 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Segmentation with Semantics
Jan 30, 2023



We propose a new problem called audio-visual segmentation (AVS), in which the goal is to output a pixel-level map of the object(s) that produce sound at the time of the image frame. To facilitate this research, we construct the first audio-visual segmentation benchmark, i.e., AVSBench, providing pixel-wise annotations for sounding objects in audible videos. It contains three subsets: AVSBench-object (Single-source subset, Multi-sources subset) and AVSBench-semantic (Semantic-labels subset). Accordingly, three settings are studied: 1) semi-supervised audio-visual segmentation with a single sound source; 2) fully-supervised audio-visual segmentation with multiple sound sources, and 3) fully-supervised audio-visual semantic segmentation. The first two settings need to generate binary masks of sounding objects indicating pixels corresponding to the audio, while the third setting further requires generating semantic maps indicating the object category. To deal with these problems, we propose a new baseline method that uses a temporal pixel-wise audio-visual interaction module to inject audio semantics as guidance for the visual segmentation process. We also design a regularization loss to encourage audio-visual mapping during training. Quantitative and qualitative experiments on AVSBench compare our approach to several existing methods for related tasks, demonstrating that the proposed method is promising for building a bridge between the audio and pixel-wise visual semantics. Code is available at https://github.com/OpenNLPLab/AVSBench. Online benchmark is available at http://www.avlbench.opennlplab.cn.
MegaPose: 6D Pose Estimation of Novel Objects via Render & Compare
Dec 13, 2022



We introduce MegaPose, a method to estimate the 6D pose of novel objects, that is, objects unseen during training. At inference time, the method only assumes knowledge of (i) a region of interest displaying the object in the image and (ii) a CAD model of the observed object. The contributions of this work are threefold. First, we present a 6D pose refiner based on a render&compare strategy which can be applied to novel objects. The shape and coordinate system of the novel object are provided as inputs to the network by rendering multiple synthetic views of the object's CAD model. Second, we introduce a novel approach for coarse pose estimation which leverages a network trained to classify whether the pose error between a synthetic rendering and an observed image of the same object can be corrected by the refiner. Third, we introduce a large-scale synthetic dataset of photorealistic images of thousands of objects with diverse visual and shape properties and show that this diversity is crucial to obtain good generalization performance on novel objects. We train our approach on this large synthetic dataset and apply it without retraining to hundreds of novel objects in real images from several pose estimation benchmarks. Our approach achieves state-of-the-art performance on the ModelNet and YCB-Video datasets. An extensive evaluation on the 7 core datasets of the BOP challenge demonstrates that our approach achieves performance competitive with existing approaches that require access to the target objects during training. Code, dataset and trained models are available on the project page: https://megapose6d.github.io/.
Parallel Inversion of Neural Radiance Fields for Robust Pose Estimation
Oct 18, 2022

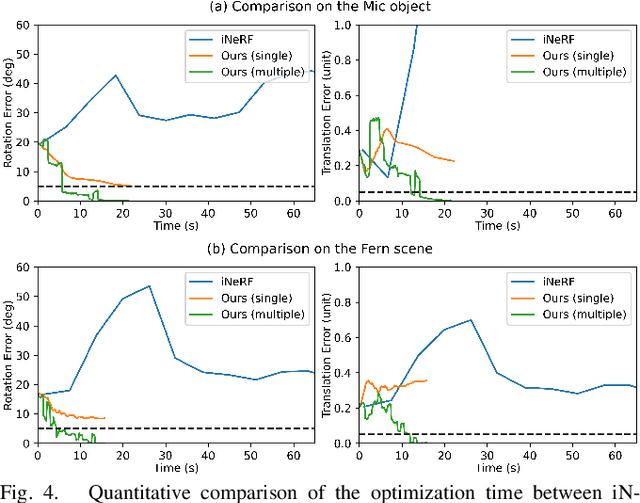

We present a parallelized optimization method based on fast Neural Radiance Fields (NeRF) for estimating 6-DoF target poses. Given a single observed RGB image of the target, we can predict the translation and rotation of the camera by minimizing the residual between pixels rendered from a fast NeRF model and pixels in the observed image. We integrate a momentum-based camera extrinsic optimization procedure into Instant Neural Graphics Primitives, a recent exceptionally fast NeRF implementation. By introducing parallel Monte Carlo sampling into the pose estimation task, our method overcomes local minima and improves efficiency in a more extensive search space. We also show the importance of adopting a more robust pixel-based loss function to reduce error. Experiments demonstrate that our method can achieve improved generalization and robustness on both synthetic and real-world benchmarks.
