 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelFLoc: Selective Feature Fusion for Large-scale Point Cloud-based Place Recognition
Jun 05, 2023



Point cloud-based place recognition is crucial for mobile robots and autonomous vehicles, especially when the global positioning sensor is not accessible. LiDAR points are scattered on the surface of objects and buildings, which have strong shape priors along different axes. To enhance message passing along particular axes, Stacked Asymmetric Convolution Block (SACB) is designed, which is one of the main contributions in this paper. Comprehensive experiments demonstrate that asymmetric convolution and its corresponding strategies employed by SACB can contribute to the more effective representation of point cloud feature. On this basis, Selective Feature Fusion Block (SFFB), which is formed by stacking point- and channel-wise gating layers in a predefined sequence, is proposed to selectively boost salient local features in certain key regions, as well as to align the features before fusion phase. SACBs and SFFBs are combined to construct a robust and accurate architecture for point cloud-based place recognition, which is termed SelFLoc. Comparative experimental results show that SelFLoc achieves the state-of-the-art (SOTA) performance on the Oxford and other three in-house benchmarks with an improvement of 1.6 absolute percentages on mean average recall@1.
PVT-SSD: Single-Stage 3D Object Detector with Point-Voxel Transformer
May 11, 2023



Recent Transformer-based 3D object detectors learn point cloud features either from point- or voxel-based representations. However, the former requires time-consuming sampling while the latter introduces quantization errors. In this paper, we present a novel Point-Voxel Transformer for single-stage 3D detection (PVT-SSD) that takes advantage of these two representations. Specifically, we first use voxel-based sparse convolutions for efficient feature encoding. Then, we propose a Point-Voxel Transformer (PVT) module that obtains long-range contexts in a cheap manner from voxels while attaining accurate positions from points. The key to associating the two different representations is our introduced input-dependent Query Initialization module, which could efficiently generate reference points and content queries. Then, PVT adaptively fuses long-range contextual and local geometric information around reference points into content queries. Further, to quickly find the neighboring points of reference points, we design the Virtual Range Image module, which generalizes the native range image to multi-sensor and multi-frame. The experiments on several autonomous driving benchmarks verify the effectiveness and efficiency of the proposed method. Code will be available at https://github.com/Nightmare-n/PVT-SSD.
Denoising Multi-modal Sequential Recommenders with Contrastive Learning
May 03, 2023



There is a rapidly-growing research interest in engaging users with multi-modal data for accurate user modeling on recommender systems. Existing multimedia recommenders have achieved substantial improvements by incorporating various modalities and devising delicate modules. However, when users decide to interact with items, most of them do not fully read the content of all modalities. We refer to modalities that directly cause users' behaviors as point-of-interests, which are important aspects to capture users' interests. In contrast, modalities that do not cause users' behaviors are potential noises and might mislead the learning of a recommendation model. Not surprisingly, little research in the literature has been devoted to denoising such potential noises due to the inaccessibility of users' explicit feedback on their point-of-interests. To bridge the gap, we propose a weakly-supervised framework based on contrastive learning for denoising multi-modal recommenders (dubbed Demure). In a weakly-supervised manner, Demure circumvents the requirement of users' explicit feedback and identifies the noises by analyzing the modalities of all interacted items from a given user.
CrossFormer++: A Versatile Vision Transformer Hinging on Cross-scale Attention
Mar 13, 2023



While features of different scales are perceptually important to visual inputs, existing vision transformers do not yet take advantage of them explicitly. To this end, we first propose a cross-scale vision transformer, CrossFormer. It introduces a cross-scale embedding layer (CEL) and a long-short distance attention (LSDA). On the one hand, CEL blends each token with multiple patches of different scales, providing the self-attention module itself with cross-scale features. On the other hand, LSDA splits the self-attention module into a short-distance one and a long-distance counterpart, which not only reduces the computational burden but also keeps both small-scale and large-scale features in the tokens. Moreover, through experiments on CrossFormer, we observe another two issues that affect vision transformers' performance, i.e. the enlarging self-attention maps and amplitude explosion. Thus, we further propose a progressive group size (PGS) paradigm and an amplitude cooling layer (ACL) to alleviate the two issues, respectively. The CrossFormer incorporating with PGS and ACL is called CrossFormer++. Extensive experiments show that CrossFormer++ outperforms the other vision transformers on image classification, object detection, instance segmentation, and semantic segmentation tasks. The code will be available at: https://github.com/cheerss/CrossFormer.
General Rotation Invariance Learning for Point Clouds via Weight-Feature Alignment
Feb 20, 2023



