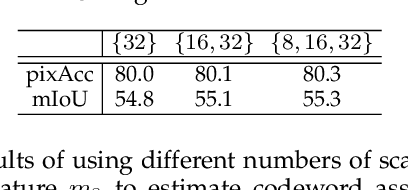
Both high-level and high-resolution feature representations are of great importance in various visual understanding tasks. To acquire high-resolution feature maps with high-level semantic information, one common strategy is to adopt dilated convolutions in the backbone networks to extract high-resolution feature maps, such as the dilatedFCN-based methods for semantic segmentation. However, due to many convolution operations are conducted on the high-resolution feature maps, such methods have large computational complexity and memory consumption. In this paper, we propose one novel holistically-guided decoder which is introduced to obtain the high-resolution semantic-rich feature maps via the multi-scale features from the encoder. The decoding is achieved via novel holistic codeword generation and codeword assembly operations, which take advantages of both the high-level and low-level features from the encoder features. With the proposed holistically-guided decoder, we implement the EfficientFCN architecture for semantic segmentation and HGD-FPN for object detection and instance segmentation. The EfficientFCN achieves comparable or even better performance than state-of-the-art methods with only 1/3 of their computational costs for semantic segmentation on PASCAL Context, PASCAL VOC, ADE20K datasets. Meanwhile, the proposed HGD-FPN achieves $>2\%$ higher mean Average Precision (mAP) when integrated into several object detection frameworks with ResNet-50 encoding backbones.
End-to-End Object Detection with Adaptive Clustering Transformer
Nov 18, 2020
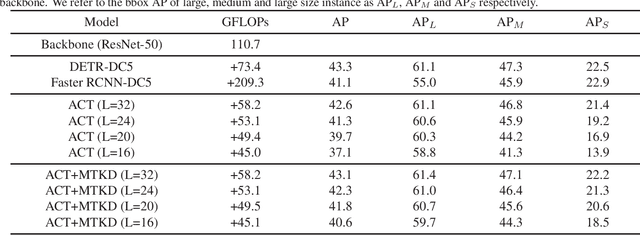
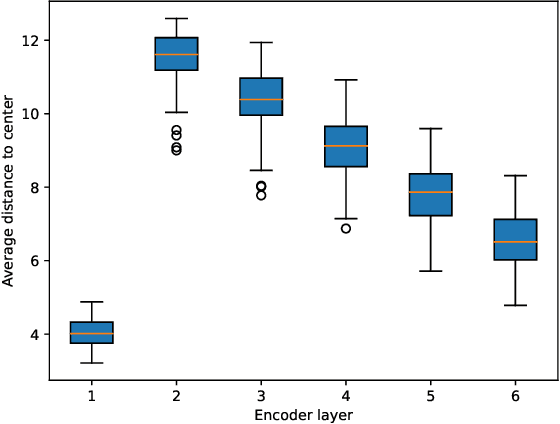
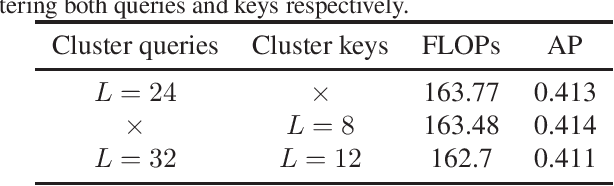
End-to-end Object Detection with Transformer (DETR)proposes to perform object detection with Transformer and achieve comparable performance with two-stage object detection like Faster-RCNN. However, DETR needs huge computational resources for training and inference due to the high-resolution spatial input. In this paper, a novel variant of transformer named Adaptive Clustering Transformer(ACT) has been proposed to reduce the computation cost for high-resolution input. ACT cluster the query features adaptively using Locality Sensitive Hashing (LSH) and ap-proximate the query-key interaction using the prototype-key interaction. ACT can reduce the quadratic O(N2) complexity inside self-attention into O(NK) where K is the number of prototypes in each layer. ACT can be a drop-in module replacing the original self-attention module without any training. ACT achieves a good balance between accuracy and computation cost (FLOPs). The code is available as supplementary for the ease of experiment replication and verification.
A Self-supervised Cascaded Refinement Network for Point Cloud Completion
Oct 17, 2020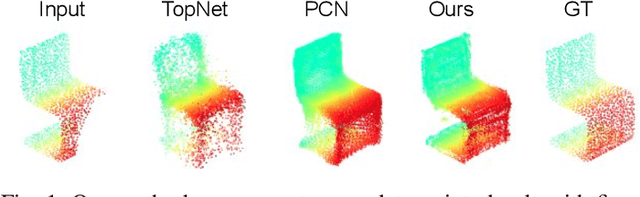
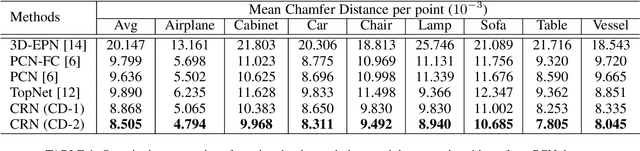
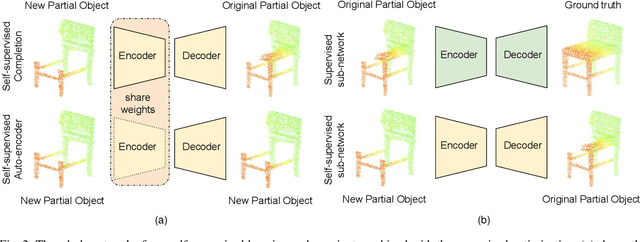

Point clouds are often sparse and incomplete, which imposes difficulties for real-world applications, such as 3D object classification, detection and segmentation. Existing shape completion methods tend to generate coarse shapes of objects without fine-grained details. Moreover, current approaches require fully-complete ground truth, which are difficult to obtain in real-world applications. In view of these, we propose a self-supervised object completion method, which optimizes the training procedure solely on the partial input without utilizing the fully-complete ground truth. In order to generate high-quality objects with detailed geometric structures, we propose a cascaded refinement network (CRN) with a coarse-to-fine strategy to synthesize the complete objects. Considering the local details of partial input together with the adversarial training, we are able to learn the complicated distributions of point clouds and generate the object details as realistic as possible. We verify our self-supervised method on both unsupervised and supervised experimental settings and show superior performances. Quantitative and qualitative experiments on different datasets demonstrate that our method achieves more realistic outputs compared to existing state-of-the-art approaches on the 3D point cloud completion task.
