 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor-Free Person Search
Mar 22, 2021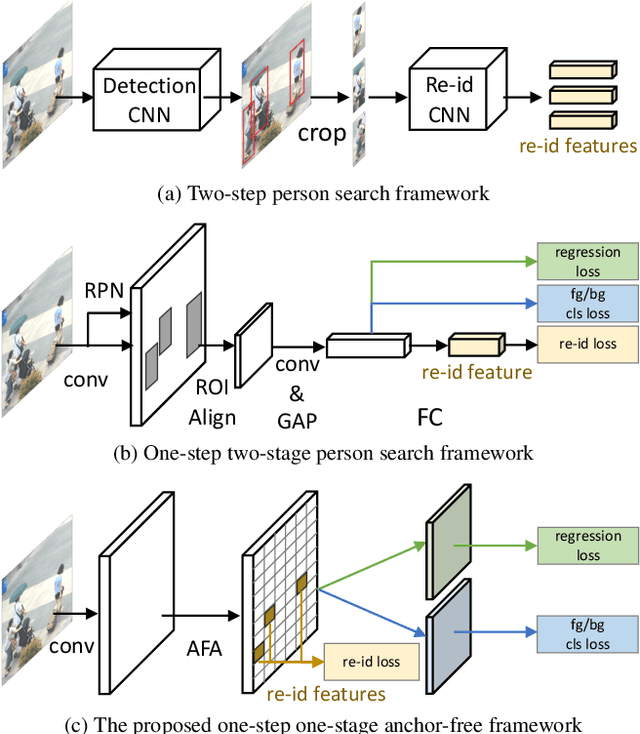
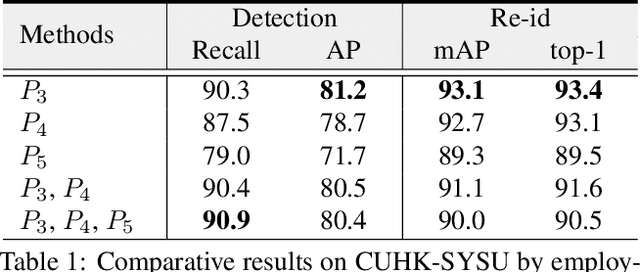
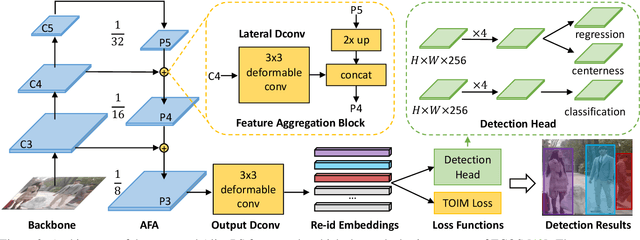
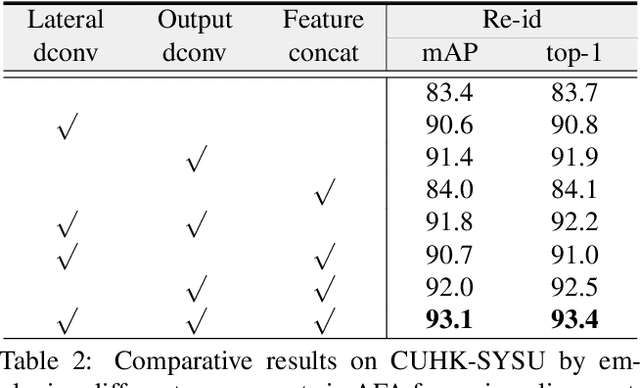
Person search aims to simultaneously localize and identify a query person from realistic, uncropped images, which can be regarded as the unified task of pedestrian detection and person re-identification (re-id). Most existing works employ two-stage detectors like Faster-RCNN, yielding encouraging accuracy but with high computational overhead. In this work, we present the Feature-Aligned Person Search Network (AlignPS), the first anchor-free framework to efficiently tackle this challenging task. AlignPS explicitly addresses the major challenges, which we summarize as the misalignment issues in different levels (i.e., scale, region, and task), when accommodating an anchor-free detector for this task. More specifically, we propose an aligned feature aggregation module to generate more discriminative and robust feature embeddings by following a "re-id first" principle. Such a simple design directly improves the baseline anchor-free model on CUHK-SYSU by more than 20% in mAP. Moreover, AlignPS outperforms state-of-the-art two-stage methods, with a higher speed. Code is available at https://github.com/daodaofr/AlignPS