Compared to 2D images, 3D point clouds are much more sensitive to rotations. We expect the point features describing certain patterns to keep invariant to the rotation transformation. There are many recent SOTA works dedicated to rotation-invariant learning for 3D point clouds. However, current rotation-invariant methods lack generalizability on the point clouds in the open scenes due to the reliance on the global distribution, \ie the global scene and backgrounds. Considering that the output activation is a function of the pattern and its orientation, we need to eliminate the effect of the orientation.In this paper, inspired by the idea that the network weights can be considered a set of points distributed in the same 3D space as the input points, we propose Weight-Feature Alignment (WFA) to construct a local Invariant Reference Frame (IRF) via aligning the features with the principal axes of the network weights. Our WFA algorithm provides a general solution for the point clouds of all scenes. WFA ensures the model achieves the target that the response activity is a necessary and sufficient condition of the pattern matching degree. Practically, we perform experiments on the point clouds of both single objects and open large-range scenes. The results suggest that our method almost bridges the gap between rotation invariance learning and normal methods.
CLIP is Also an Efficient Segmenter: A Text-Driven Approach for Weakly Supervised Semantic Segmentation
Dec 20, 2022



Weakly supervised semantic segmentation (WSSS) with image-level labels is a challenging task in computer vision. Mainstream approaches follow a multi-stage framework and suffer from high training costs. In this paper, we explore the potential of Contrastive Language-Image Pre-training models (CLIP) to localize different categories with only image-level labels and without any further training. To efficiently generate high-quality segmentation masks from CLIP, we propose a novel framework called CLIP-ES for WSSS. Our framework improves all three stages of WSSS with special designs for CLIP: 1) We introduce the softmax function into GradCAM and exploit the zero-shot ability of CLIP to suppress the confusion caused by non-target classes and backgrounds. Meanwhile, to take full advantage of CLIP, we re-explore text inputs under the WSSS setting and customize two text-driven strategies: sharpness-based prompt selection and synonym fusion. 2) To simplify the stage of CAM refinement, we propose a real-time class-aware attention-based affinity (CAA) module based on the inherent multi-head self-attention (MHSA) in CLIP-ViTs. 3) When training the final segmentation model with the masks generated by CLIP, we introduced a confidence-guided loss (CGL) to mitigate noise and focus on confident regions. Our proposed framework dramatically reduces the cost of training for WSSS and shows the capability of localizing objects in CLIP. Our CLIP-ES achieves SOTA performance on Pascal VOC 2012 and MS COCO 2014 while only taking 10% time of previous methods for the pseudo mask generation. Code is available at https://github.com/linyq2117/CLIP-ES.
GD-MAE: Generative Decoder for MAE Pre-training on LiDAR Point Clouds
Dec 07, 2022Despite the tremendous progress of Masked Autoencoders (MAE) in developing vision tasks such as image and video, exploring MAE in large-scale 3D point clouds remains challenging due to the inherent irregularity. In contrast to previous 3D MAE frameworks, which either design a complex decoder to infer masked information from maintained regions or adopt sophisticated masking strategies, we instead propose a much simpler paradigm. The core idea is to apply a \textbf{G}enerative \textbf{D}ecoder for MAE (GD-MAE) to automatically merges the surrounding context to restore the masked geometric knowledge in a hierarchical fusion manner. In doing so, our approach is free from introducing the heuristic design of decoders and enjoys the flexibility of exploring various masking strategies. The corresponding part costs less than \textbf{12\%} latency compared with conventional methods, while achieving better performance. We demonstrate the efficacy of the proposed method on several large-scale benchmarks: Waymo, KITTI, and ONCE. Consistent improvement on downstream detection tasks illustrates strong robustness and generalization capability. Not only our method reveals state-of-the-art results, but remarkably, we achieve comparable accuracy even with \textbf{20\%} of the labeled data on the Waymo dataset. The code will be released at \url{https://github.com/Nightmare-n/GD-MAE}.
PriorLane: A Prior Knowledge Enhanced Lane Detection Approach Based on Transformer
Sep 15, 2022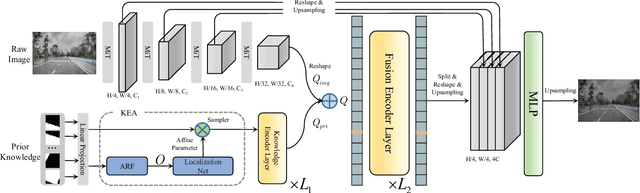
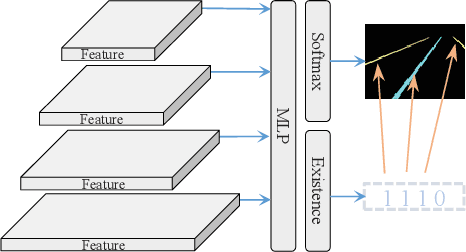

