 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstructing MODIS Normalized Difference Snow Index Product on Greenland Ice Sheet Using Spatiotemporal Extreme Gradient Boosting Model
Nov 03, 2024



The spatiotemporally continuous data of normalized difference snow index (NDSI) are key to understanding the mechanisms of snow occurrence and development as well as the patterns of snow distribution changes. However, the presence of clouds, particularly prevalent in polar regions such as the Greenland Ice Sheet (GrIS), introduces a significant number of missing pixels in the MODIS NDSI daily data. To address this issue, this study proposes the utilization of a spatiotemporal extreme gradient boosting (STXGBoost) model generate a comprehensive NDSI dataset. In the proposed model, various input variables are carefully selected, encompassing terrain features, geometry-related parameters, and surface property variables. Moreover, the model incorporates spatiotemporal variation information, enhancing its capacity for reconstructing the NDSI dataset. Verification results demonstrate the efficacy of the STXGBoost model, with a coefficient of determination of 0.962, root mean square error of 0.030, mean absolute error of 0.011, and negligible bias (0.0001). Furthermore, simulation comparisons involving missing data and cross-validation with Landsat NDSI data illustrate the model's capability to accurately reconstruct the spatial distribution of NDSI data. Notably, the proposed model surpasses the performance of traditional machine learning models, showcasing superior NDSI predictive capabilities. This study highlights the potential of leveraging auxiliary data to reconstruct NDSI in GrIS, with implications for broader applications in other regions. The findings offer valuable insights for the reconstruction of NDSI remote sensing data, contributing to the further understanding of spatiotemporal dynamics in snow-covered regions.
STS MICCAI 2023 Challenge: Grand challenge on 2D and 3D semi-supervised tooth segmentation
Jul 18, 2024



Computer-aided design (CAD) tools are increasingly popular in modern dental practice, particularly for treatment planning or comprehensive prognosis evaluation. In particular, the 2D panoramic X-ray image efficiently detects invisible caries, impacted teeth and supernumerary teeth in children, while the 3D dental cone beam computed tomography (CBCT) is widely used in orthodontics and endodontics due to its low radiation dose. However, there is no open-access 2D public dataset for children's teeth and no open 3D dental CBCT dataset, which limits the development of automatic algorithms for segmenting teeth and analyzing diseases. The Semi-supervised Teeth Segmentation (STS) Challenge, a pioneering event in tooth segmentation, was held as a part of the MICCAI 2023 ToothFairy Workshop on the Alibaba Tianchi platform. This challenge aims to investigate effective semi-supervised tooth segmentation algorithms to advance the field of dentistry. In this challenge, we provide two modalities including the 2D panoramic X-ray images and the 3D CBCT tooth volumes. In Task 1, the goal was to segment tooth regions in panoramic X-ray images of both adult and pediatric teeth. Task 2 involved segmenting tooth sections using CBCT volumes. Limited labelled images with mostly unlabelled ones were provided in this challenge prompt using semi-supervised algorithms for training. In the preliminary round, the challenge received registration and result submission by 434 teams, with 64 advancing to the final round. This paper summarizes the diverse methods employed by the top-ranking teams in the STS MICCAI 2023 Challenge.