SwiftNet: Real-time Video Object Segmentation
Feb 09, 2021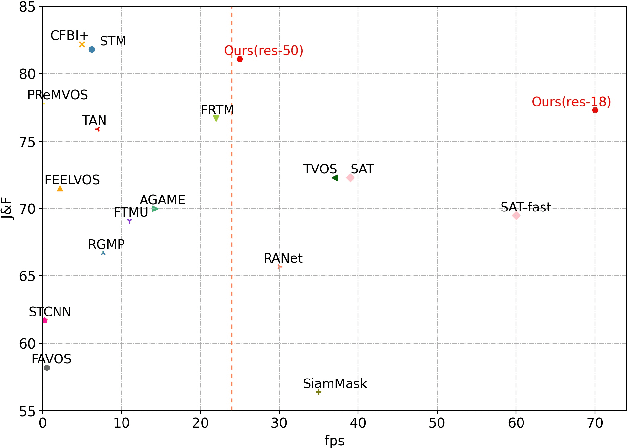
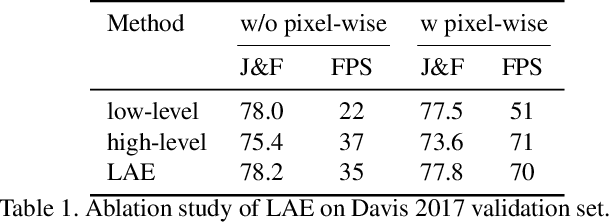

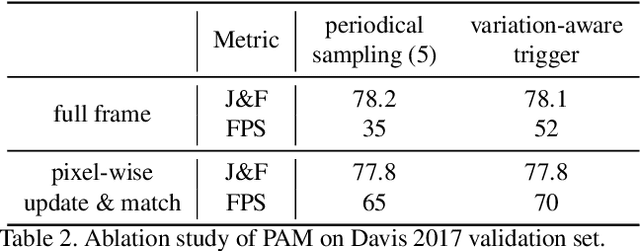
In this work we present SwiftNet for real-time semi-supervised video object segmentation (one-shot VOS), which reports 77.8% J&F and 70 FPS on DAVIS 2017 validation dataset, leading all present solutions in overall accuracy and speed performance. We achieve this by elaborately compressing spatiotemporal redundancy in matching-based VOS via Pixel-Adaptive Memory (PAM). Temporally, PAM adaptively triggers memory updates on frames where objects display noteworthy inter-frame variations. Spatially, PAM selectively performs memory update and match on dynamic pixels while ignoring the static ones, significantly reducing redundant computations wasted on segmentation-irrelevant pixels. To promote efficient reference encoding, light-aggregation encoder is also introduced in SwiftNet deploying reversed sub-pixel. We hope SwiftNet could set a strong and efficient baseline for real-time VOS and facilitate its application in mobile vision.
