 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Fine-Grained Translation Quality Estimation in LRMs through Synergistically Evolving Implicit and Explicit Reasoning
May 29, 2026Large Reasoning Models (LRMs) still struggle with fine-grained translation quality estimation (QE), even with long reasoning chains. We argue that LRMs already possess strong multilingual capabilities, while the core challenge stems from the intrinsic difficulty of learning the fine-grained QE task. In this paper, we propose RIEQE (Reasoning both Implicitly and Explicitly for QE), a simple two-stage training framework that enables the co-evolution of implicit (layer-wise) and explicit (token-wise) reasoning capabilities. To make implicit reasoning feasible, we first decompose the complex QE task into straightforward subtasks. Based on this, our two-stage approach applies: (1) NonThinking-SFT, Supervised Fine-Tuning (SFT) without reasoning chains to directly boost the model's implicit reasoning tendency and capability; and (2) Thinking-RLVR, standard Reinforcement Learning with Verifiable Reward (RLVR) to subsequently strengthen explicit reasoning. Results demonstrate that implicit and explicit reasoning synergistically co-evolve under our framework. On the WMT test sets, RIEQE based on Qwen3-4B-Thinking-2507 surpasses all baselines in explicit reasoning performance, while its implicit reasoning capability is also comparable to the best current encoder-based models. We further provide evidence for the synergistic collaboration between implicit and explicit reasoning, showing how they mutually benefit each other.
TAPO: Translation Augmented Policy Optimization for Multilingual Mathematical Reasoning
Mar 26, 2026Large Language Models (LLMs) have demonstrated remarkable proficiency in English mathematical reasoning, yet a significant performance disparity persists in multilingual contexts, largely attributed to deficiencies in language understanding. To bridge this gap, we introduce Translation-Augmented Policy Optimization (TAPO), a novel reinforcement learning framework built upon GRPO. TAPO enforces an explicit alignment strategy where the model leverages English as a pivot and follows an understand-then-reason paradigm. Crucially, we employ a step-level relative advantage mechanism that decouples understanding from reasoning, allowing the integration of translation quality rewards without introducing optimization conflicts. Extensive experiments reveal that TAPO effectively synergizes language understanding with reasoning capabilities and is compatible with various models. It outperforms baseline methods in both multilingual mathematical reasoning and translation tasks, while generalizing well to unseen languages and out-of-domain tasks.
Neuron-Aware Data Selection In Instruction Tuning For Large Language Models
Mar 13, 2026Instruction Tuning (IT) has been proven to be an effective approach to unlock the powerful capabilities of large language models (LLMs). Recent studies indicate that excessive IT data can degrade LLMs performance, while carefully selecting a small subset of high-quality IT data can significantly enhance their capabilities. Therefore, identifying the most efficient subset data from the IT dataset to effectively develop either specific or general abilities in LLMs has become a critical challenge. To address this, we propose a novel and efficient framework called NAIT. NAIT evaluates the impact of IT data on LLMs performance by analyzing the similarity of neuron activation patterns between the IT dataset and the target domain capability. Specifically, NAIT captures neuron activation patterns from in-domain datasets of target domain capabilities to construct reusable and transferable neuron activation features. It then evaluates and selects optimal samples based on the similarity between candidate samples and the expected activation features of the target capabilities. Experimental results show that training on the 10\% Alpaca-GPT4 IT data subset selected by NAIT consistently outperforms methods that rely on external advanced models or uncertainty-based features across various tasks. Our findings also reveal the transferability of neuron activation features across different capabilities of LLMs. In particular, IT data with more logical reasoning and programmatic features possesses strong general transferability, enabling models to develop stronger capabilities across multiple tasks, while a stable core subset of data is sufficient to consistently activate fundamental model capabilities and universally improve performance across diverse tasks.
ExpLang: Improved Exploration and Exploitation in LLM Reasoning with On-Policy Thinking Language Selection
Feb 25, 2026Current large reasoning models (LRMs) have shown strong ability on challenging tasks after reinforcement learning (RL) based post-training. However, previous work mainly focuses on English reasoning in expectation of the strongest performance, despite the demonstrated potential advantage of multilingual thinking, as well as the requirement for native thinking traces by global users. In this paper, we propose ExpLang, a novel LLM post-training pipeline that enables on-policy thinking language selection to improve exploration and exploitation during RL with the use of multiple languages. The results show that our method steadily outperforms English-only training with the same training budget, while showing high thinking language compliance for both seen and unseen languages. Analysis shows that, by enabling on-policy thinking language selection as an action during RL, ExpLang effectively extends the RL exploration space with diversified language preference and improves the RL exploitation outcome with leveraged non-English advantage. The method is orthogonal to most RL algorithms and opens up a new perspective on using multilinguality to improve LRMs.
