 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2R: Efficiently Navigating Divergent Reasoning Paths with Small-Large Model Token Routing
May 27, 2025Large Language Models (LLMs) achieve impressive reasoning capabilities at the cost of substantial inference overhead, posing substantial deployment challenges. Although distilled Small Language Models (SLMs) significantly enhance efficiency, their performance suffers as they fail to follow LLMs' reasoning paths. Luckily, we reveal that only a small fraction of tokens genuinely diverge reasoning paths between LLMs and SLMs. Most generated tokens are either identical or exhibit neutral differences, such as minor variations in abbreviations or expressions. Leveraging this insight, we introduce **Roads to Rome (R2R)**, a neural token routing method that selectively utilizes LLMs only for these critical, path-divergent tokens, while leaving the majority of token generation to the SLM. We also develop an automatic data generation pipeline that identifies divergent tokens and generates token-level routing labels to train the lightweight router. We apply R2R to combine R1-1.5B and R1-32B models from the DeepSeek family, and evaluate on challenging math, coding, and QA benchmarks. With an average activated parameter size of 5.6B, R2R surpasses the average accuracy of R1-7B by 1.6x, outperforming even the R1-14B model. Compared to R1-32B, it delivers a 2.8x wall-clock speedup with comparable performance, advancing the Pareto frontier of test-time scaling efficiency. Our code is available at https://github.com/thu-nics/R2R.
Multimodal Gaussian Mixture Model for Realtime Roadside LiDAR Object Detection
Apr 20, 2022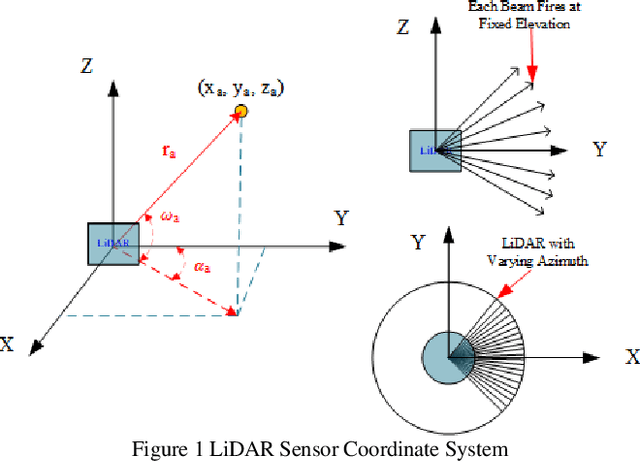
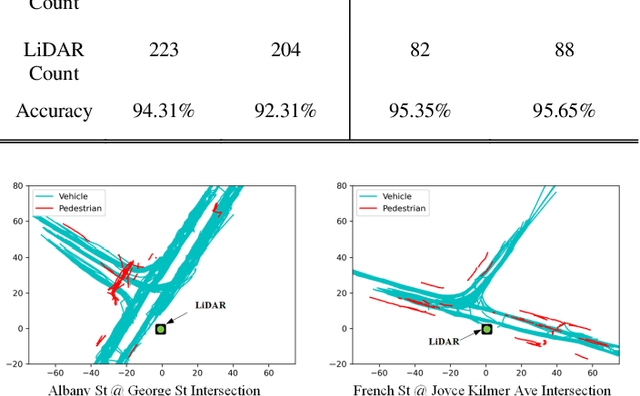
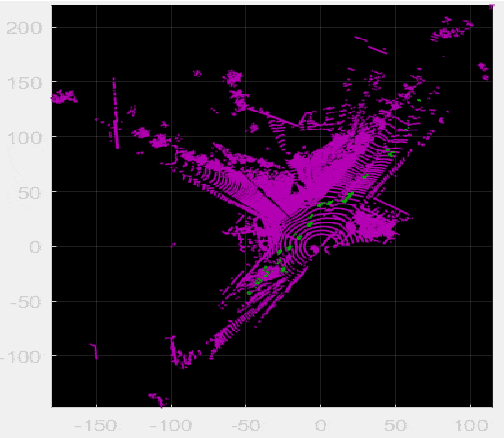
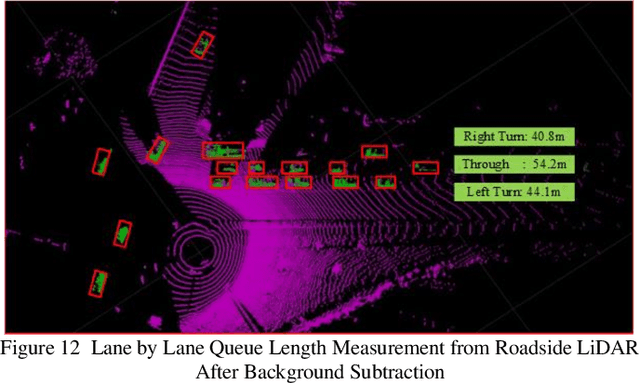
Background modeling is widely used for intelligent surveillance systems to detect the moving targets by subtracting the static background components. Most roadside LiDAR object detection methods filter out foreground points by comparing new points to pre-trained background references based on descriptive statistics over many frames (e.g., voxel density, slopes, maximum distance). These solutions are not efficient under heavy traffic, and parameter values are hard to transfer from one scenario to another. In early studies, the video-based background modeling methods were considered not suitable for roadside LiDAR surveillance systems due to the sparse and unstructured point clouds data. In