 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity-Aware Textual-Visual Matching with Latent Co-attention
Aug 07, 2017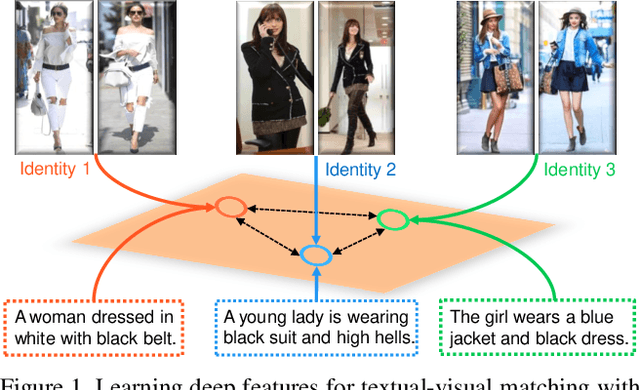
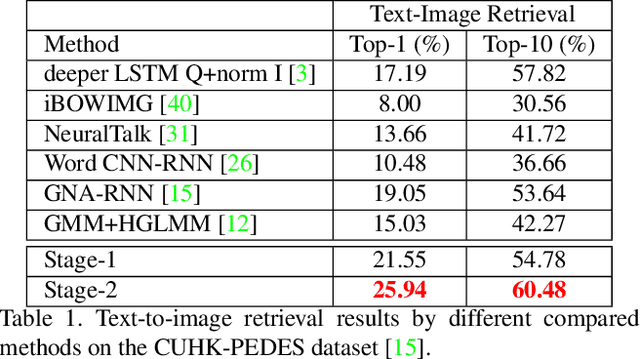
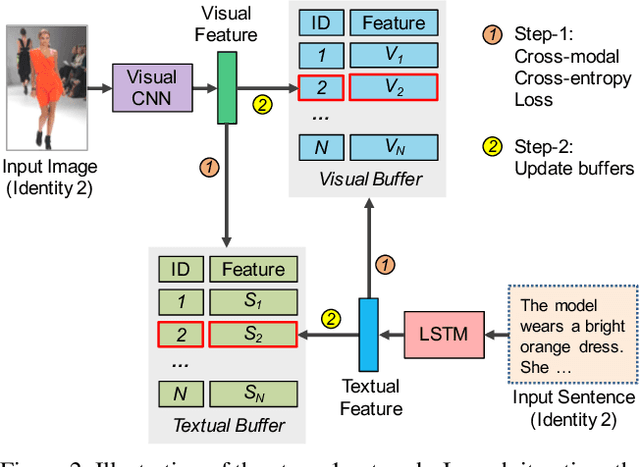
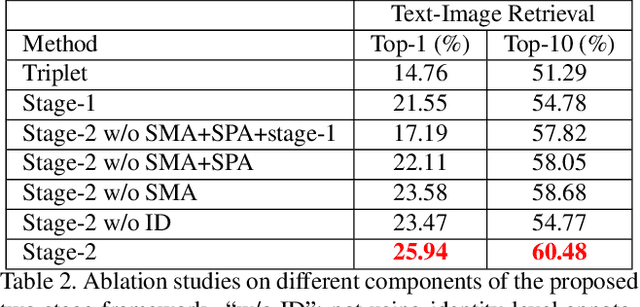
Textual-visual matching aims at measuring similarities between sentence descriptions and images. Most existing methods tackle this problem without effectively utilizing identity-level annotations. In this paper, we propose an identity-aware two-stage framework for the textual-visual matching problem. Our stage-1 CNN-LSTM network learns to embed cross-modal features with a novel Cross-Modal Cross-Entropy (CMCE) loss. The stage-1 network is able to efficiently screen easy incorrect matchings and also provide initial training point for the stage-2 training. The stage-2 CNN-LSTM network refines the matching results with a latent co-attention mechanism. The spatial attention relates each word with corresponding image regions while the latent semantic attention aligns different sentence structures to make the matching results more robust to sentence structure variations. Extensive experiments on three datasets with identity-level annotations show that our framework outperforms state-of-the-art approaches by large margins.
StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
Aug 05, 2017
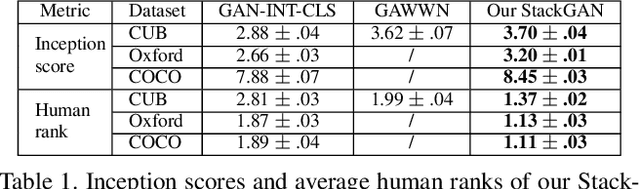
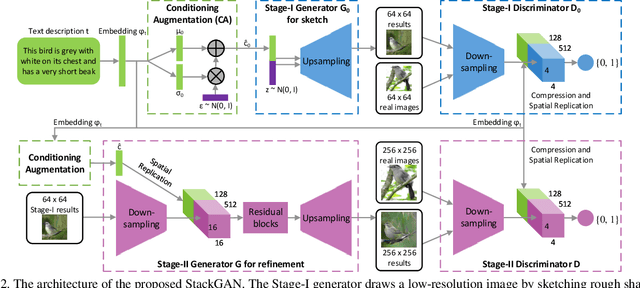
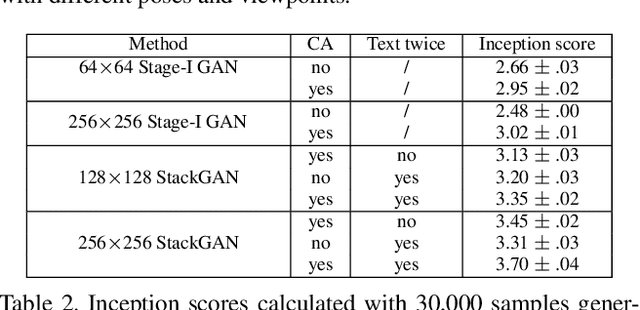
Synthesizing high-quality images from text descriptions is a challenging problem in computer vision and has many practical applications. Samples generated by existing text-to-image approaches can roughly reflect the meaning of the given descriptions, but they fail to contain necessary details and vivid object parts. In this paper, we propose Stacked Generative Adversarial Networks (StackGAN) to generate 256x256 photo-realistic images conditioned on text descriptions. We decompose the hard problem into more manageable sub-problems through a sketch-refinement process. The Stage-I GAN sketches the primitive shape and colors of the object based on the given text description, yielding Stage-I low-resolution images. The Stage-II GAN takes Stage-I results and text descriptions as inputs, and generates high-resolution images with photo-realistic details. It is able to rectify defects in Stage-I results and add compelling details with the refinement process. To improve the diversity of the synthesized images and stabilize the training of the conditional-GAN, we introduce a novel Conditioning Augmentation technique that encourages smoothness in the latent conditioning manifold. Extensive experiments and comparisons with state-of-the-arts on benchmark datasets demonstrate that the proposed method achieves significant improvements on generating photo-realistic images conditioned on text descriptions.
Learning Feature Pyramids for Human Pose Estimation
Aug 03, 2017
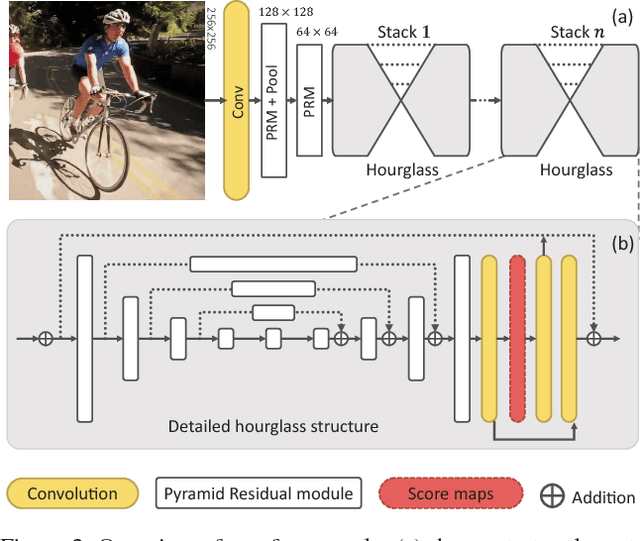
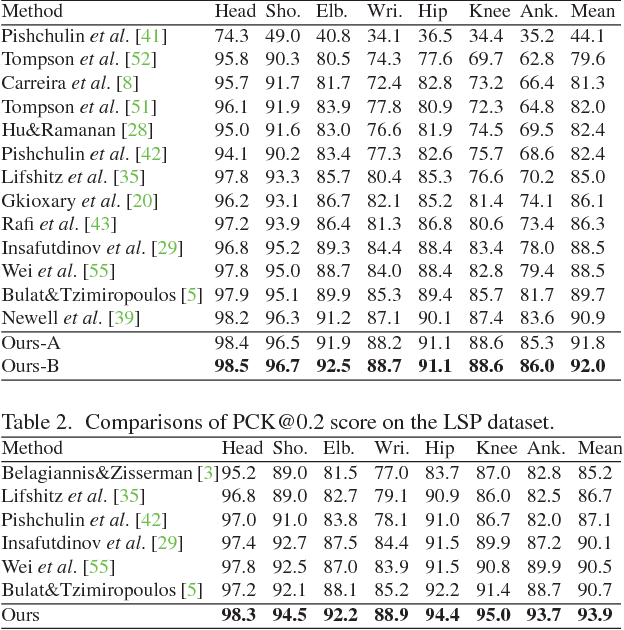
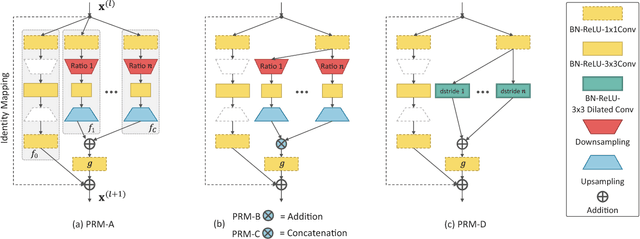
Articulated human pose estimation is a fundamental yet challenging task in computer vision. The difficulty is particularly pronounced in scale variations of human body parts when camera view changes or severe foreshortening happens. Although pyramid methods are widely used to handle scale changes at inference time, learning feature pyramids in deep