Audio-Visual Segmentation
Jul 11, 2022

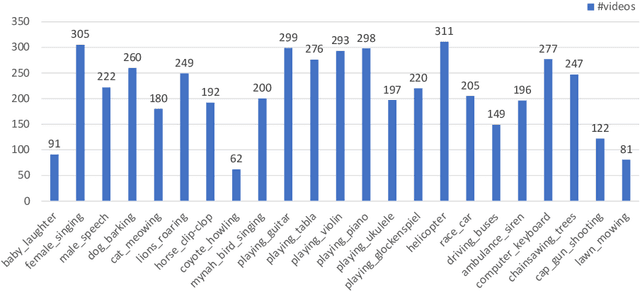
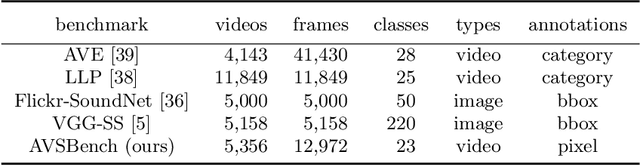
We propose to explore a new problem called audio-visual segmentation (AVS), in which the goal is to output a pixel-level map of the object(s) that produce sound at the time of the image frame. To facilitate this research, we construct the first audio-visual segmentation benchmark (AVSBench), providing pixel-wise annotations for the sounding objects in audible videos. Two settings are studied with this benchmark: 1) semi-supervised audio-visual segmentation with a single sound source and 2) fully-supervised audio-visual segmentation with multiple sound sources. To deal with the AVS problem, we propose a novel method that uses a temporal pixel-wise audio-visual interaction module to inject audio semantics as guidance for the visual segmentation process. We also design a regularization loss to encourage the audio-visual mapping during training. Quantitative and qualitative experiments on the AVSBench compare our approach to several existing methods from related tasks, demonstrating that the proposed method is promising for building a bridge between the audio and pixel-wise visual semantics. Code is available at https://github.com/OpenNLPLab/AVSBench.
Vicinity Vision Transformer
Jun 21, 2022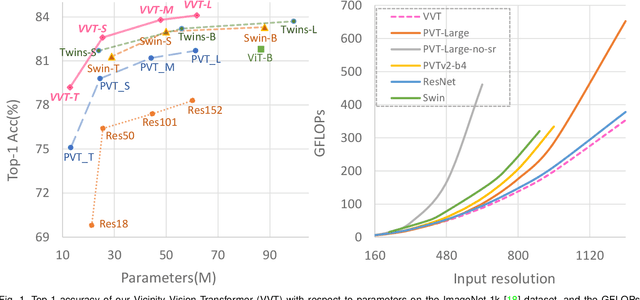
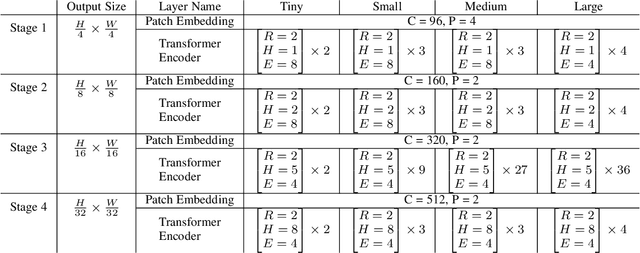
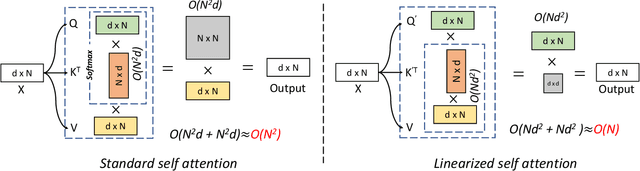
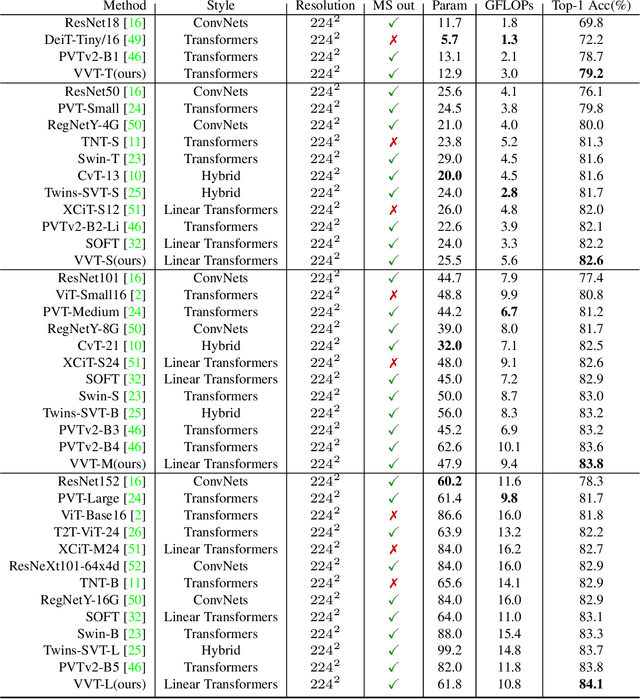
Vision transformers have shown great success on numerous computer vision tasks. However, its central component, softmax attention, prohibits vision transformers from scaling up to high-resolution images, due to both the computational complexity and memory footprint being quadratic. Although linear attention was introduced in natural language processing (NLP) tasks to mitigate a similar issue, directly applying existing linear attention to vision transformers may not lead to satisfactory results. We investigate this problem and find that computer vision tasks focus more on