 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Control Policies for Fall prevention and safety in bipedal locomotion
Jan 04, 2022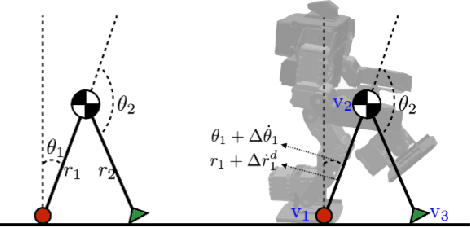
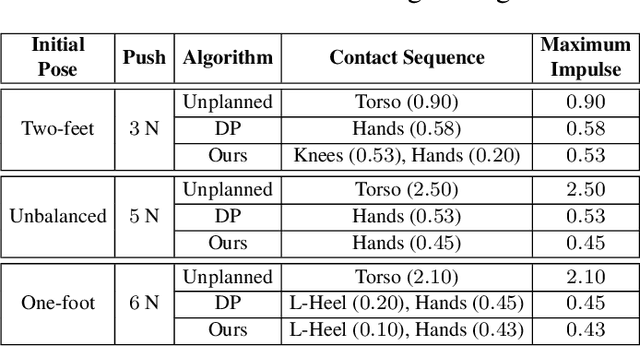
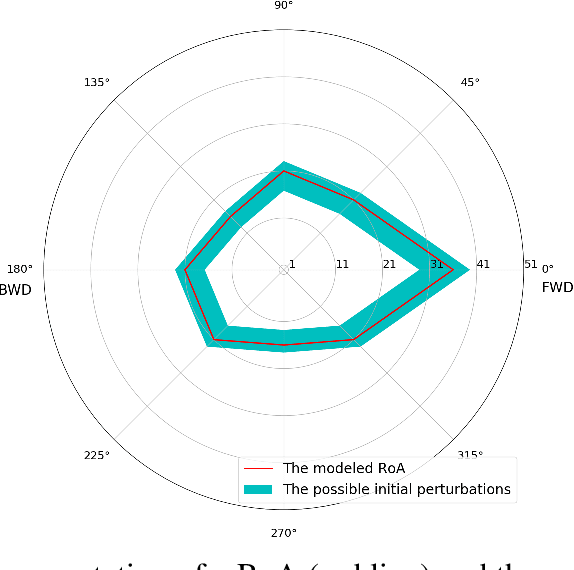
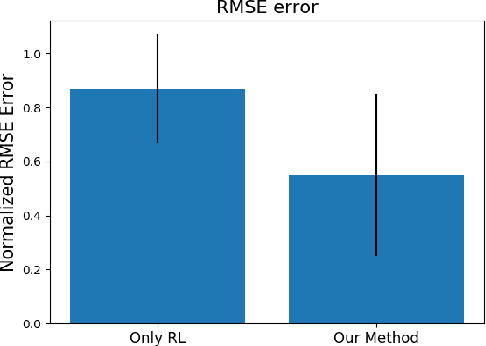
The ability to recover from an unexpected external perturbation is a fundamental motor skill in bipedal locomotion. An effective response includes the ability to not just recover balance and maintain stability but also to fall in a safe manner when balance recovery is physically infeasible. For robots associated with bipedal locomotion, such as humanoid robots and assistive robotic devices that aid humans in walking, designing controllers which can provide this stability and safety can prevent damage to robots or prevent injury related medical costs. This is a challenging task because it involves generating highly dynamic motion for a high-dimensional, non-linear and under-actuated system with contacts. Despite prior advancements in using model-based and optimization methods, challenges such as requirement of extensive domain knowledge, relatively large computational time and limited robustness to changes in dynamics still make this an open problem. In this thesis, to address these issues we develop learning-based algorithms capable of synthesizing push recovery control policies for two different kinds of robots : Humanoid robots and assistive robotic devices that assist in bipedal locomotion. Our work can be branched into two closely related directions : 1) Learning safe falling and fall prevention strategies for humanoid robots and 2) Learning fall prevention strategies for humans using a robotic assistive devices. To achieve this, we introduce a set of Deep Reinforcement Learning (DRL) algorithms to learn control policies that improve safety while using these robots.