Lane detection is one of the fundamental modules in self-driving. In this paper we employ a transformer-only method for lane detection, thus it could benefit from the blooming development of fully vision transformer and achieves the state-of-the-art (SOTA) performance on both CULane and TuSimple benchmarks, by fine-tuning the weight fully pre-trained on large datasets. More importantly, this paper proposes a novel and general framework called PriorLane, which is used to enhance the segmentation performance of the fully vision transformer by introducing the low-cost local prior knowledge. PriorLane utilizes an encoder-only transformer to fuse the feature extracted by a pre-trained segmentation model with prior knowledge embeddings. Note that a Knowledge Embedding Alignment (KEA) module is adapted to enhance the fusion performance by aligning the knowledge embedding. Extensive experiments on our Zjlab dataset show that Prior-Lane outperforms SOTA lane detection methods by a 2.82% mIoU, and the code will be released at: https://github. com/vincentqqb/PriorLane.
Towards In-distribution Compatibility in Out-of-distribution Detection
Aug 29, 2022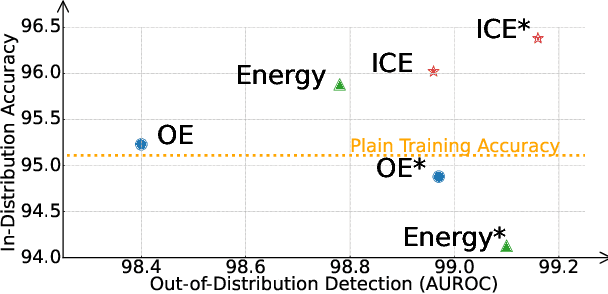
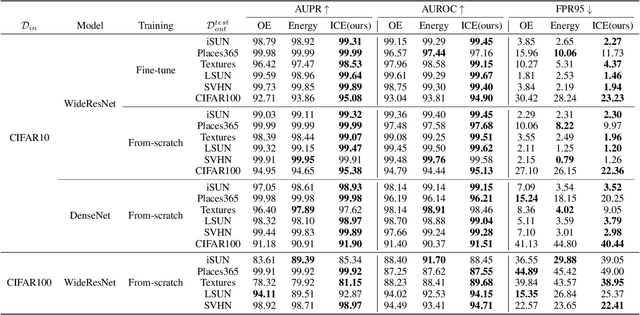
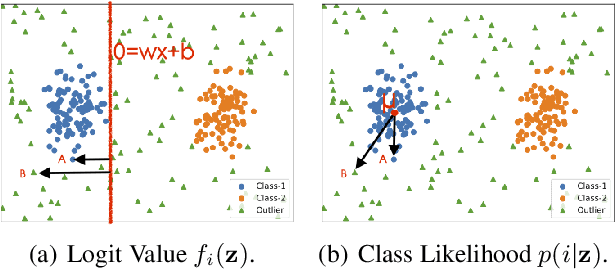
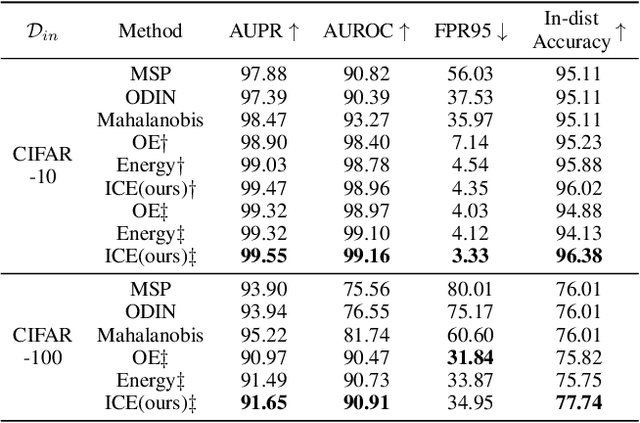
Deep neural network, despite its remarkable capability of discriminating targeted in-distribution samples, shows poor performance on detecting anomalous out-of-distribution data. To address this defect, state-of-the-art solutions choose to train deep networks on an auxiliary dataset of outliers. Various training criteria for these auxiliary outliers are proposed based on heuristic intuitions. However, we find that these intuitively designed outlier training criteria can hurt in-distribution learning and eventually lead to inferior performance. To this end, we identify three causes of the in-distribution incompatibility: contradictory gradient, false likelihood, and distribution shift. Based on our new understandings, we propose a new out-of-distribution detection method by adapting both the top-design of deep models and the loss function. Our method achieves in-distribution compatibility by pursuing less interference with the probabilistic characteristic of in-distribution features. On several benchmarks, our method not only achieves the state-of-the-art out-of-distribution detection performance but also improves the in-distribution accuracy.
CCL4Rec: Contrast over Contrastive Learning for Micro-video Recommendation
Aug 17, 2022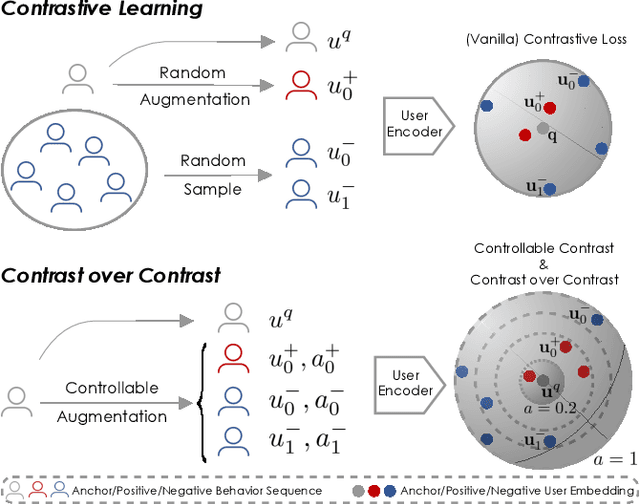

