 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Pretrained Structured Transformers: Unsupervised Syntactic Language Models at Scale
Mar 18, 2024A syntactic language model (SLM) incrementally generates a sentence with its syntactic tree in a left-to-right manner. We present Generative Pretrained Structured Transformers (GPST), an unsupervised SLM at scale capable of being pre-trained from scratch on raw texts with high parallelism. GPST circumvents the limitations of previous SLMs such as relying on gold trees and sequential training. It consists of two components, a usual SLM supervised by a uni-directional language modeling loss, and an additional composition model, which induces syntactic parse trees and computes constituent representations, supervised by a bi-directional language modeling loss. We propose a representation surrogate to enable joint parallel training of the two models in a hard-EM fashion. We pre-train GPST on OpenWebText, a corpus with $9$ billion tokens, and demonstrate the superiority of GPST over GPT-2 with a comparable size in numerous tasks covering both language understanding and language generation. Meanwhile, GPST also significantly outperforms existing unsupervised SLMs on left-to-right grammar induction, while holding a substantial acceleration on training.
"In Dialogues We Learn": Towards Personalized Dialogue Without Pre-defined Profiles through In-Dialogue Learning
Mar 12, 2024



Personalized dialogue systems have gained significant attention in recent years for their ability to generate responses in alignment with different personas. However, most existing approaches rely on pre-defined personal profiles, which are not only time-consuming and labor-intensive to create but also lack flexibility. We propose In-Dialogue Learning (IDL), a fine-tuning framework that enhances the ability of pre-trained large language models to leverage dialogue history to characterize persona for completing personalized dialogue generation tasks without pre-defined profiles. Our experiments on three datasets demonstrate that IDL brings substantial improvements, with BLEU and ROUGE scores increasing by up to 200% and 247%, respectively. Additionally, the results of human evaluations further validate the efficacy of our proposed method.
HoloVIC: Large-scale Dataset and Benchmark for Multi-Sensor Holographic Intersection and Vehicle-Infrastructure Cooperative
Mar 06, 2024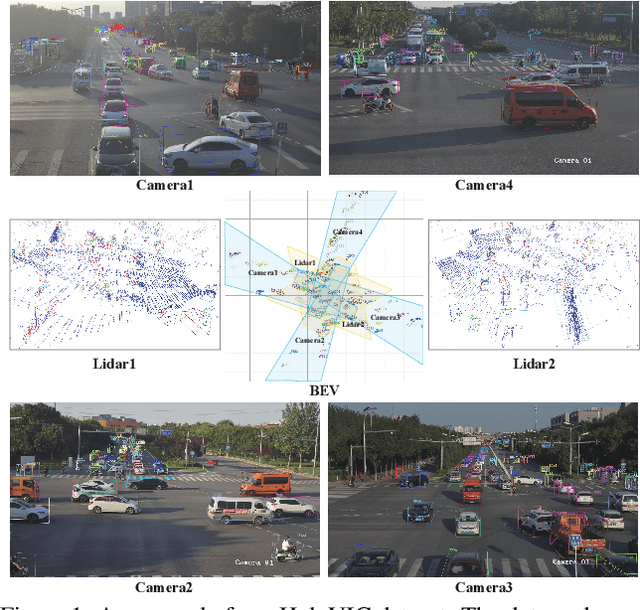
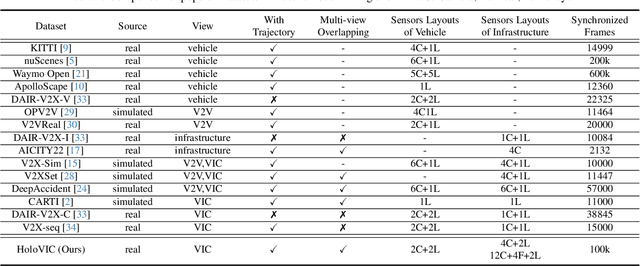
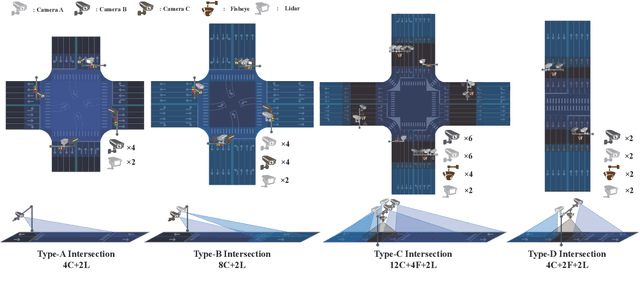
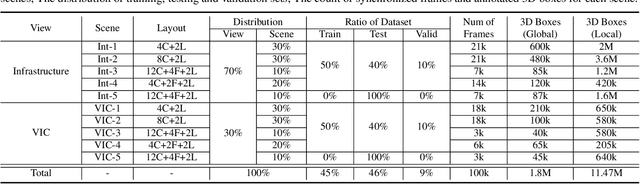
Vehicle-to-everything (V2X) is a popular topic in the field of Autonomous Driving in recent years. Vehicle-infrastructure cooperation (VIC) becomes one of the important research area. Due to the complexity of traffic conditions such as blind spots and occlusion, it greatly limits the perception capabilities of single-view roadside sensing systems. To further enhance the accuracy of roadside perception and provide better information to the vehicle side, in this paper, we constructed holographic intersections with various layouts to build a large-scale multi-sensor holographic vehicle-infrastructure cooperation dataset, called HoloVIC. Our dataset includes 3 different types of sensors (Camera, Lidar, Fisheye) and employs 4 sensor-layouts based on the different intersections. Each intersection is equipped with 6-18 sensors to capture synchronous data. While autonomous vehicles pass through these intersections for collecting VIC data. HoloVIC contains in total on 100k+ synchronous frames from different sensors. Additionally, we annotated 3D bounding boxes based on Camera, Fisheye, and Lidar. We also associate the IDs of the same objects across different devices and consecutive frames in sequence. Based on HoloVIC, we formulated four tasks to facilitate the development of related research. We also provide benchmarks for these tasks.
Intent-aware Recommendation via Disentangled Graph Contrastive Learning
Mar 06, 2024