Modelling Human Kinetics and Kinematics during Walking using Reinforcement Learning
Mar 15, 2021
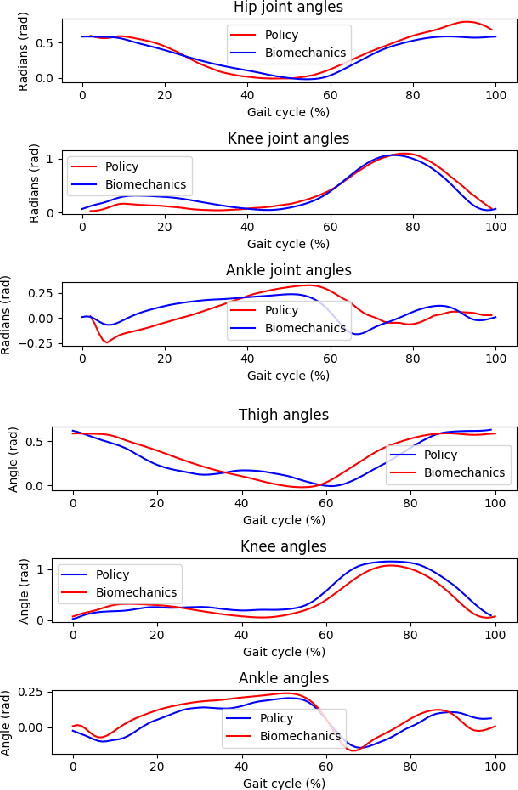
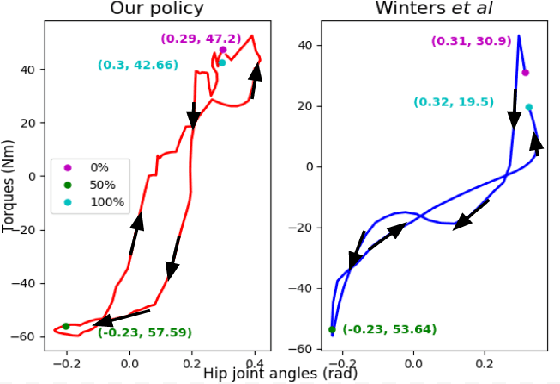
In this work, we develop an automated method to generate 3D human walking motion in simulation which is comparable to real-world human motion. At the core, our work leverages the ability of deep reinforcement learning methods to learn high-dimensional motor skills while being robust to variations in the environment dynamics. Our approach iterates between policy learning and parameter identification to match the real-world bio-mechanical human data. We present a thorough evaluation of the kinematics, kinetics and ground reaction forces generated by our learned virtual human agent. We also show that the method generalizes well across human-subjects with different kinematic structure and gait-characteristics.
Error-Aware Policy Learning: Zero-Shot Generalization in Partially Observable Dynamic Environments
Mar 13, 2021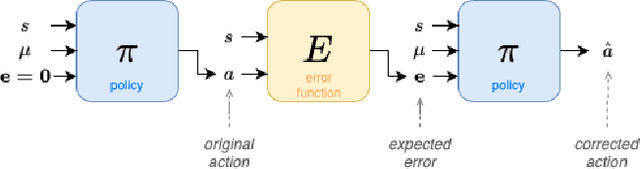
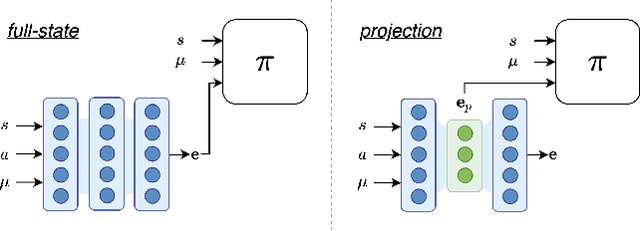
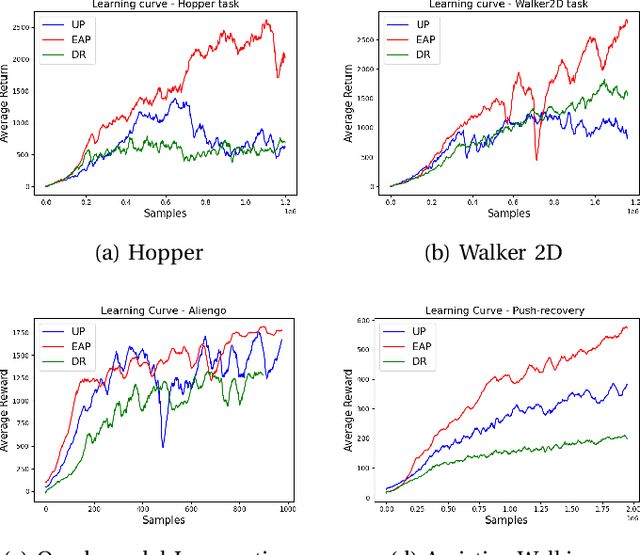
Simulation provides a safe and efficient way to generate useful data for learning complex robotic tasks. However, matching simulation and real-world dynamics can be quite challenging, especially for systems that have a large number of unobserved or unmeasurable parameters, which may lie in the robot dynamics itself or in the environment with which the robot interacts. We introduce a novel approach to tackle such a sim-to-real problem by developing policies capable of adapting to new environments, in a zero-shot manner. Key to our approach is an error-aware policy (EAP) that is explicitly made aware of the effect of unobservable factors during training. An EAP takes as input the predicted future state error in the target environment, which is provided by an error-prediction function, simultaneously trained with the EAP. We validate our approach on an assistive walking device trained to help the human user recover from external pushes. We show that a trained EAP for a hip-torque assistive device can be transferred to different human agents with unseen biomechanical characteristics. In addition, we show that our method can be applied to other standard RL control tasks.