convolutional neural networks (DCNNs) is still not well explored. In this work, we design a Pyramid Residual Module (PRMs) to enhance the invariance in scales of DCNNs. Given input features, the PRMs learn convolutional filters on various scales of input features, which are obtained with different subsampling ratios in a multi-branch network. Moreover, we observe that it is inappropriate to adopt existing methods to initialize the weights of multi-branch networks, which achieve superior performance than plain networks in many tasks recently. Therefore, we provide theoretic derivation to extend the current weight initialization scheme to multi-branch network structures. We investigate our method on two standard benchmarks for human pose estimation. Our approach obtains state-of-the-art results on both benchmarks. Code is available at https://github.com/bearpaw/PyraNet.
T-CNN: Tubelets with Convolutional Neural Networks for Object Detection from Videos
Aug 03, 2017
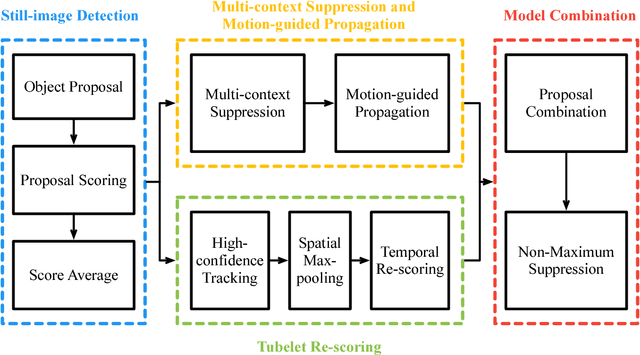

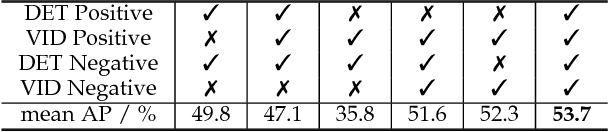
The state-of-the-art performance for object detection has been significantly improved over the past two years. Besides the introduction of powerful deep neural networks such as GoogleNet and VGG, novel object detection frameworks such as R-CNN and its successors, Fast R-CNN and Faster R-CNN, play an essential role in improving the state-of-the-art. Despite their effectiveness on still images, those frameworks are not specifically designed for object detection from videos. Temporal and contextual information of videos are not fully investigated and utilized. In this work, we propose a deep learning framework that incorporates temporal and contextual information from tubelets obtained in videos, which dramatically improves the baseline performance of existing still-image detection frameworks when they are applied to videos. It is called T-CNN, i.e. tubelets with convolutional neueral networks. The proposed framework won the recently introduced object-detection-from-video (VID) task with provided data in the ImageNet Large-Scale Visual Recognition Challenge 2015 (ILSVRC2015).