Occluded Video Instance Segmentation
Feb 08, 2021
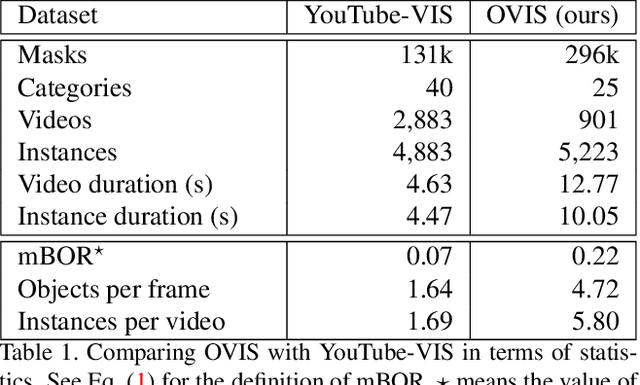

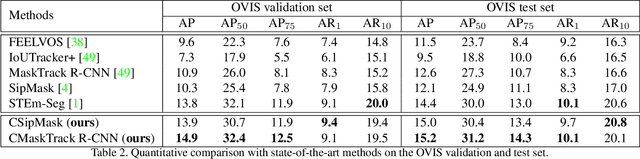
Can our video understanding systems perceive objects when a heavy occlusion exists in a scene? To answer this question, we collect a large scale dataset called OVIS for occluded video instance segmentation, that is, to simultaneously detect, segment, and track instances in occluded scenes. OVIS consists of 296k high-quality instance masks from 25 semantic categories, where object occlusions usually occur. While our human vision systems can understand those occluded instances by contextual reasoning and association, our experiments suggest that current video understanding systems are not satisfying. On the OVIS dataset, the highest AP achieved by state-of-the-art algorithms is only 14.4, which reveals that we are still at a nascent stage for understanding objects, instances, and videos in a real-world scenario. Moreover, to complement missing object cues caused by occlusion, we propose a plug-and-play module called temporal feature calibration. Built upon MaskTrack R-CNN and SipMask, we report an AP of 15.2 and 15.0 respectively. The OVIS dataset is released at http://songbai.site/ovis , and the project code will be available soon.
Multi-shot Temporal Event Localization: a Benchmark
Dec 17, 2020


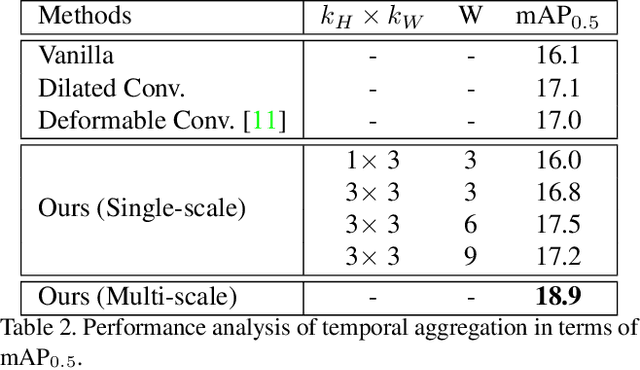
Current developments in temporal event or action localization usually target actions captured by a single camera. However, extensive events or actions in the wild may be captured as a sequence of shots by multiple cameras at different positions. In this paper, we propose a new and challenging task called multi-shot temporal event localization, and accordingly, collect a large scale dataset called MUlti-Shot EventS (MUSES). MUSES has 31,477 event instances for a total of 716 video hours. The core nature of MUSES is the frequent shot cuts, for an average of 19 shots per instance and 176 shots per video, which induces large intrainstance variations. Our comprehensive evaluations show that the state-of-the-art method in temporal action localization only achieves an mAP of 13.1% at IoU=0.5. As a minor contribution, we present a simple baseline approach for handling the intra-instance variations, which reports an mAP of 18.9% on MUSES and 56.9% on THUMOS14 at IoU=0.5. To facilitate research in this direction, we release the dataset and the project code at https://songbai.site/muses.