GRRM: Group Relative Reward Modeling for Machine Translation
Feb 15, 2026While Group Relative Policy Optimization (GRPO) offers a powerful framework for LLM post-training, its effectiveness in open-ended domains like Machine Translation hinges on accurate intra-group ranking. We identify that standard Scalar Quality Metrics (SQM) fall short in this context; by evaluating candidates in isolation, they lack the comparative context necessary to distinguish fine-grained linguistic nuances. To address this, we introduce the Group Quality Metric (GQM) paradigm and instantiate it via the Group Relative Reward Model (GRRM). Unlike traditional independent scorers, GRRM processes the entire candidate group jointly, leveraging comparative analysis to rigorously resolve relative quality and adaptive granularity. Empirical evaluations confirm that GRRM achieves competitive ranking accuracy among all baselines. Building on this foundation, we integrate GRRM into the GRPO training loop to optimize the translation policy. Experimental results demonstrate that our framework not only improves general translation quality but also unlocks reasoning capabilities comparable to state-of-the-art reasoning models. We release codes, datasets, and model checkpoints at https://github.com/NJUNLP/GRRM.
Self-Improving Multilingual Long Reasoning via Translation-Reasoning Integrated Training
Feb 05, 2026Long reasoning models often struggle in multilingual settings: they tend to reason in English for non-English questions; when constrained to reasoning in the question language, accuracies drop substantially. The struggle is caused by the limited abilities for both multilingual question understanding and multilingual reasoning. To address both problems, we propose TRIT (Translation-Reasoning Integrated Training), a self-improving framework that integrates the training of translation into multilingual reasoning. Without external feedback or additional multilingual data, our method jointly enhances multilingual question understanding and response generation. On MMATH, our method outperforms multiple baselines by an average of 7 percentage points, improving both answer correctness and language consistency. Further analysis reveals that integrating translation training improves cross-lingual question alignment by over 10 percentage points and enhances translation quality for both mathematical questions and general-domain text, with gains up to 8.4 COMET points on FLORES-200.
PEGRL: Improving Machine Translation by Post-Editing Guided Reinforcement Learning
Feb 03, 2026Reinforcement learning (RL) has shown strong promise for LLM-based machine translation, with recent methods such as GRPO demonstrating notable gains; nevertheless, translation-oriented RL remains challenged by noisy learning signals arising from Monte Carlo return estimation, as well as a large trajectory space that favors global exploration over fine-grained local optimization. We introduce \textbf{PEGRL}, a \textit{two-stage} RL framework that uses post-editing as an auxiliary task to stabilize training and guide overall optimization. At each iteration, translation outputs are sampled to construct post-editing inputs, allowing return estimation in the post-editing stage to benefit from conditioning on the current translation behavior, while jointly supporting both global exploration and fine-grained local optimization. A task-specific weighting scheme further balances the contributions of translation and post-editing objectives, yielding a biased yet more sample-efficient estimator. Experiments on English$\to$Finnish, English$\to$Turkish, and English$\leftrightarrow$Chinese show consistent gains over RL baselines, and for English$\to$Turkish, performance on COMET-KIWI is comparable to advanced LLM-based systems (DeepSeek-V3.2).