Zoom-in-Net: Deep Mining Lesions for Diabetic Retinopathy Detection
Jun 14, 2017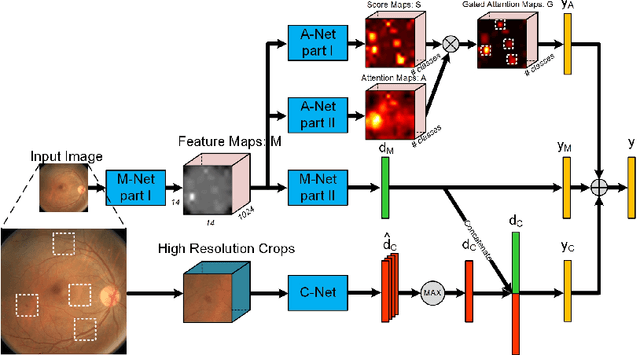

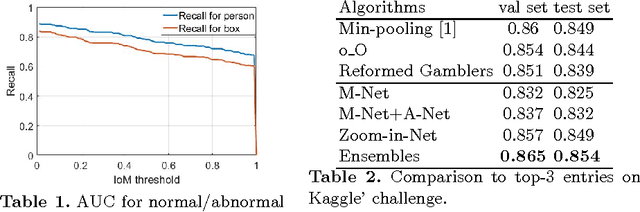

We propose a convolution neural network based algorithm for simultaneously diagnosing diabetic retinopathy and highlighting suspicious regions. Our contributions are two folds: 1) a network termed Zoom-in-Net which mimics the zoom-in process of a clinician to examine the retinal images. Trained with only image-level supervisions, Zoomin-Net can generate attention maps which highlight suspicious regions, and predicts the disease level accurately based on both the whole image and its high resolution suspicious patches. 2) Only four bounding boxes generated from the automatically learned attention maps are enough to cover 80% of the lesions labeled by an experienced ophthalmologist, which shows good localization ability of the attention maps. By clustering features at high response locations on the attention maps, we discover meaningful clusters which contain potential lesions in diabetic retinopathy. Experiments show that our algorithm outperform the state-of-the-art methods on two datasets, EyePACS and Messidor.
Learning Deep Representations for Scene Labeling with Semantic Context Guided Supervision
Jun 09, 2017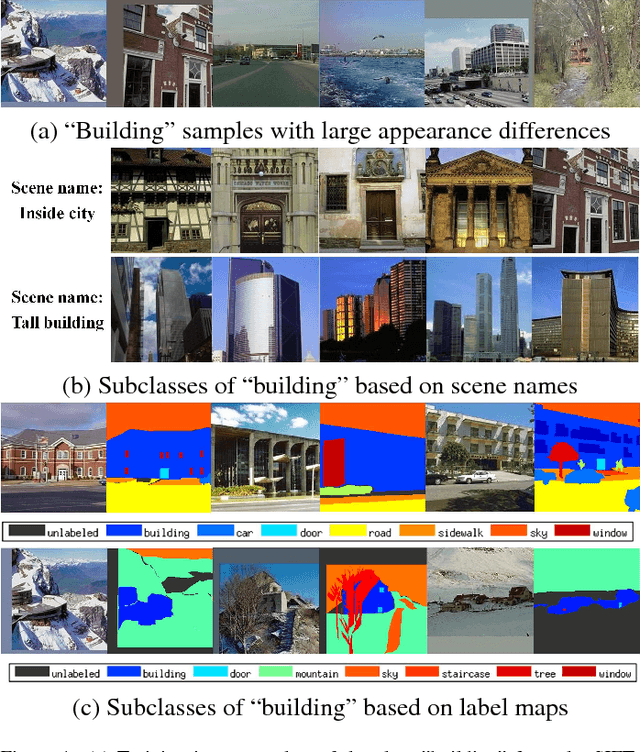
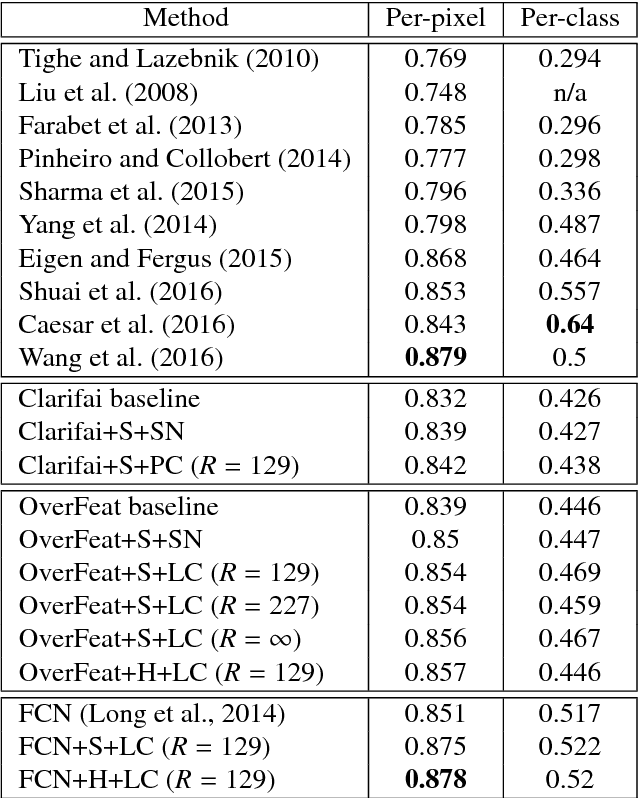
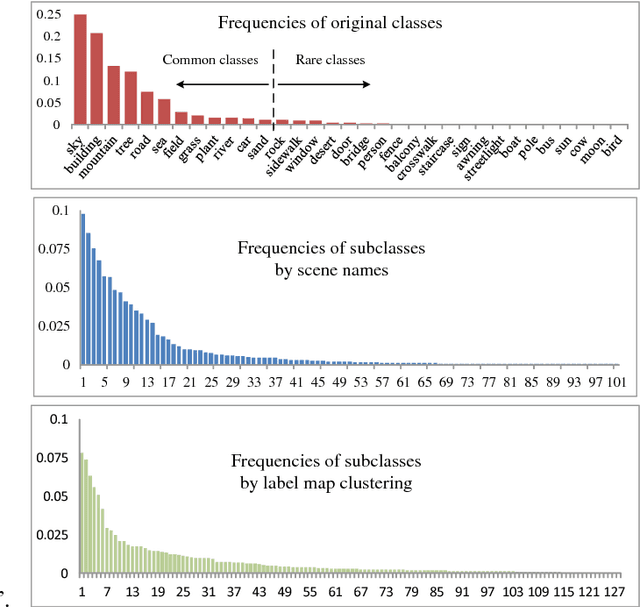

Scene labeling is a challenging classification problem where each input image requires a pixel-level prediction map. Recently, deep-learning-based methods have shown their effectiveness on solving this problem. However, we argue that the large intra-class variation provides ambiguous training information and hinders the deep models' ability to learn more discriminative deep feature representations. Unlike existing methods that mainly utilize semantic context for regularizing or smoothing the prediction map, we design novel supervisions from semantic context for learning better deep feature representations. Two types of semantic context, scene names of images and label map statistics of image patches, are exploited to create label hierarchies between the original classes and newly created subclasses as the learning supervisions. Such subclasses show lower intra-class variation, and help CNN detect more meaningful visual patterns and learn more effective deep features. Novel training strategies and network structure that take advantages of such label hierarchies are introduced. Our proposed method is evaluated extensively on four popular datasets, Stanford Background (8 classes), SIFTFlow (33 classes), Barcelona (170 classes) and LM+Sun datasets (232 classes) with 3 different networks structures, and show state-of-the-art performance. The experiments show that our proposed method makes deep models learn more discriminative feature representations without increasing model size or complexity.