Importance-Aware Semantic Segmentation in Self-Driving with Discrete Wasserstein Training
Oct 21, 2020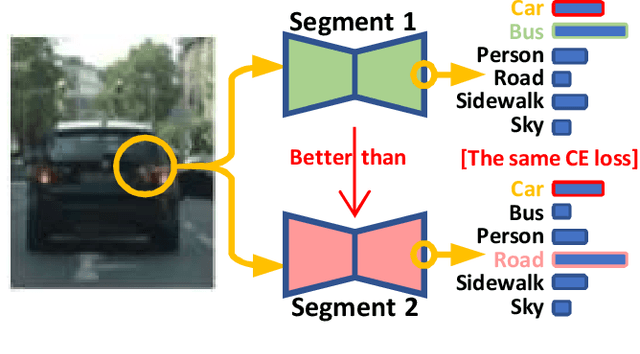
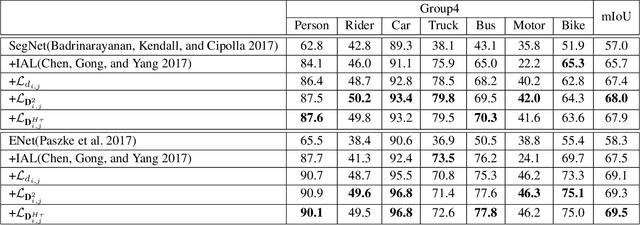
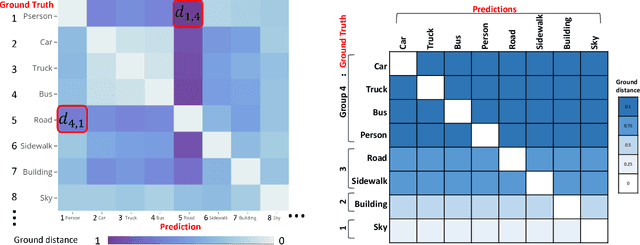
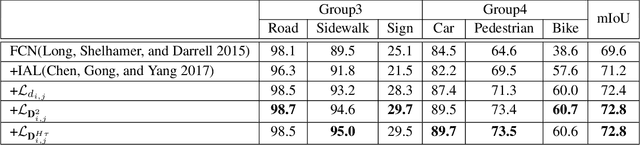
Semantic segmentation (SS) is an important perception manner for self-driving cars and robotics, which classifies each pixel into a pre-determined class. The widely-used cross entropy (CE) loss-based deep networks has achieved significant progress w.r.t. the mean Intersection-over Union (mIoU). However, the cross entropy loss can not take the different importance of each class in an self-driving system into account. For example, pedestrians in the image should be much more important than the surrounding buildings when make a decisions in the driving, so their segmentation results are expected to be as accurate as possible. In this paper, we propose to incorporate the importance-aware inter-class correlation in a Wasserstein training framework by configuring its ground distance matrix. The ground distance matrix can be pre-defined following a priori in a specific task, and the previous importance-ignored methods can be the particular cases. From an optimization perspective, we also extend our ground metric to a linear, convex or concave increasing function $w.r.t.$ pre-defined ground distance. We evaluate our method on CamVid and Cityscapes datasets with different backbones (SegNet, ENet, FCN and Deeplab) in a plug and play fashion. In our extenssive experiments, Wasserstein loss demonstrates superior segmentation performance on the predefined critical classes for safe-driving.
Dual Attention GANs for Semantic Image Synthesis
Aug 29, 2020

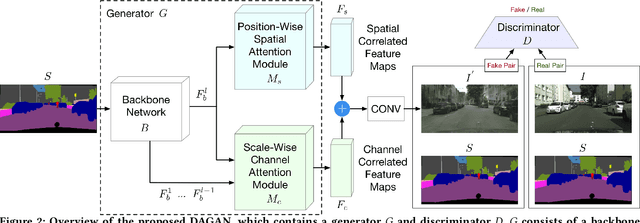
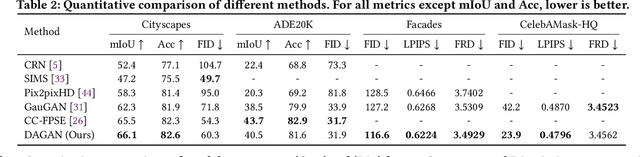
In this paper, we focus on the semantic image synthesis task that aims at transferring semantic label maps to photo-realistic images. Existing methods lack effective semantic constraints to preserve the semantic information and ignore the structural correlations in both spatial and channel dimensions, leading to unsatisfactory blurry and artifact-prone results. To address these limitations, we propose a novel Dual Attention GAN (DAGAN) to synthesize photo-realistic and semantically-consistent images with fine details from the input layouts without imposing extra training overhead or modifying the network architectures of existing methods. We also propose two novel modules, i.e., position-wise Spatial Attention Module (SAM) and scale-wise Channel Attention Module (CAM), to capture semantic structure attention in spatial and channel dimensions, respectively. Specifically, SAM selectively correlates the pixels at each position by a spatial attention map, leading to pixels with the same semantic label being related to each other regardless of their spatial distances. Meanwhile, CAM selectively emphasizes the scale-wise features at each channel by a channel attention map, which integrates associated features among all channel maps regardless of their scales. We finally sum the outputs of SAM and CAM to further improve feature representation. Extensive experiments on four challenging datasets show that DAGAN achieves remarkably better results than state-of-the-art methods, while using fewer model parameters. The source code and trained models are available at https://github.com/Ha0Tang/DAGAN.
