 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGGT-$Ω$
May 14, 2026Recent feed-forward reconstruction models, such as VGGT, have proven competitive with traditional optimization-based reconstructors while also providing geometry-aware features useful for other tasks. Here, we show that the quality of these models scales predictably with model and data size. We do so by introducing VGGT-$Ω$, which substantially improves reconstruction accuracy, efficiency, and capabilities for both static and dynamic scenes. To enable training this model at an unprecedented scale, we introduce architectural changes that improve training efficiency, a high-quality data annotation pipeline that supports dynamic scenes, and a self-supervised learning protocol. We simplify VGGT's architecture by using a single dense prediction head with multi-task supervision and removing the expensive high-resolution convolutional layers. We also use registers to aggregate scene information into a compact representation and introduce register attention, which restricts inter-frame information exchange to these registers, in part replacing global attention. In this way, during training, VGGT-$Ω$ uses only about 30% of the GPU memory of its predecessor, allowing us to train with 15x more supervised data than prior work and to leverage vast amounts of unlabeled video data. VGGT-$Ω$ achieves strong results for reconstruction of static and dynamic scenes across multiple benchmarks, for example, improving over the previous best camera estimation accuracy on Sintel by 77%. We also show that the learned registers can improve vision-language-action models and support alignment with language, suggesting that reconstruction can be a powerful and scalable proxy task for spatial understanding. Project Page: http://vggt-omega.github.io/
SceneScribe-1M: A Large-Scale Video Dataset with Comprehensive Geometric and Semantic Annotations
Apr 09, 2026The convergence of 3D geometric perception and video synthesis has created an unprecedented demand for large-scale video data that is rich in both semantic and spatio-temporal information. While existing datasets have advanced either 3D understanding or video generation, a significant gap remains in providing a unified resource that supports both domains at scale. To bridge this chasm, we introduce SceneScribe-1M, a new large-scale, multi-modal video dataset. It comprises one million in-the-wild videos, each meticulously annotated with detailed textual descriptions, precise camera parameters, dense depth maps, and consistent 3D point tracks. We demonstrate the versatility and value of SceneScribe-1M by establishing benchmarks across a wide array of downstream tasks, including monocular depth estimation, scene reconstruction, and dynamic point tracking, as well as generative tasks such as text-to-video synthesis, with or without camera control. By open-sourcing SceneScribe-1M, we aim to provide a comprehensive benchmark and a catalyst for research, fostering the development of models that can both perceive the dynamic 3D world and generate controllable, realistic video content.
LagerNVS: Latent Geometry for Fully Neural Real-time Novel View Synthesis
Mar 20, 2026Recent work has shown that neural networks can perform 3D tasks such as Novel View Synthesis (NVS) without explicit 3D reconstruction. Even so, we argue that strong 3D inductive biases are still helpful in the design of such networks. We show this point by introducing LagerNVS, an encoder-decoder neural network for NVS that builds on `3D-aware' latent features. The encoder is initialized from a 3D reconstruction network pre-trained using explicit 3D supervision. This is paired with a lightweight decoder, and trained end-to-end with photometric losses. LagerNVS achieves state-of-the-art deterministic feed-forward Novel View Synthesis (including 31.4 PSNR on Re10k), with and without known cameras, renders in real time, generalizes to in-the-wild data, and can be paired with a diffusion decoder for generative extrapolation.
LitePT: Lighter Yet Stronger Point Transformer
Dec 15, 2025



Modern neural architectures for 3D point cloud processing contain both convolutional layers and attention blocks, but the best way to assemble them remains unclear. We analyse the role of different computational blocks in 3D point cloud networks and find an intuitive behaviour: convolution is adequate to extract low-level geometry at high-resolution in early layers, where attention is expensive without bringing any benefits; attention captures high-level semantics and context in low-resolution, deep layers more efficiently. Guided by this design principle, we propose a new, improved 3D point cloud backbone that employs convolutions in early stages and switches to attention for deeper layers. To avoid the loss of spatial layout information when discarding redundant convolution layers, we introduce a novel, training-free 3D positional encoding, PointROPE. The resulting LitePT model has $3.6\times$ fewer parameters, runs $2\times$ faster, and uses $2\times$ less memory than the state-of-the-art Point Transformer V3, but nonetheless matches or even outperforms it on a range of tasks and datasets. Code and models are available at: https://github.com/prs-eth/LitePT.