local information compared with NLP tasks. Based on this observation, we present a Vicinity Attention that introduces a locality bias to vision transformers with linear complexity. Specifically, for each image patch, we adjust its attention weight based on its 2D Manhattan distance measured by its neighbouring patches. In this case, the neighbouring patches will receive stronger attention than far-away patches. Moreover, since our Vicinity Attention requires the token length to be much larger than the feature dimension to show its efficiency advantages, we further propose a new Vicinity Vision Transformer (VVT) structure to reduce the feature dimension without degenerating the accuracy. We perform extensive experiments on the CIFAR100, ImageNet1K, and ADE20K datasets to validate the effectiveness of our method. Our method has a slower growth rate of GFlops than previous transformer-based and convolution-based networks when the input resolution increases. In particular, our approach achieves state-of-the-art image classification accuracy with 50% fewer parameters than previous methods.
Keypoint-Based Category-Level Object Pose Tracking from an RGB Sequence with Uncertainty Estimation
May 23, 2022
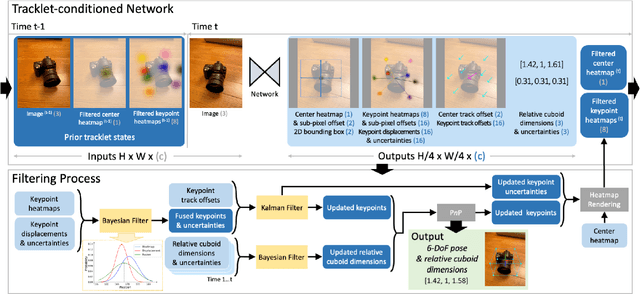
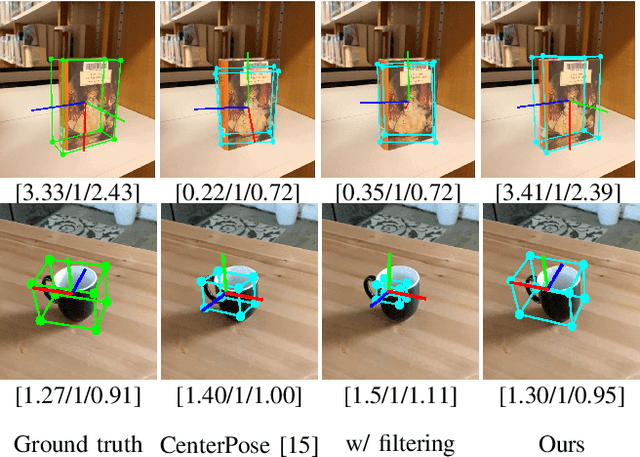
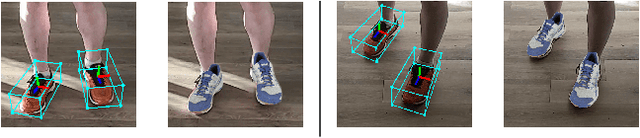
We propose a single-stage, category-level 6-DoF pose estimation algorithm that simultaneously detects and tracks instances of objects within a known category. Our method takes as input the previous and current frame from a monocular RGB video, as well as predictions from the previous frame, to predict the bounding cuboid and 6-DoF pose (up to scale). Internally, a deep network predicts distributions over object keypoints (vertices of the bounding cuboid) in image coordinates, after which a novel probabilistic filtering process integrates across estimates before computing the final pose using PnP. Our framework allows the system to take previous uncertainties into consideration when predicting the current frame, resulting in predictions that are more accurate and stable than single frame methods. Extensive experiments show that our method outperforms existing approaches on the challenging Objectron benchmark of annotated object videos. We also demonstrate the usability of our work in an augmented reality setting.