Bipartite Graph Reasoning GANs for Person Image Generation
Aug 20, 2020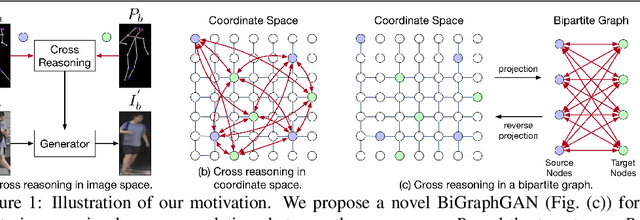
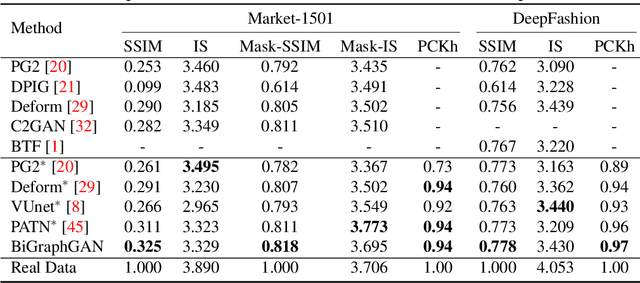
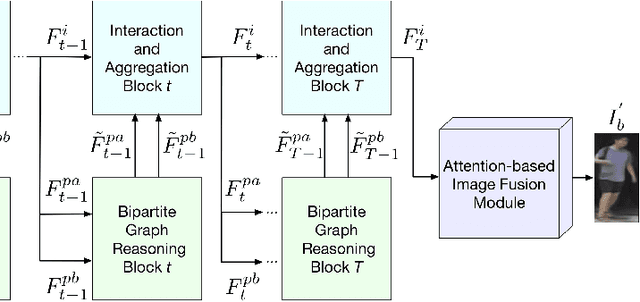
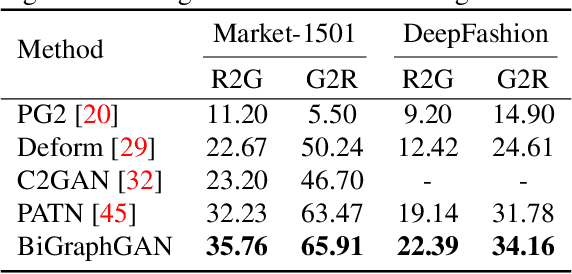
We present a novel Bipartite Graph Reasoning GAN (BiGraphGAN) for the challenging person image generation task. The proposed graph generator mainly consists of two novel blocks that aim to model the pose-to-pose and pose-to-image relations, respectively. Specifically, the proposed Bipartite Graph Reasoning (BGR) block aims to reason the crossing long-range relations between the source pose and the target pose in a bipartite graph, which mitigates some challenges caused by pose deformation. Moreover, we propose a new Interaction-and-Aggregation (IA) block to effectively update and enhance the feature representation capability of both person's shape and appearance in an interactive way. Experiments on two challenging and public datasets, i.e., Market-1501 and DeepFashion, show the effectiveness of the proposed BiGraphGAN in terms of objective quantitative scores and subjective visual realness. The source code and trained models are available at https://github.com/Ha0Tang/BiGraphGAN.