Auto Seg-Loss: Searching Metric Surrogates for Semantic Segmentation
Oct 15, 2020
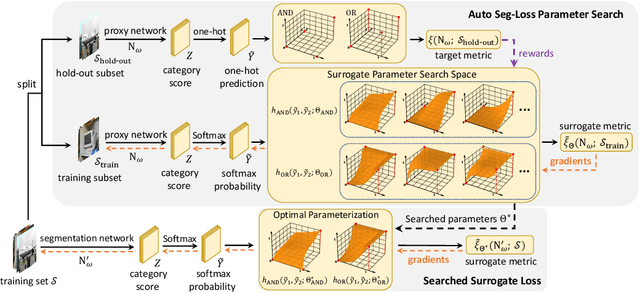
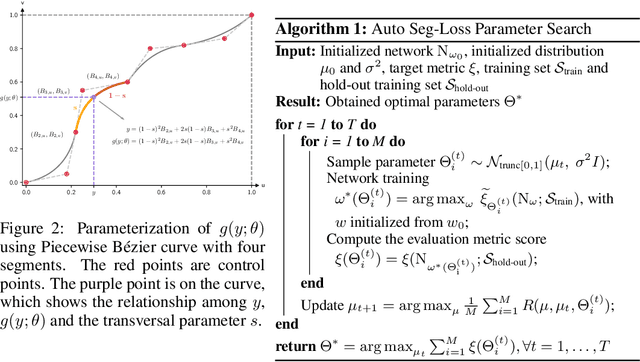
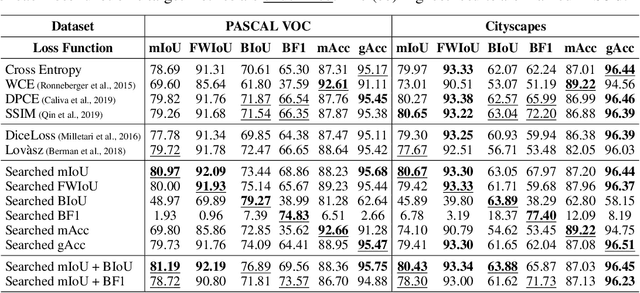
We propose a general framework for searching surrogate losses for mainstream semantic segmentation metrics. This is in contrast to existing loss functions manually designed for individual metrics. The searched surrogate losses can generalize well to other datasets and networks. Extensive experiments on PASCAL VOC and Cityscapes demonstrate the effectiveness of our approach. Code shall be released.
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Oct 08, 2020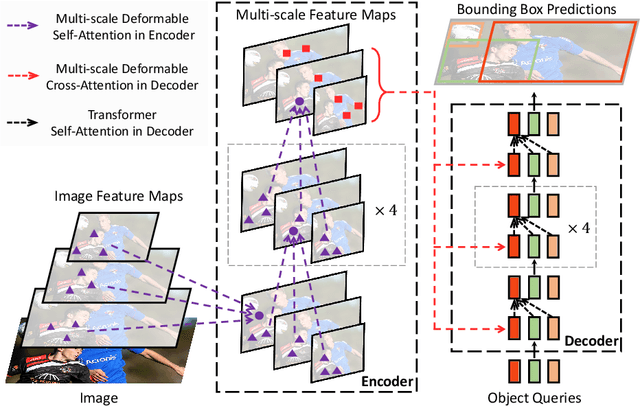
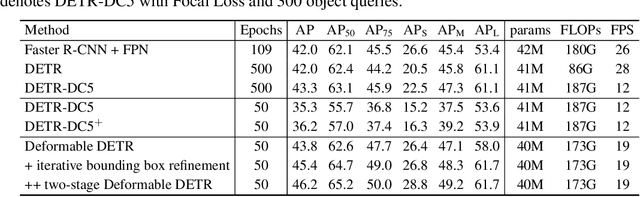
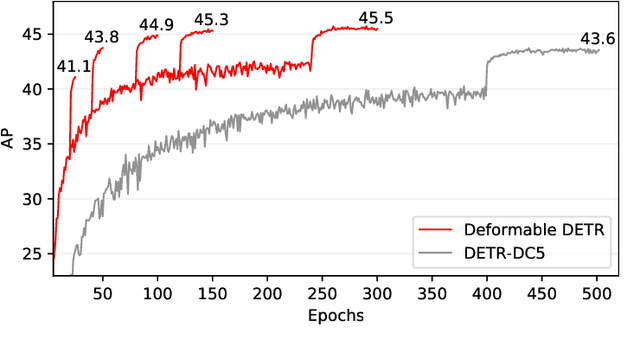
DETR has been recently proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance. However, it suffers from slow convergence and limited feature spatial resolution, due to the limitation of Transformer attention modules in processing image feature maps. To mitigate these issues, we proposed Deformable DETR, whose attention modules only attend to a small set of key sampling points around a reference. Deformable DETR can achieve better performance than DETR (especially on small objects) with 10$\times$ less training epochs. Extensive experiments on the COCO benchmark demonstrate the effectiveness of our approach. Code shall be released.