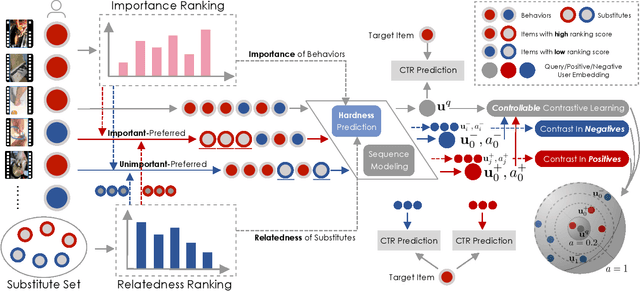
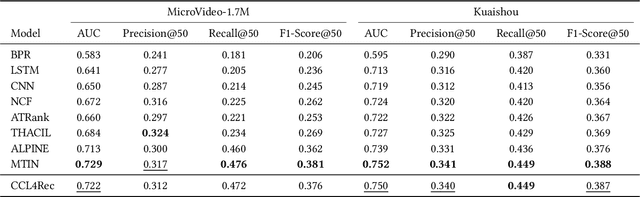
Micro-video recommender systems suffer from the ubiquitous noises in users' behaviors, which might render the learned user representation indiscriminating, and lead to trivial recommendations (e.g., popular items) or even weird ones that are far beyond users' interests. Contrastive learning is an emergent technique for learning discriminating representations with random data augmentations. However, due to neglecting the noises in user behaviors and treating all augmented samples equally, the existing contrastive learning framework is insufficient for learning discriminating user representations in recommendation. To bridge this research gap, we propose the Contrast over Contrastive Learning framework for training recommender models, named CCL4Rec, which models the nuances of different augmented views by further contrasting augmented positives/negatives with adaptive pulling/pushing strengths, i.e., the contrast over (vanilla) contrastive learning. To accommodate these contrasts, we devise the hardness-aware augmentations that track the importance of behaviors being replaced in the query user and the relatedness of substitutes, and thus determining the quality of augmented positives/negatives. The hardness-aware augmentation also permits controllable contrastive learning, leading to performance gains and robust training. In this way, CCL4Rec captures the nuances of historical behaviors for a given user, which explicitly shields off the learned user representation from the effects of noisy behaviors. We conduct extensive experiments on two micro-video recommendation benchmarks, which demonstrate that CCL4Rec with far less model parameters could achieve comparable performance to existing state-of-the-art method, and improve the training/inference speed by several orders of magnitude.