 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dynamic Fuzzy Rule and Attribute Management Framework for Fuzzy Inference Systems in High-Dimensional Data
Apr 27, 2025This paper presents an Adaptive Dynamic Attribute and Rule (ADAR) framework designed to address the challenges posed by high-dimensional data in neuro-fuzzy inference systems. By integrating dual weighting mechanisms-assigning adaptive importance to both attributes and rules-together with automated growth and pruning strategies, ADAR adaptively streamlines complex fuzzy models without sacrificing performance or interpretability. Experimental evaluations on four diverse datasets - Auto MPG (7 variables), Beijing PM2.5 (10 variables), Boston Housing (13 variables), and Appliances Energy Consumption (27 variables) show that ADAR-based models achieve consistently lower Root Mean Square Error (RMSE) compared to state-of-the-art baselines. On the Beijing PM2.5 dataset, for instance, ADAR-SOFENN attained an RMSE of 56.87 with nine rules, surpassing traditional ANFIS [12] and SOFENN [16] models. Similarly, on the high-dimensional Appliances Energy dataset, ADAR-ANFIS reached an RMSE of 83.25 with nine rules, outperforming established fuzzy logic approaches and interpretability-focused methods such as APLR. Ablation studies further reveal that combining rule-level and attribute-level weight assignment significantly reduces model overlap while preserving essential features, thereby enhancing explainability. These results highlight ADAR's effectiveness in dynamically balancing rule complexity and feature importance, paving the way for scalable, high-accuracy, and transparent neuro-fuzzy systems applicable to a range of real-world scenarios.
Residual Learning Inspired Crossover Operator and Strategy Enhancements for Evolutionary Multitasking
Mar 27, 2025



In evolutionary multitasking, strategies such as crossover operators and skill factor assignment are critical for effective knowledge transfer. Existing improvements to crossover operators primarily focus on low-dimensional variable combinations, such as arithmetic crossover or partially mapped crossover, which are insufficient for modeling complex high-dimensional interactions.Moreover, static or semi-dynamic crossover strategies fail to adapt to the dynamic dependencies among tasks. In addition, current Multifactorial Evolutionary Algorithm frameworks often rely on fixed skill factor assignment strategies, lacking flexibility. To address these limitations, this paper proposes the Multifactorial Evolutionary Algorithm-Residual Learning (MFEA-RL) method based on residual learning. The method employs a Very Deep Super-Resolution (VDSR) model to generate high-dimensional residual representations of individuals, enhancing the modeling of complex relationships within dimensions. A ResNet-based mechanism dynamically assigns skill factors to improve task adaptability, while a random mapping mechanism efficiently performs crossover operations and mitigates the risk of negative transfer. Theoretical analysis and experimental results show that MFEA-RL outperforms state-of-the-art multitasking algorithms. It excels in both convergence and adaptability on standard evolutionary multitasking benchmarks, including CEC2017-MTSO and WCCI2020-MTSO. Additionally, its effectiveness is validated through a real-world application scenario.
Enhanced Particle Swarm Optimization Algorithms for Multiple-Input Multiple-Output System Modelling using Convolved Gaussian Process Models
Jul 12, 2017
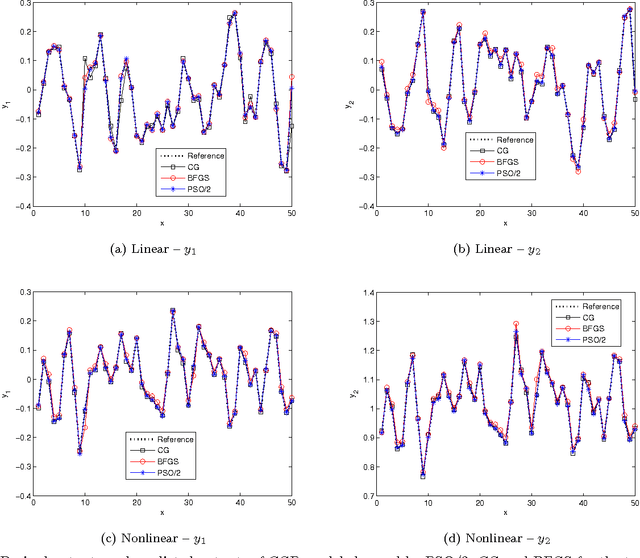
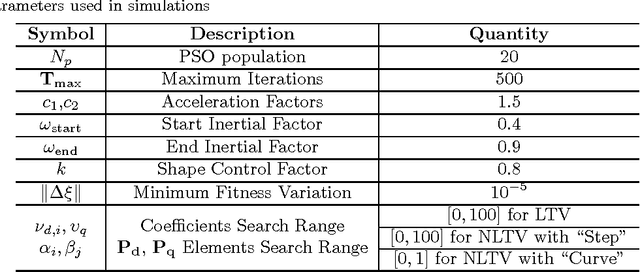
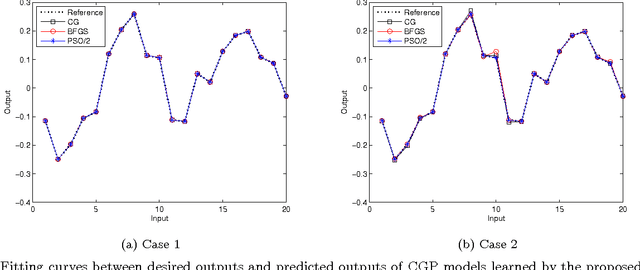
Convolved Gaussian Process (CGP) is able to capture the correlations not only between inputs and outputs but also among the outputs. This allows a superior performance of using CGP than standard Gaussian Process (GP) in the modelling of Multiple-Input Multiple-Output (MIMO) systems when observations are missing for some of outputs. Similar to standard GP, a key issue of CGP is the learning of hyperparameters from a set of input-output observations. It typically performed by maximizing the Log-Likelihood (LL) function which leads to an unconstrained nonlinear and non-convex optimization problem. Algorithms such as Conjugate Gradient (CG) or Broyden-Fletcher-Goldfarb-Shanno (BFGS) are commonly used but they often get stuck in local optima, especially for CGP where there are more hyperparameters. In addition, the LL value is not a reliable indicator for judging the quality intermediate models in the optimization process. In this paper, we propose to use enhanced Particle Swarm Optimization (PSO) algorithms to solve this problem by minimizing the model output error instead. This optimization criterion enables the quality of intermediate solutions to be directly observable during the optimization process. Two enhancements to the standard PSO algorithm which make use of gradient information and the multi- start technique are proposed. Simulation results on the modelling of both linear and nonlinear systems demonstrate the effectiveness of minimizing the model output error to learn hyperparameters and the performance of using enhanced algorithms.