Reinforced Wasserstein Training for Severity-Aware Semantic Segmentation in Autonomous Driving
Aug 11, 2020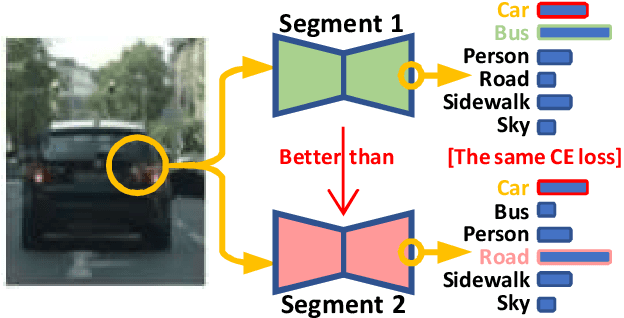
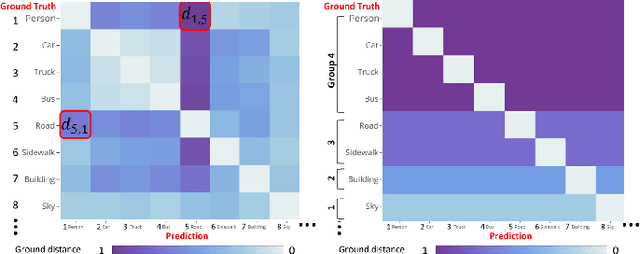
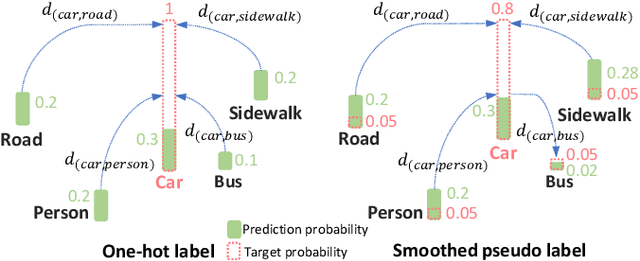
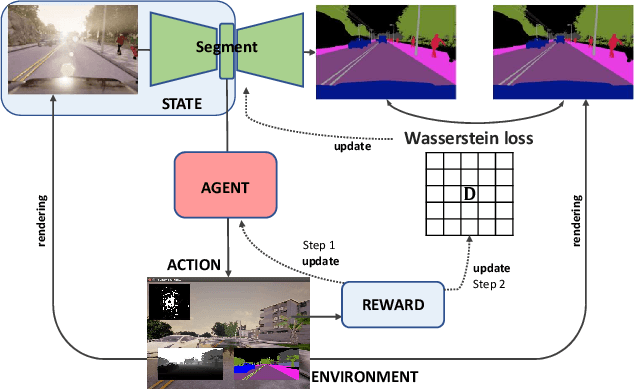
Semantic segmentation is important for many real-world systems, e.g., autonomous vehicles, which predict the class of each pixel. Recently, deep networks achieved significant progress w.r.t. the mean Intersection-over Union (mIoU) with the cross-entropy loss. However, the cross-entropy loss can essentially ignore the difference of severity for an autonomous car with different wrong prediction mistakes. For example, predicting the car to the road is much more servery than recognize it as the bus. Targeting for this difficulty, we develop a Wasserstein training framework to explore the inter-class correlation by defining its ground metric as misclassification severity. The ground metric of Wasserstein distance can be pre-defined following the experience on a specific task. From the optimization perspective, we further propose to set the ground metric as an increasing function of the pre-defined ground metric. Furthermore, an adaptively learning scheme of the ground matrix is proposed to utilize the high-fidelity CARLA simulator. Specifically, we follow a reinforcement alternative learning scheme. The experiments on both CamVid and Cityscapes datasets evidenced the effectiveness of our Wasserstein loss. The SegNet, ENet, FCN and Deeplab networks can be adapted following a plug-in manner. We achieve significant improvements on the predefined important classes, and much longer continuous playtime in our simulator.