Fence off Anomaly Interference: Cross-Domain Distillation for Fully Unsupervised Anomaly Detection
Aug 25, 2025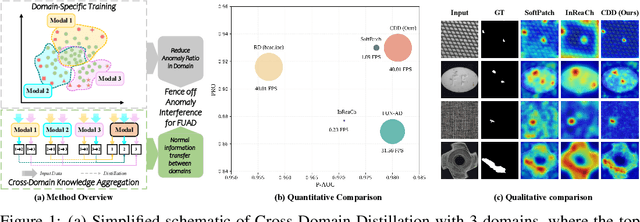

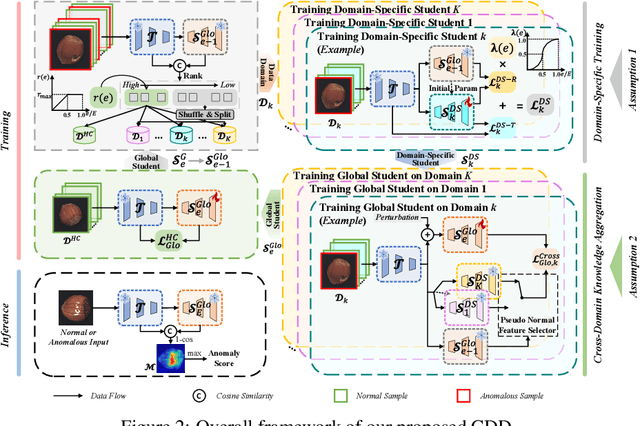
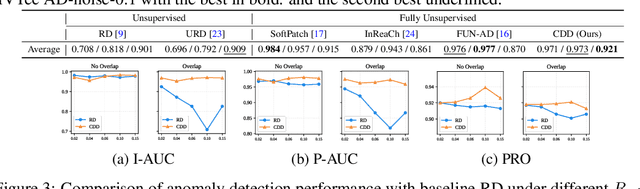
Fully Unsupervised Anomaly Detection (FUAD) is a practical extension of Unsupervised Anomaly Detection (UAD), aiming to detect anomalies without any labels even when the training set may contain anomalous samples. To achieve FUAD, we pioneer the introduction of Knowledge Distillation (KD) paradigm based on teacher-student framework into the FUAD setting. However, due to the presence of anomalies in the training data, traditional KD methods risk enabling the student to learn the teacher's representation of anomalies under FUAD setting, thereby resulting in poor anomaly detection performance. To address this issue, we propose a novel Cross-Domain Distillation (CDD) framework based on the widely studied reverse distillation (RD) paradigm. Specifically, we design a Domain-Specific Training, which divides the training set into multiple domains with lower anomaly ratios and train a domain-specific student for each. Cross-Domain Knowledge Aggregation is then performed, where pseudo-normal features generated by domain-specific students collaboratively guide a global student to learn generalized normal representations across all samples. Experimental results on noisy versions of the MVTec AD and VisA datasets demonstrate that our method achieves significant performance improvements over the baseline, validating its effectiveness under FUAD setting.
DINOv3
Aug 13, 2025Self-supervised learning holds the promise of eliminating the need for manual data annotation, enabling models to scale effortlessly to massive datasets and larger architectures. By not being tailored to specific tasks or domains, this training paradigm has the potential to learn visual representations from diverse sources, ranging from natural to aerial images -- using a single algorithm. This technical report introduces DINOv3, a major milestone toward realizing this vision by leveraging simple yet effective strategies. First, we leverage the benefit of scaling both dataset and model size by careful data preparation, design, and optimization. Second, we introduce a new method called Gram anchoring, which effectively addresses the known yet unsolved issue of dense feature maps degrading during long training schedules. Finally, we apply post-hoc strategies that further enhance our models' flexibility with respect to resolution, model size, and alignment with text. As a result, we present a versatile vision foundation model that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models. We also share the DINOv3 suite of vision models, designed to advance the state of the art on a wide spectrum of tasks and data by providing scalable solutions for diverse resource constraints and deployment scenarios.