Pyramid Scene Parsing Network
Apr 27, 2017
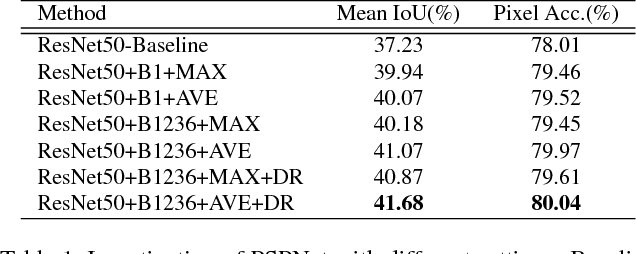
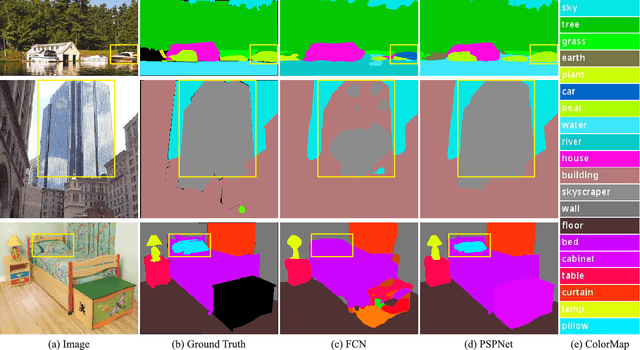
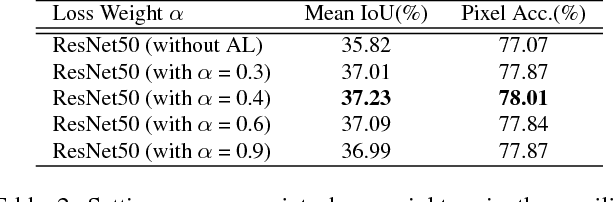
Scene parsing is challenging for unrestricted open vocabulary and diverse scenes. In this paper, we exploit the capability of global context information by different-region-based context aggregation through our pyramid pooling module together with the proposed pyramid scene parsing network (PSPNet). Our global prior representation is effective to produce good quality results on the scene parsing task, while PSPNet provides a superior framework for pixel-level prediction tasks. The proposed approach achieves state-of-the-art performance on various datasets. It came first in ImageNet scene parsing challenge 2016, PASCAL VOC 2012 benchmark and Cityscapes benchmark. A single PSPNet yields new record of mIoU accuracy 85.4% on PASCAL VOC 2012 and accuracy 80.2% on Cityscapes.
Residual Attention Network for Image Classification
Apr 23, 2017
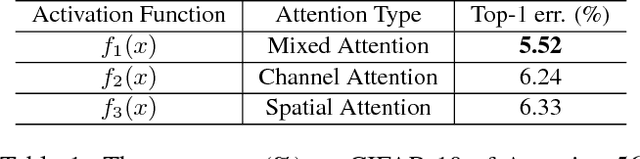
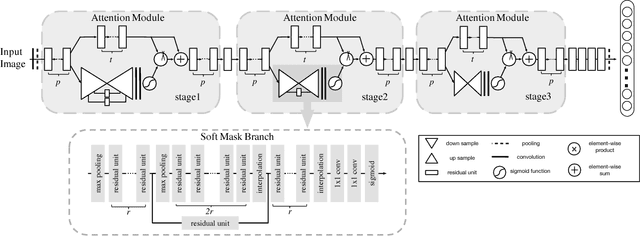
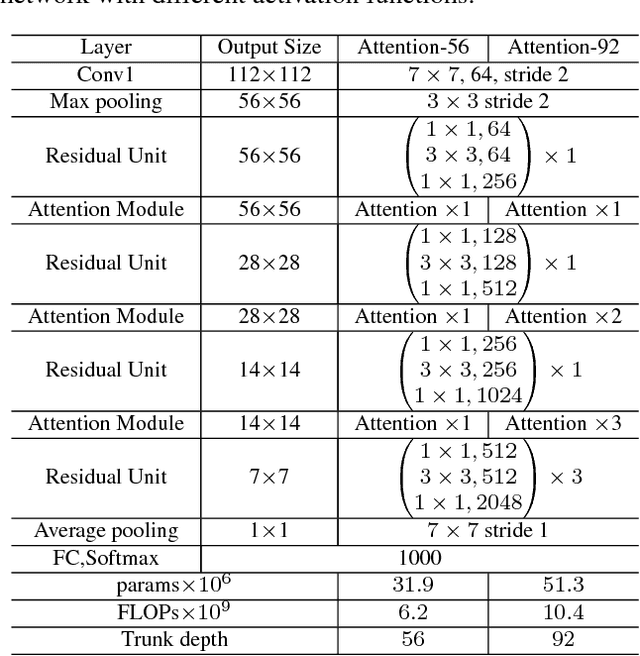
In this work, we propose "Residual Attention Network", a convolutional neural network using attention mechanism which can incorporate with state-of-art feed forward network architecture in an end-to-end training fashion. Our Residual Attention Network is built by stacking Attention Modules which generate attention-aware features. The attention-aware features from different modules change adaptively as layers going deeper. Inside each Attention Module, bottom-up top-down feedforward structure is used to unfold the feedforward and feedback attention process into a single feedforward process. Importantly, we propose attention residual learning to train very deep Residual Attention Networks which can be easily scaled up to hundreds of layers. Extensive analyses are conducted