Corner Proposal Network for Anchor-free, Two-stage Object Detection
Jul 27, 2020
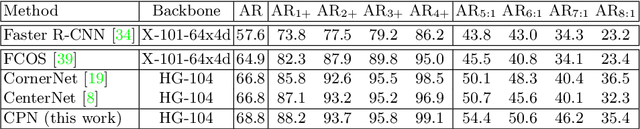

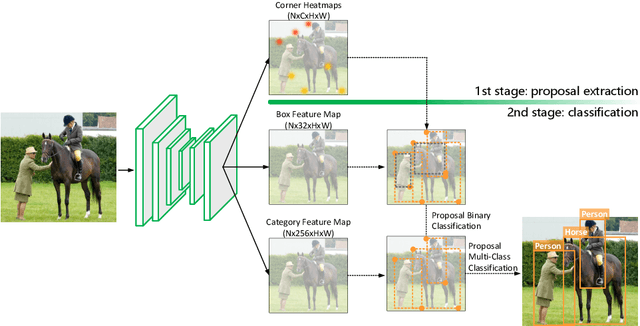
The goal of object detection is to determine the class and location of objects in an image. This paper proposes a novel anchor-free, two-stage framework which first extracts a number of object proposals by finding potential corner keypoint combinations and then assigns a class label to each proposal by a standalone classification stage. We demonstrate that these two stages are effective solutions for improving recall and precision, respectively, and they can be integrated into an end-to-end network. Our approach, dubbed Corner Proposal Network (CPN), enjoys the ability to detect objects of various scales and also avoids being confused by a large number of false-positive proposals. On the MS-COCO dataset, CPN achieves an AP of 49.2% which is competitive among state-of-the-art object detection methods. CPN also fits the scenario of computational efficiency, which achieves an AP of 41.6%/39.7% at 26.2/43.3 FPS, surpassing most competitors with the same inference speed. Code is available at https://github.com/Duankaiwen/CPNDet
FedOCR: Communication-Efficient Federated Learning for Scene Text Recognition
Jul 22, 2020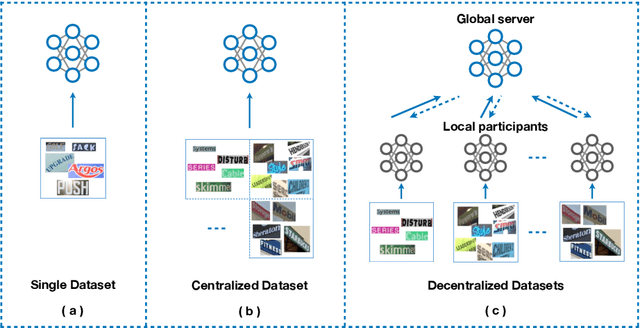

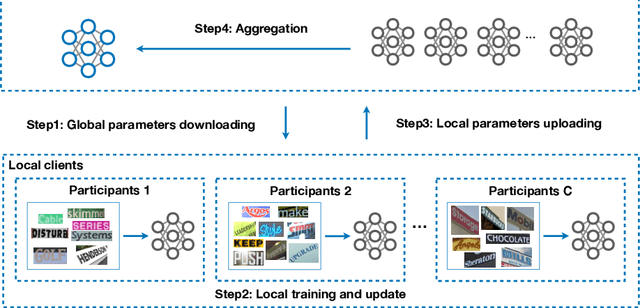
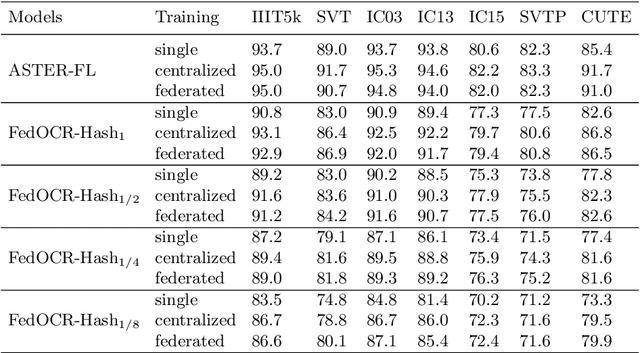
While scene text recognition techniques have been widely used in commercial applications, data privacy has rarely been taken into account by this research community. Most existing algorithms have assumed a set of shared or centralized training data. However, in practice, data may be distributed on different local devices that can not be centralized to share due to the privacy restrictions. In this paper, we study how to make use of decentralized datasets for training a robust scene text recognizer while keeping them stay on local devices. To the best of our knowledge, we propose the first framework leveraging federated learning for scene text recognition, which is trained with decentralized datasets collaboratively. Hence we name it FedOCR. To make FedCOR fairly suitable to be deployed on end devices, we make two improvements including using lightweight models and hashing techniques. We argue that both are crucial for FedOCR in terms of the communication efficiency of federated learning. The simulations on decentralized datasets show that the proposed FedOCR achieves competitive results to the models that are trained with centralized data, with fewer communication costs and higher-level privacy-preserving.