RTMV: A Ray-Traced Multi-View Synthetic Dataset for Novel View Synthesis
May 14, 2022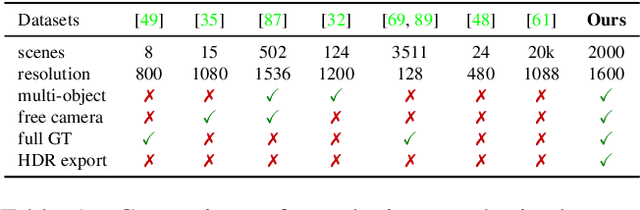


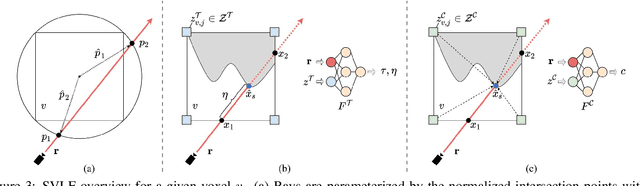
We present a large-scale synthetic dataset for novel view synthesis consisting of ~300k images rendered from nearly 2000 complex scenes using high-quality ray tracing at high resolution (1600 x 1600 pixels). The dataset is orders of magnitude larger than existing synthetic datasets for novel view synthesis, thus providing a large unified benchmark for both training and evaluation. Using 4 distinct sources of high-quality 3D meshes, the scenes of our dataset exhibit challenging variations in camera views, lighting, shape, materials, and textures. Because our dataset is too large for existing methods to process, we propose Sparse Voxel Light Field (SVLF), an efficient voxel-based light field approach for novel view synthesis that achieves comparable performance to NeRF on synthetic data, while being an order of magnitude faster to train and two orders of magnitude faster to render. SVLF achieves this speed by relying on a sparse voxel octree, careful voxel sampling (requiring only a handful of queries per ray), and reduced network structure; as well as ground truth depth maps at training time. Our dataset is generated by NViSII, a Python-based ray tracing renderer, which is designed to be simple for non-experts to use and share, flexible and powerful through its use of scripting, and able to create high-quality and physically-based rendered images. Experiments with a subset of our dataset allow us to compare standard methods like NeRF and mip-NeRF for single-scene modeling, and pixelNeRF for category-level modeling, pointing toward the need for future improvements in this area.