on CIFAR-10 and CIFAR-100 datasets to verify the effectiveness of every module mentioned above. Our Residual Attention Network achieves state-of-the-art object recognition performance on three benchmark datasets including CIFAR-10 (3.90% error), CIFAR-100 (20.45% error) and ImageNet (4.8% single model and single crop, top-5 error). Note that, our method achieves 0.6% top-1 accuracy improvement with 46% trunk depth and 69% forward FLOPs comparing to ResNet-200. The experiment also demonstrates that our network is robust against noisy labels.
ViP-CNN: Visual Phrase Guided Convolutional Neural Network
Apr 10, 2017
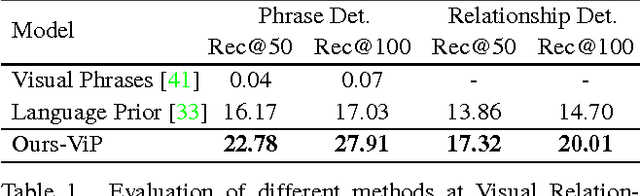
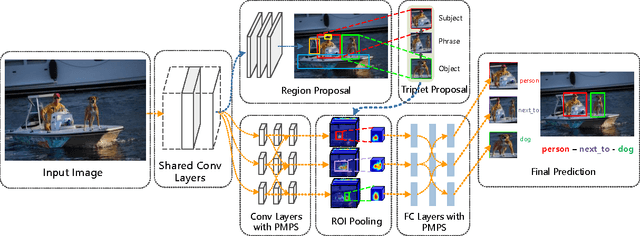
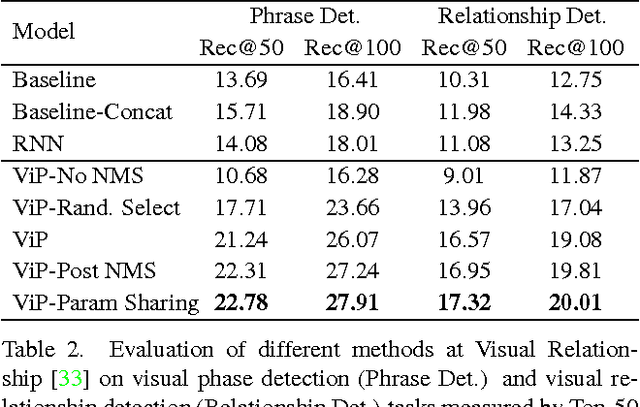
As the intermediate level task connecting image captioning and object detection, visual relationship detection started to catch researchers' attention because of its descriptive power and clear structure. It detects the objects and captures their pair-wise interactions with a subject-predicate-object triplet, e.g. person-ride-horse. In this paper, each visual relationship is considered as a phrase with three components. We formulate the visual relationship detection as three inter-connected recognition problems and propose a Visual Phrase guided Convolutional Neural Network (ViP-CNN) to address them simultaneously. In ViP-CNN, we present a Phrase-guided Message Passing Structure (PMPS) to establish the connection among relationship components and help the model consider the three problems jointly. Corresponding non-maximum suppression method and model training strategy are also proposed. Experimental results show that our ViP-CNN outperforms the state-of-art method both in speed and accuracy. We further pretrain ViP-CNN on our cleansed Visual Genome Relationship dataset, which is found to perform better than the pretraining on the ImageNet for this task.