Reasoning While Asking: Transforming Reasoning Large Language Models from Passive Solvers to Proactive Inquirers
Jan 29, 2026Reasoning-oriented Large Language Models (LLMs) have achieved remarkable progress with Chain-of-Thought (CoT) prompting, yet they remain fundamentally limited by a \emph{blind self-thinking} paradigm: performing extensive internal reasoning even when critical information is missing or ambiguous. We propose Proactive Interactive Reasoning (PIR), a new reasoning paradigm that transforms LLMs from passive solvers into proactive inquirers that interleave reasoning with clarification. Unlike existing search- or tool-based frameworks that primarily address knowledge uncertainty by querying external environments, PIR targets premise- and intent-level uncertainty through direct interaction with the user. PIR is implemented via two core components: (1) an uncertainty-aware supervised fine-tuning procedure that equips models with interactive reasoning capability, and (2) a user-simulator-based policy optimization framework driven by a composite reward that aligns model behavior with user intent. Extensive experiments on mathematical reasoning, code generation, and document editing demonstrate that PIR consistently outperforms strong baselines, achieving up to 32.70\% higher accuracy, 22.90\% higher pass rate, and 41.36 BLEU improvement, while reducing nearly half of the reasoning computation and unnecessary interaction turns. Further reliability evaluations on factual knowledge, question answering, and missing-premise scenarios confirm the strong generalization and robustness of PIR. Model and code are publicly available at: \href{https://github.com/SUAT-AIRI/Proactive-Interactive-R1}
Align to the Pivot: Dual Alignment with Self-Feedback for Multilingual Math Reasoning
Jan 25, 2026Despite the impressive reasoning abilities demonstrated by large language models (LLMs), empirical evidence indicates that they are not language agnostic as expected, leading to performance declines in multilingual settings, especially for low-resource languages. We attribute the decline to the model's inconsistent multilingual understanding and reasoning alignment. To address this, we present Pivot-Aligned Self-Feedback Multilingual Reasoning (PASMR), aiming to improve the alignment of multilingual math reasoning abilities in LLMs. This approach designates the model's primary language as the pivot language. During training, the model first translates questions into the pivot language to facilitate better alignment of reasoning patterns. The reasoning process in the target language is then supervised by the pivot language's reasoning answers, thereby establishing a cross-lingual self-feedback mechanism without relying on external correct answers or reward models. Extensive experimental results demonstrate that our method enhances both the model's understanding of questions and its reasoning capabilities, leading to notable task improvements.
Making Mathematical Reasoning Adaptive
Oct 06, 2025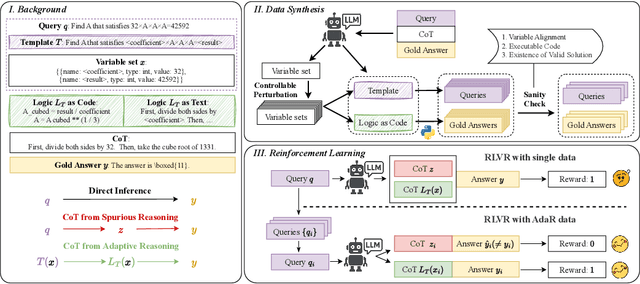
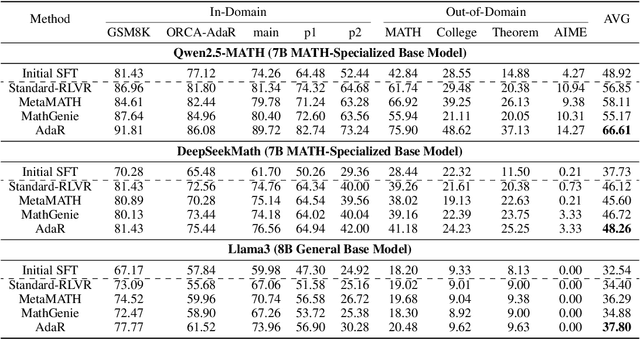


Mathematical reasoning is a primary indicator of large language models (LLMs) intelligence. However, existing LLMs exhibit failures of robustness and generalization. This paper attributes these deficiencies to spurious reasoning, i.e., producing answers from superficial features. To address this challenge, we propose the AdaR framework to enable adaptive reasoning, wherein models rely on problem-solving logic to produce answers. AdaR synthesizes logically equivalent queries by varying variable values, and trains models with RLVR on these data to penalize spurious logic while encouraging adaptive logic. To improve data quality, we extract the problem-solving logic from the original query and generate the corresponding answer by code execution, then apply a sanity check. Experimental results demonstrate that AdaR improves robustness and generalization, achieving substantial improvement in mathematical reasoning while maintaining high data efficiency. Analysis indicates that data synthesis and RLVR function in a coordinated manner to enable adaptive reasoning in LLMs. Subsequent analyses derive key design insights into the effect of critical factors and the applicability to instruct LLMs. Our project is available at https://github.com/LaiZhejian/AdaR