Graph neural network (GNN) based recommender systems have become one of the mainstream trends due to the powerful learning ability from user behavior data. Understanding the user intents from behavior data is the key to recommender systems, which poses two basic requirements for GNN-based recommender systems. One is how to learn complex and diverse intents especially when the user behavior is usually inadequate in reality. The other is different behaviors have different intent distributions, so how to establish their relations for a more explainable recommender system. In this paper, we present the Intent-aware Recommendation via Disentangled Graph Contrastive Learning (IDCL), which simultaneously learns interpretable intents and behavior distributions over those intents. Specifically, we first model the user behavior data as a user-item-concept graph, and design a GNN based behavior disentangling module to learn the different intents. Then we propose the intent-wise contrastive learning to enhance the intent disentangling and meanwhile infer the behavior distributions. Finally, the coding rate reduction regularization is introduced to make the behaviors of different intents orthogonal. Extensive experiments demonstrate the effectiveness of IDCL in terms of substantial improvement and the interpretability.
* Accepted by IJCAI 2023
Demographic Bias of Expert-Level Vision-Language Foundation Models in Medical Imaging
Feb 22, 2024



Advances in artificial intelligence (AI) have achieved expert-level performance in medical imaging applications. Notably, self-supervised vision-language foundation models can detect a broad spectrum of pathologies without relying on explicit training annotations. However, it is crucial to ensure that these AI models do not mirror or amplify human biases, thereby disadvantaging historically marginalized groups such as females or Black patients. The manifestation of such biases could systematically delay essential medical care for certain patient subgroups. In this study, we investigate the algorithmic fairness of state-of-the-art vision-language foundation models in chest X-ray diagnosis across five globally-sourced datasets. Our findings reveal that compared to board-certified radiologists, these foundation models consistently underdiagnose marginalized groups, with even higher rates seen in intersectional subgroups, such as Black female patients. Such demographic biases present over a wide range of pathologies and demographic attributes. Further analysis of the model embedding uncovers its significant encoding of demographic information. Deploying AI systems with these biases in medical imaging can intensify pre-existing care disparities, posing potential challenges to equitable healthcare access and raising ethical questions about their clinical application.
Human Aesthetic Preference-Based Large Text-to-Image Model Personalization: Kandinsky Generation as an Example
Feb 09, 2024With the advancement of neural generative capabilities, the art community has actively embraced GenAI (generative artificial intelligence) for creating painterly content. Large text-to-image models can quickly generate aesthetically pleasing outcomes. However, the process can be non-deterministic and often involves tedious trial-and-error, as users struggle with formulating effective prompts to achieve their desired results. This paper introduces a prompting-free generative approach that empowers users to automatically generate personalized painterly content that incorporates their aesthetic preferences in a customized artistic style. This approach involves utilizing ``semantic injection'' to customize an artist model in a specific artistic style, and further leveraging a genetic algorithm to optimize the prompt generation process through real-time iterative human feedback. By solely relying on the user's aesthetic evaluation and preference for the artist model-generated images, this approach creates the user a personalized model that encompasses their aesthetic preferences and the customized artistic style.
AMOR: A Recipe for Building Adaptable Modular Knowledge Agents Through Process Feedback
Feb 02, 2024