Identification and classification of exfoliated graphene flakes from microscopy images using a hierarchical deep convolutional neural network
Mar 29, 2022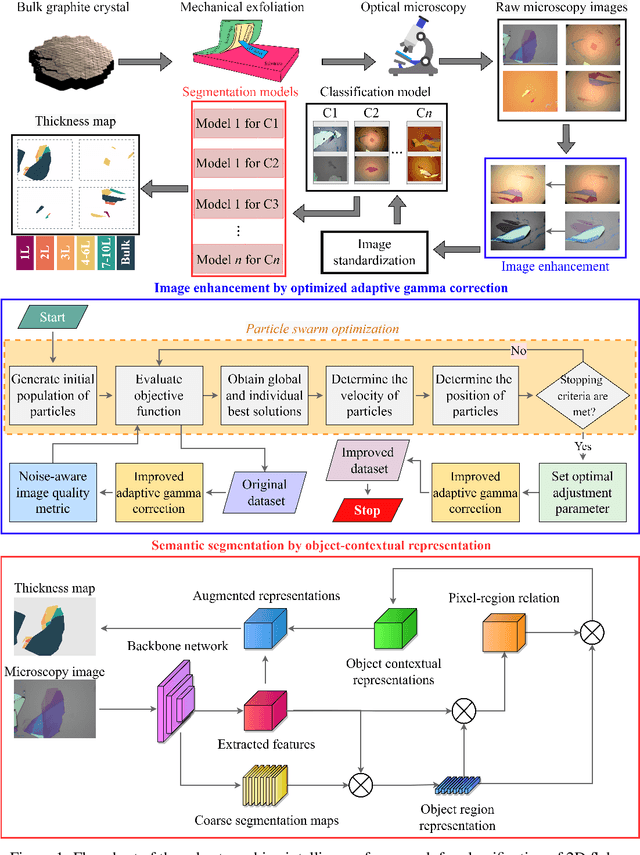
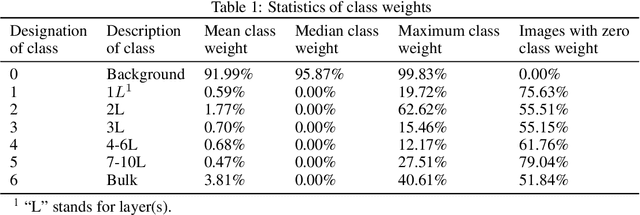
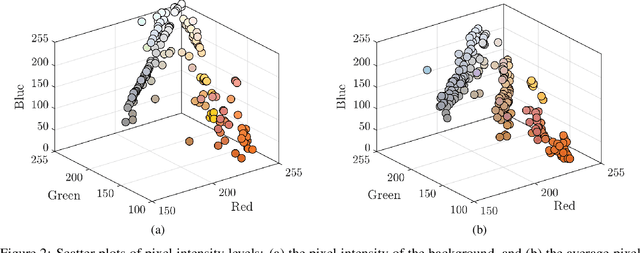
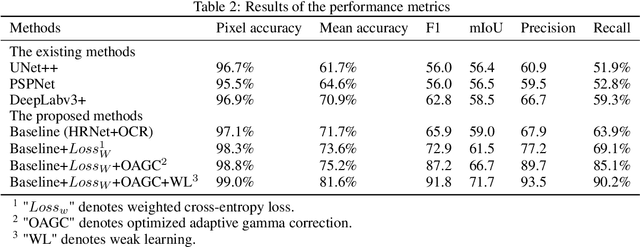
Identification of the mechanically exfoliated graphene flakes and classification of the thickness is important in the nanomanufacturing of next-generation materials and devices that overcome the bottleneck of Moore's Law. Currently, identification and classification of exfoliated graphene flakes are conducted by human via inspecting the optical microscope images. The existing state-of-the-art automatic identification by machine learning is not able to accommodate images with different backgrounds while different backgrounds are unavoidable in experiments. This paper presents a deep learning method to automatically identify and classify the thickness of exfoliated graphene flakes on Si/SiO2 substrates from optical microscope images with various settings and background colors. The presented method uses a hierarchical deep convolutional neural network that is capable of learning new images while preserving the knowledge from previous images. The deep learning model was trained and used to classify exfoliated graphene flakes into monolayer (1L), bi-layer (2L), tri-layer (3L), four-to-six-layer (4-6L), seven-to-ten-layer (7-10L), and bulk categories. Compared with existing machine learning methods, the presented method possesses high accuracy and efficiency as well as robustness to the backgrounds and resolutions of images. The results indicated that our deep learning model has accuracy as high as 99% in identifying and classifying exfoliated graphene flakes. This research will shed light on scaled-up manufacturing and characterization of graphene for advanced materials and devices.
GFTE: Graph-based Financial Table Extraction
Mar 17, 2020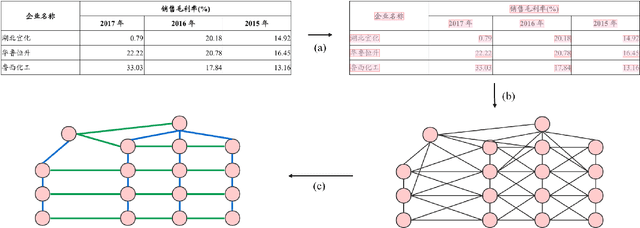
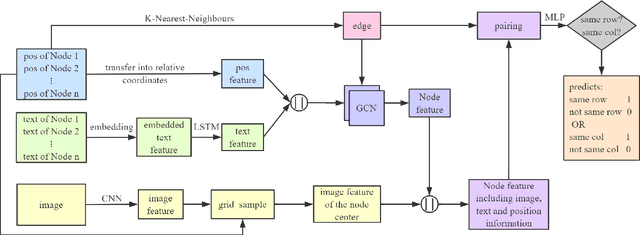
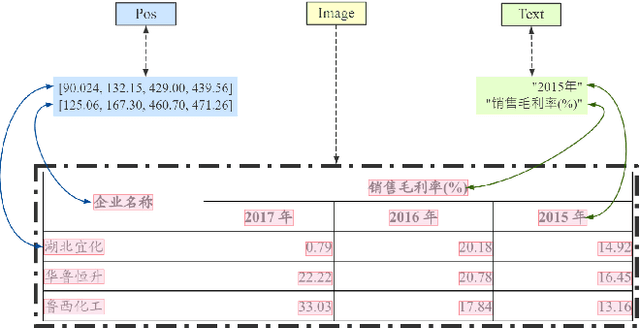
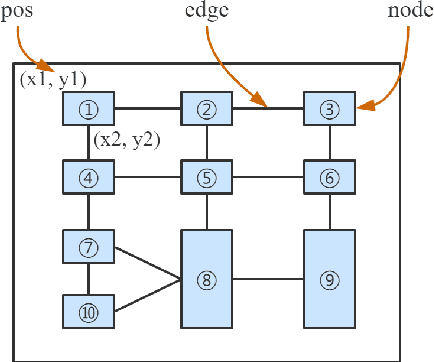
Tabular data is a crucial form of information expression, which can organize data in a standard structure for easy information retrieval and comparison. However, in financial industry and many other fields tables are often disclosed in unstructured digital files, e.g. Portable Document Format (PDF) and images, which are difficult to be extracted directly. In this paper, to facilitate deep learning based table extraction from unstructured digital files, we publish a standard Chinese dataset named FinTab, which contains more than 1,600 financial tables of diverse kinds and their corresponding structure representation in JSON. In addition, we propose a novel graph-based convolutional neural network model named GFTE as a baseline for future comparison. GFTE integrates image feature, position feature and textual feature together for precise edge prediction and reaches overall good results.