6-DoF Pose Estimation of Household Objects for Robotic Manipulation: An Accessible Dataset and Benchmark
Mar 11, 2022
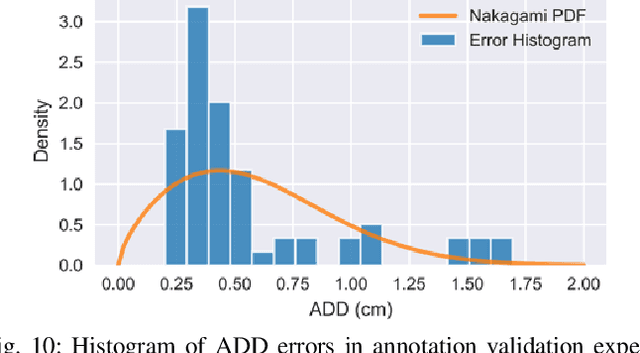
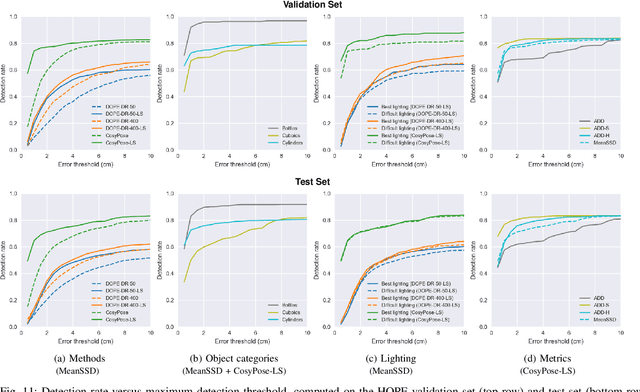
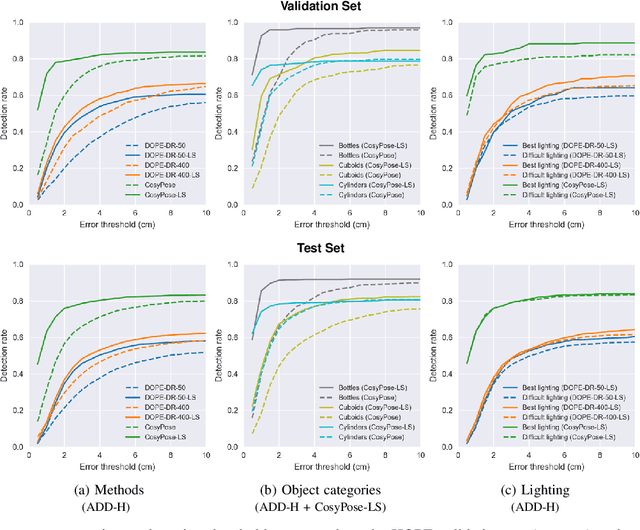
We present a new dataset for 6-DoF pose estimation of known objects, with a focus on robotic manipulation research. We propose a set of toy grocery objects, whose physical instantiations are readily available for purchase and are appropriately sized for robotic grasping and manipulation. We provide 3D scanned textured models of these objects, suitable for generating synthetic training data, as well as RGBD images of the objects in challenging, cluttered scenes exhibiting partial occlusion, extreme lighting variations, multiple instances per image, and a large variety of poses. Using semi-automated RGBD-to-model texture correspondences, the images are annotated with ground truth poses that were verified empirically to be accurate to within a few millimeters. We also propose a new pose evaluation metric called {ADD-H} based upon the Hungarian assignment algorithm that is robust to symmetries in object geometry without requiring their explicit enumeration. We share pre-trained pose estimators for all the toy grocery objects, along with their baseline performance on both validation and test sets. We offer this dataset to the community to help connect the efforts of computer vision researchers with the needs of roboticists.