Object Detection in Videos with Tubelet Proposal Networks
Apr 10, 2017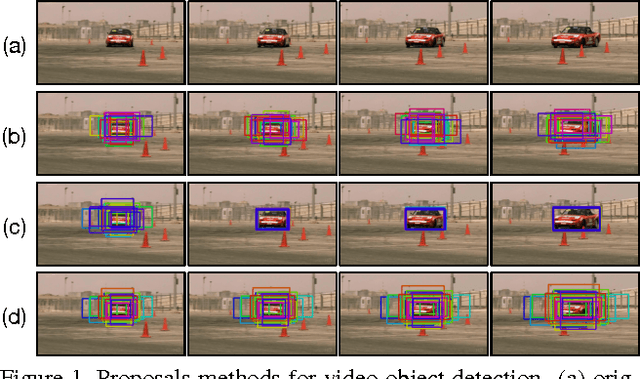
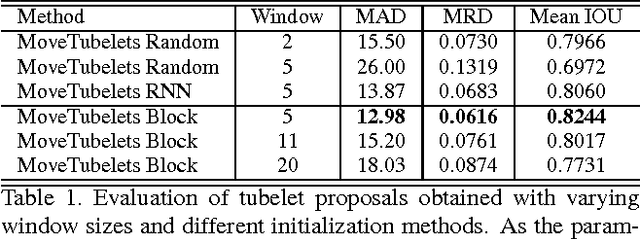
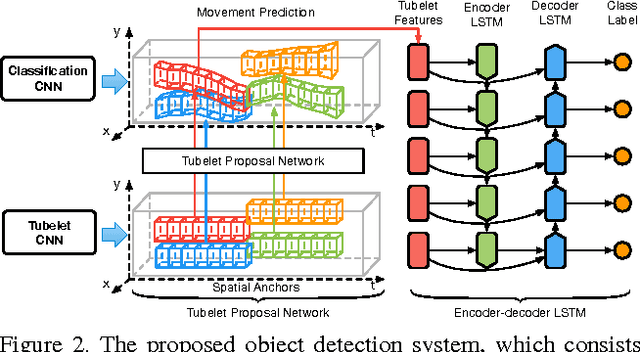
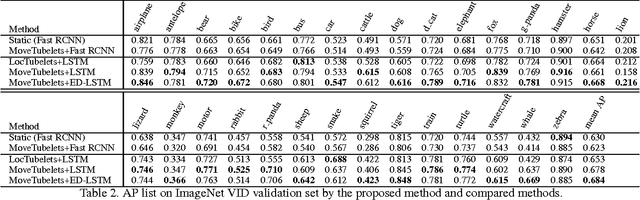
Object detection in videos has drawn increasing attention recently with the introduction of the large-scale ImageNet VID dataset. Different from object detection in static images, temporal information in videos is vital for object detection. To fully utilize temporal information, state-of-the-art methods are based on spatiotemporal tubelets, which are essentially sequences of associated bounding boxes across time. However, the existing methods have major limitations in generating tubelets in terms of quality and efficiency. Motion-based methods are able to obtain dense tubelets efficiently, but the lengths are generally only several frames, which is not optimal for incorporating long-term temporal information. Appearance-based methods, usually involving generic object tracking, could generate long tubelets, but are usually computationally expensive. In this work, we propose a framework for object detection in videos, which consists of a novel tubelet proposal network to efficiently generate spatiotemporal proposals, and a Long Short-term Memory (LSTM) network that incorporates temporal information from tubelet proposals for achieving high object detection accuracy in videos. Experiments on the large-scale ImageNet VID dataset demonstrate the effectiveness of the proposed framework for object detection in videos.