AutoPartGen: Autogressive 3D Part Generation and Discovery
Jul 17, 2025



We introduce AutoPartGen, a model that generates objects composed of 3D parts in an autoregressive manner. This model can take as input an image of an object, 2D masks of the object's parts, or an existing 3D object, and generate a corresponding compositional 3D reconstruction. Our approach builds upon 3DShape2VecSet, a recent latent 3D representation with powerful geometric expressiveness. We observe that this latent space exhibits strong compositional properties, making it particularly well-suited for part-based generation tasks. Specifically, AutoPartGen generates object parts autoregressively, predicting one part at a time while conditioning on previously generated parts and additional inputs, such as 2D images, masks, or 3D objects. This process continues until the model decides that all parts have been generated, thus determining automatically the type and number of parts. The resulting parts can be seamlessly assembled into coherent objects or scenes without requiring additional optimization. We evaluate both the overall 3D generation capabilities and the part-level generation quality of AutoPartGen, demonstrating that it achieves state-of-the-art performance in 3D part generation.
SpatialTrackerV2: 3D Point Tracking Made Easy
Jul 16, 2025We present SpatialTrackerV2, a feed-forward 3D point tracking method for monocular videos. Going beyond modular pipelines built on off-the-shelf components for 3D tracking, our approach unifies the intrinsic connections between point tracking, monocular depth, and camera pose estimation into a high-performing and feedforward 3D point tracker. It decomposes world-space 3D motion into scene geometry, camera ego-motion, and pixel-wise object motion, with a fully differentiable and end-to-end architecture, allowing scalable training across a wide range of datasets, including synthetic sequences, posed RGB-D videos, and unlabeled in-the-wild footage. By learning geometry and motion jointly from such heterogeneous data, SpatialTrackerV2 outperforms existing 3D tracking methods by 30%, and matches the accuracy of leading dynamic 3D reconstruction approaches while running 50$\times$ faster.
VGGT: Visual Geometry Grounded Transformer
Mar 14, 2025



We present VGGT, a feed-forward neural network that directly infers all key 3D attributes of a scene, including camera parameters, point maps, depth maps, and 3D point tracks, from one, a few, or hundreds of its views. This approach is a step forward in 3D computer vision, where models have typically been constrained to and specialized for single tasks. It is also simple and efficient, reconstructing images in under one second, and still outperforming alternatives that require post-processing with visual geometry optimization techniques. The network achieves state-of-the-art results in multiple 3D tasks, including camera parameter estimation, multi-view depth estimation, dense point cloud reconstruction, and 3D point tracking. We also show that using pretrained VGGT as a feature backbone significantly enhances downstream tasks, such as non-rigid point tracking and feed-forward novel view synthesis. Code and models are publicly available at https://github.com/facebookresearch/vggt.
FLARE: Feed-forward Geometry, Appearance and Camera Estimation from Uncalibrated Sparse Views
Feb 19, 2025We present FLARE, a feed-forward model designed to infer high-quality camera poses and 3D geometry from uncalibrated sparse-view images (i.e., as few as 2-8 inputs), which is a challenging yet practical setting in real-world applications. Our solution features a cascaded learning paradigm with camera pose serving as the critical bridge, recognizing its essential role in mapping 3D structures onto 2D image planes. Concretely, FLARE starts with camera pose estimation, whose results condition the subsequent learning of geometric structure and appearance, optimized through the objectives of geometry reconstruction and novel-view synthesis. Utilizing large-scale public datasets for training, our method delivers state-of-the-art performance in the tasks of pose estimation, geometry reconstruction, and novel view synthesis, while maintaining the inference efficiency (i.e., less than 0.5 seconds). The project page and code can be found at: https://zhanghe3z.github.io/FLARE/