this paper, the raw LiDAR data were transformed into a multi-dimensional tensor structure based on the elevation and azimuth value of each LiDAR point. With this high-order data representation, we break the barrier to allow the efficient Gaussian Mixture Model (GMM) method for roadside LiDAR background modeling. The probabilistic GMM is built with superior agility and real-time capability. The proposed Method was compared against two state-of-the-art roadside LiDAR background models and evaluated based on point level, object level, and path level, demonstrating better robustness under heavy traffic and challenging weather. This multimodal GMM method is capable of handling dynamic backgrounds with noisy measurements and substantially enhances the infrastructure-based LiDAR object detection, whereby various 3D modeling for smart city applications could be created
Importance-Aware Semantic Segmentation in Self-Driving with Discrete Wasserstein Training
Oct 21, 2020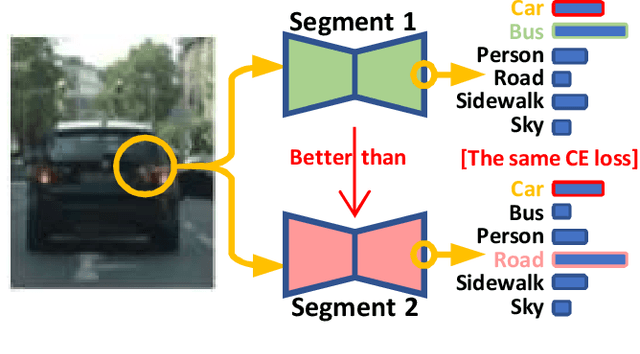
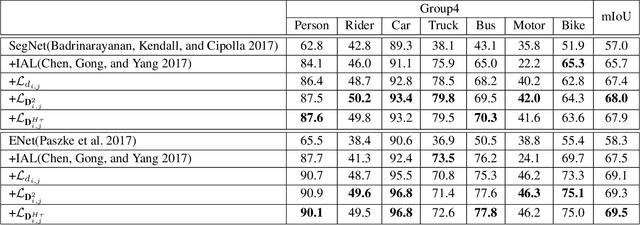
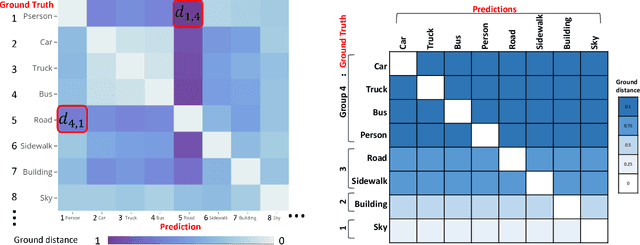
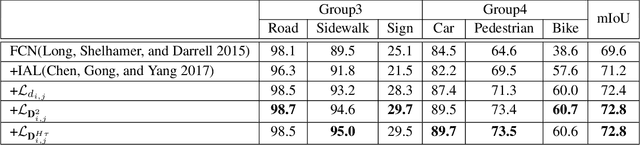
Semantic segmentation (SS) is an important perception manner for self-driving cars and robotics, which classifies each pixel into a pre-determined class. The widely-used cross entropy (CE) loss-based deep networks has achieved significant progress w.r.t. the mean Intersection-over Union (mIoU). However, the cross entropy loss can not take the different importance of each class in an self-driving system into account. For example, pedestrians in the image should be much more important than the surrounding buildings when make a decisions in the driving, so their segmentation results are expected to be as accurate as possible. In this paper, we propose to incorporate the importance-aware inter-class correlation in a Wasserstein training framework by configuring its ground distance matrix. The ground distance matrix can be pre-defined following a priori in a specific task, and the previous importance-ignored methods can be the particular cases. From an optimization perspective, we also extend our ground metric to a linear, convex or concave increasing function $w.r.t.$ pre-defined ground distance. We evaluate our method on CamVid and Cityscapes datasets with different backbones (SegNet, ENet, FCN and Deeplab) in a plug and play fashion. In our extenssive experiments, Wasserstein loss demonstrates superior segmentation performance on the predefined critical classes for safe-driving.