Joint Space Control via Deep Reinforcement Learning
Nov 12, 2020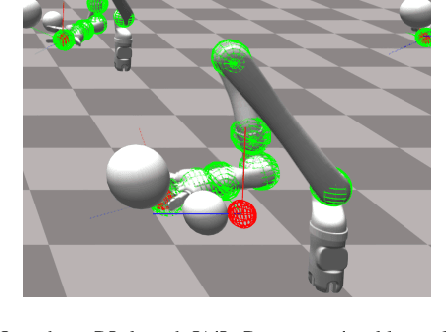
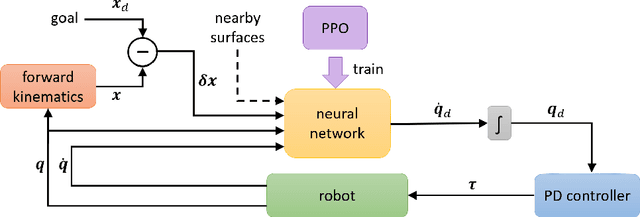

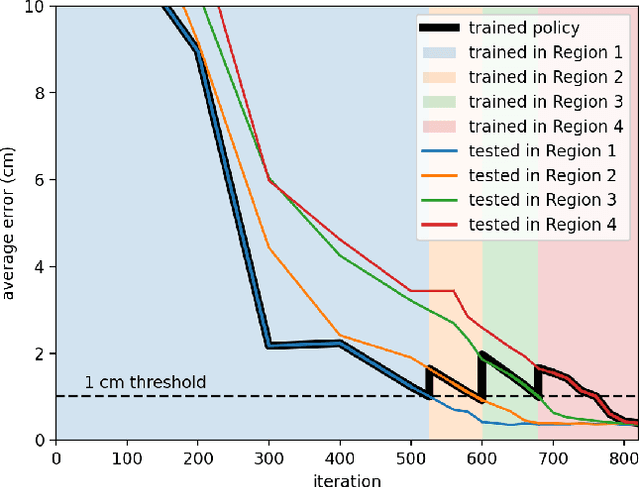
The dominant way to control a robot manipulator uses hand-crafted differential equations leveraging some form of inverse kinematics / dynamics. We propose a simple, versatile joint-level controller that dispenses with differential equations entirely. A deep neural network, trained via model-free reinforcement learning, is used to map from task space to joint space. Experiments show the method capable of achieving similar error to traditional methods, while greatly simplifying the process by automatically handling redundancy, joint limits, and acceleration / deceleration profiles. The basic technique is extended to avoid obstacles by augmenting the input to the network with information about the nearest obstacles. Results are shown both in simulation and on a real robot via sim-to-real transfer of the learned policy. We show that it is possible to achieve sub-centimeter accuracy, both in simulation and the real world, with a moderate amount of training.
Contextual Reinforcement Learning of Visuo-tactile Multi-fingered Grasping Policies
Nov 24, 2019
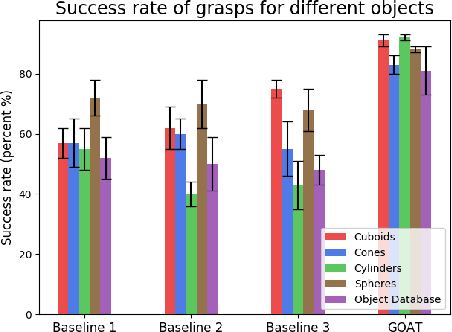
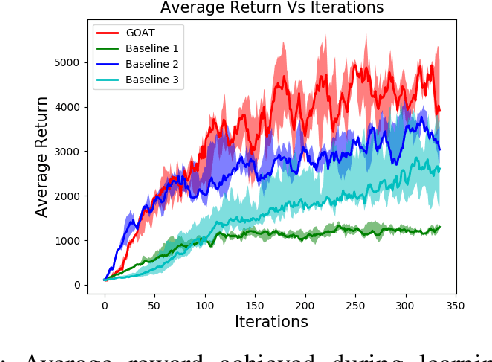
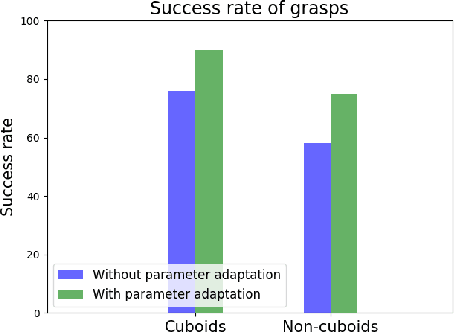
Using simulation to train robot manipulation policies holds the promise of an almost unlimited amount of training data, generated safely out of harm's way. One of the key challenges of using simulation, to date, has been to bridge the reality gap, so that policies trained in simulation can be deployed in the real world. We explore the reality gap in the context of learning a contextual policy for multi-fingered robotic grasping. We propose a Grasping Objects Approach for Tactile (GOAT) robotic hands, learning to overcome the reality gap problem. In our approach we use human hand motion demonstration to initialize and reduce the search space for learning. We contextualize our policy with the bounding cuboid dimensions of the object of interest, which allows the policy to work on a more flexible representation than directly using an image or point cloud. Leveraging fingertip touch sensors in the hand allows the policy to overcome the reduction in geometric information introduced by the coarse bounding box, as well as pose estimation uncertainty. We show our learned policy successfully runs on a real robot without any fine tuning, thus bridging the reality gap.