The notable success of large language models (LLMs) has sparked an upsurge in building language agents to complete various complex tasks. We present AMOR, an agent framework based on open-source LLMs, which reasons with external knowledge bases and adapts to specific domains through human supervision to the reasoning process. AMOR builds reasoning logic over a finite state machine (FSM) that solves problems through autonomous executions and transitions over disentangled modules. This allows humans to provide direct feedback to the individual modules, and thus naturally forms process supervision. Based on this reasoning and feedback framework, we develop AMOR through two-stage fine-tuning: warm-up and adaptation. The former fine-tunes the LLM with examples automatically constructed from various public datasets and enables AMOR to generalize across different knowledge environments, while the latter tailors AMOR to specific domains using process feedback. Extensive experiments across multiple domains demonstrate the advantage of AMOR to strong baselines, thanks to its FSM-based reasoning and process feedback mechanism.
TagAlign: Improving Vision-Language Alignment with Multi-Tag Classification
Dec 26, 2023



The crux of learning vision-language models is to extract semantically aligned information from visual and linguistic data. Existing attempts usually face the problem of coarse alignment, e.g., the vision encoder struggles in localizing an attribute-specified object. In this work, we propose an embarrassingly simple approach to better align image and text features with no need of additional data formats other than image-text pairs. Concretely, given an image and its paired text, we manage to parse objects (e.g., cat) and attributes (e.g., black) from the description, which are highly likely to exist in the image. It is noteworthy that the parsing pipeline is fully automatic and thus enjoys good scalability. With these parsed semantics as supervision signals, we can complement the commonly used image-text contrastive loss with the multi-tag classification loss. Extensive experimental results on a broad suite of semantic segmentation datasets substantiate the average 3.65\% improvement of our framework over existing alternatives. Furthermore, the visualization results indicate that attribute supervision makes vision-language models accurately localize attribute-specified objects. Project page and code can be found at https://qinying-liu.github.io/Tag-Align.
Hybrid Hierarchical DRL Enabled Resource Allocation for Secure Transmission in Multi-IRS-Assisted Sensing-Enhanced Spectrum Sharing Networks
Dec 02, 2023



Secure communications are of paramount importance in spectrum sharing networks due to the allocation and sharing characteristics of spectrum resources. To further explore the potential of intelligent reflective surfaces (IRSs) in enhancing spectrum sharing and secure transmission performance, a multiple intelligent reflection surface (multi-IRS)-assisted sensing-enhanced wideband spectrum sharing network is investigated by considering physical layer security techniques. An intelligent resource allocation scheme based on double deep Q networks (D3QN) algorithm and soft Actor-Critic (SAC) algorithm is proposed to maximize the secure transmission rate of the secondary network by jointly optimizing IRS pairings, subchannel assignment, transmit beamforming of the secondary base station, reflection coefficients of IRSs and the sensing time. To tackle the sparse reward problem caused by a significant amount of reflection elements of multiple IRSs, the method of hierarchical reinforcement learning is exploited. An alternative optimization (AO)-based conventional mathematical scheme is introduced to verify the computational complexity advantage of our proposed intelligent scheme. Simulation results demonstrate the efficiency of our proposed intelligent scheme as well as the superiority of multi-IRS design in enhancing secrecy rate and spectrum utilization. It is shown that inappropriate deployment of IRSs can reduce the security performance with the presence of multiple eavesdroppers (Eves), and the arrangement of IRSs deserves further consideration.
Adaptive Resource Allocation for Semantic Communication Networks
Dec 02, 2023Semantic communication, recognized as a promising technology for future intelligent applications, has received widespread research attention. Despite the potential of semantic communication to enhance transmission reliability, especially in low signal-to-noise (SNR) environments, the critical issue of resource allocation and compatibility in the dynamic wireless environment remains largely unexplored. In this paper, we propose an adaptive semantic resource allocation paradigm with semantic-bit quantization (SBQ) compatibly for existing wireless communications, where the inaccurate environment perception introduced by the additional mapping relationship between semantic metrics and transmission metrics is solved. In order to investigate the performance of semantic communication networks, the quality of service for semantic communication (SC-QoS), including the semantic quantization efficiency (SQE) and transmission latency, is proposed for the first time. A problem of maximizing the overall effective SC-QoS is formulated by jointly optimizing the transmit beamforming of the base station, the bits for semantic representation, the subchannel assignment, and the bandwidth resource allocation. To address the non-convex formulated problem, an intelligent resource allocation scheme is proposed based on a hybrid deep reinforcement learning (DRL) algorithm, where the intelligent agent can perceive both semantic tasks and dynamic wireless environments. Simulation results demonstrate that our design can effectively combat semantic noise and achieve superior performance in wireless communications compared to several benchmark schemes. Furthermore, compared to mapping-guided paradigm based resource allocation schemes, our proposed adaptive scheme can achieve up to 13% performance improvement in terms of SC-QoS.