PredictionNet: Real-Time Joint Probabilistic Traffic Prediction for Planning, Control, and Simulation
Sep 23, 2021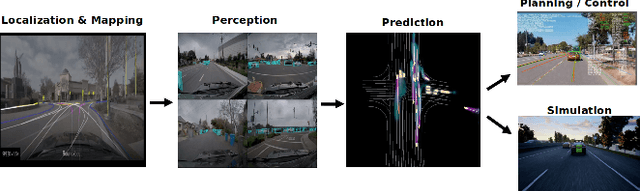
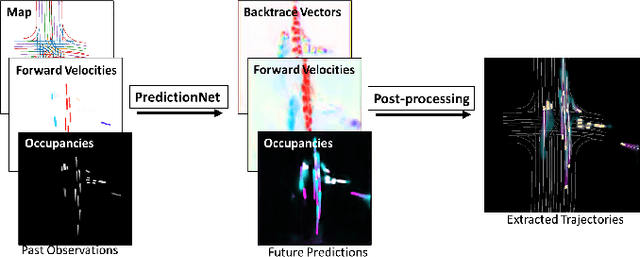
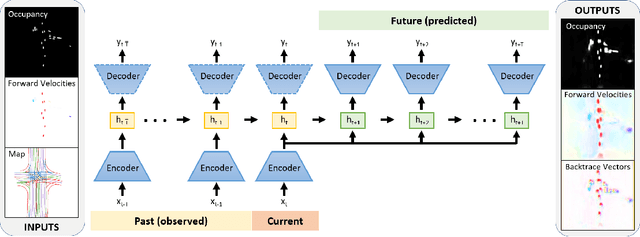

Predicting the future motion of traffic agents is crucial for safe and efficient autonomous driving. To this end, we present PredictionNet, a deep neural network (DNN) that predicts the motion of all surrounding traffic agents together with the ego-vehicle's motion. All predictions are probabilistic and are represented in a simple top-down rasterization that allows an arbitrary number of agents. Conditioned on a multilayer map with lane information, the network outputs future positions, velocities, and backtrace vectors jointly for all agents including the ego-vehicle in a single pass. Trajectories are then extracted from the output. The network can be used to simulate realistic traffic, and it produces competitive results on popular benchmarks. More importantly, it has been used to successfully control a real-world vehicle for hundreds of kilometers, by combining it with a motion planning/control subsystem. The network runs faster than real-time on an embedded GPU, and the system shows good generalization (across sensory modalities and locations) due to the choice of input representation. Furthermore, we demonstrate that by extending the DNN with reinforcement learning (RL), it can better handle rare or unsafe events like aggressive maneuvers and crashes.
Single-stage Keypoint-based Category-level Object Pose Estimation from an RGB Image
Sep 13, 2021
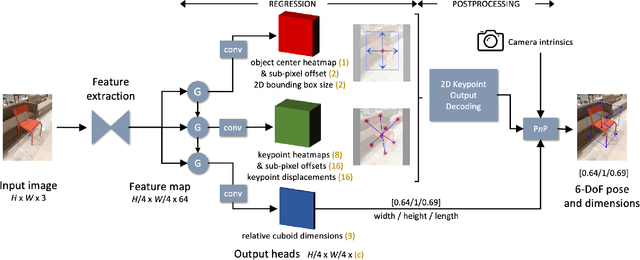

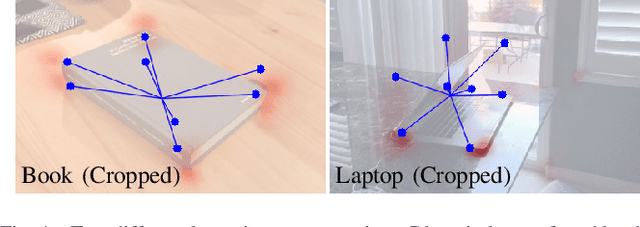
Prior work on 6-DoF object pose estimation has largely focused on instance-level processing, in which a textured CAD model is available for each object being detected. Category-level 6-DoF pose estimation represents an important step toward developing robotic vision systems that operate in unstructured, real-world scenarios. In this work, we propose a single-stage, keypoint-based approach for category-level object pose estimation that operates on unknown object instances within a known category using a single RGB image as input. The proposed network performs 2D object detection, detects 2D keypoints, estimates 6-DoF pose, and regresses relative bounding cuboid dimensions. These quantities are estimated in a sequential fashion, leveraging the recent idea of convGRU for propagating information from easier tasks to those that are more difficult. We favor simplicity in our design choices: generic cuboid vertex coordinates, single-stage network, and monocular RGB input. We conduct extensive experiments on the challenging Objectron benchmark, outperforming state-of-the-art methods on the 3D IoU metric (27.6% higher than the MobilePose single-stage approach and 7.1% higher than the related two-stage approach).