Unimodal-uniform Constrained Wasserstein Training for Medical Diagnosis
Nov 03, 2019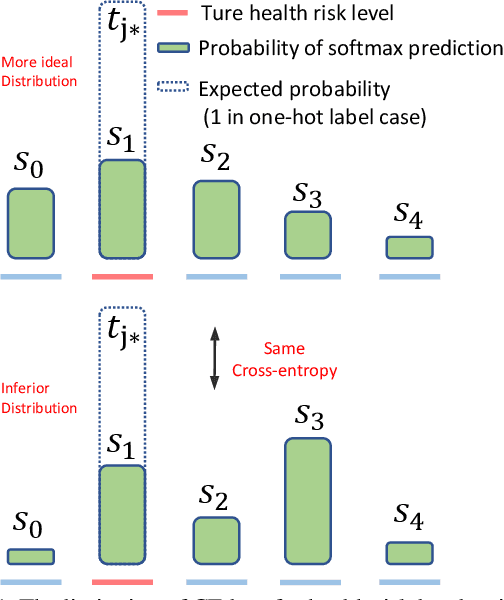
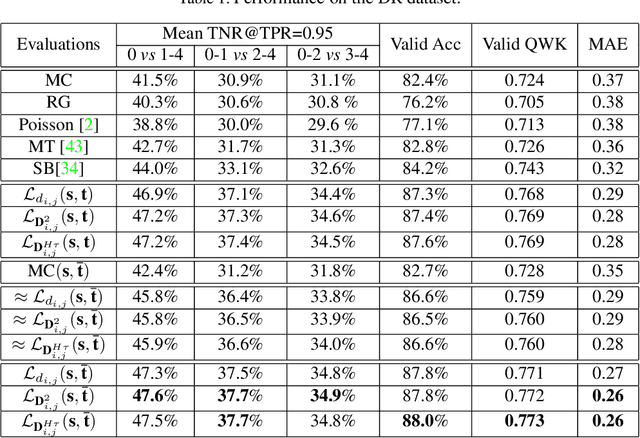
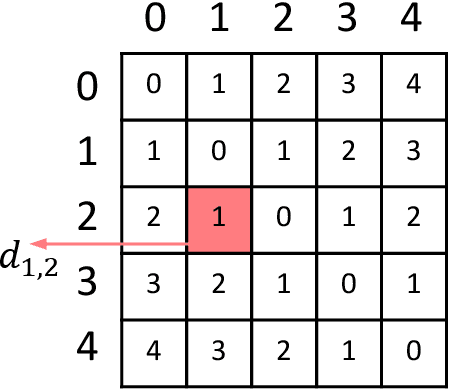
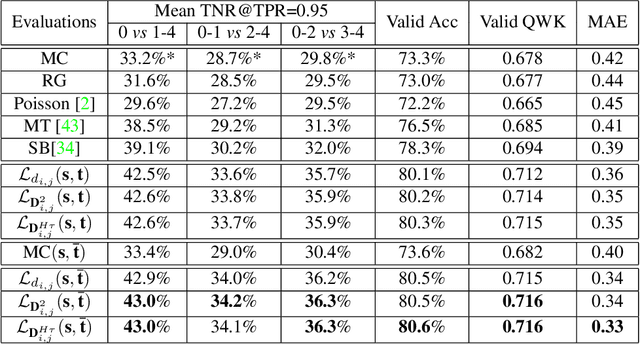
The labels in medical diagnosis task are usually discrete and successively distributed. For example, the Diabetic Retinopathy Diagnosis (DR) involves five health risk levels: no DR (0), mild DR (1), moderate DR (2), severe DR (3) and proliferative DR (4). This labeling system is common for medical disease. Previous methods usually construct a multi-binary-classification task or propose some re-parameter schemes in the output unit. In this paper, we target on this task from the perspective of loss function. More specifically, the Wasserstein distance is utilized as an alternative, explicitly incorporating the inter-class correlations by pre-defining its ground metric. Then, the ground metric which serves as a linear, convex or concave increasing function w.r.t. the Euclidean distance in a line is explored from an optimization perspective. Meanwhile, this paper also proposes of constructing the smoothed target labels that model the inlier and outlier noises by using a unimodal-uniform mixture distribution. Different from the one-hot setting, the smoothed label endues the computation of Wasserstein distance with more challenging features. With either one-hot or smoothed target label, this paper systematically concludes the practical closed-form solution. We evaluate our method on several medical diagnosis tasks (e.g., Diabetic Retinopathy and Ultrasound Breast dataset) and achieve state-of-the-art performance.