 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRRM: Group Relative Reward Modeling for Machine Translation
Feb 15, 2026While Group Relative Policy Optimization (GRPO) offers a powerful framework for LLM post-training, its effectiveness in open-ended domains like Machine Translation hinges on accurate intra-group ranking. We identify that standard Scalar Quality Metrics (SQM) fall short in this context; by evaluating candidates in isolation, they lack the comparative context necessary to distinguish fine-grained linguistic nuances. To address this, we introduce the Group Quality Metric (GQM) paradigm and instantiate it via the Group Relative Reward Model (GRRM). Unlike traditional independent scorers, GRRM processes the entire candidate group jointly, leveraging comparative analysis to rigorously resolve relative quality and adaptive granularity. Empirical evaluations confirm that GRRM achieves competitive ranking accuracy among all baselines. Building on this foundation, we integrate GRRM into the GRPO training loop to optimize the translation policy. Experimental results demonstrate that our framework not only improves general translation quality but also unlocks reasoning capabilities comparable to state-of-the-art reasoning models. We release codes, datasets, and model checkpoints at https://github.com/NJUNLP/GRRM.
DuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization
Aug 20, 2025We present DuPO, a dual learning-based preference optimization framework that generates annotation-free feedback via a generalized duality. DuPO addresses two key limitations: Reinforcement Learning with Verifiable Rewards (RLVR)'s reliance on costly labels and applicability restricted to verifiable tasks, and traditional dual learning's restriction to strictly dual task pairs (e.g., translation and back-translation). Specifically, DuPO decomposes a primal task's input into known and unknown components, then constructs its dual task to reconstruct the unknown part using the primal output and known information (e.g., reversing math solutions to recover hidden variables), broadening applicability to non-invertible tasks. The quality of this reconstruction serves as a self-supervised reward to optimize the primal task, synergizing with LLMs' ability to instantiate both tasks via a single model. Empirically, DuPO achieves substantial gains across diverse tasks: it enhances the average translation quality by 2.13 COMET over 756 directions, boosts the mathematical reasoning accuracy by an average of 6.4 points on three challenge benchmarks, and enhances performance by 9.3 points as an inference-time reranker (trading computation for accuracy). These results position DuPO as a scalable, general, and annotation-free paradigm for LLM optimization.
Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
Jul 24, 2025



Simultaneous Interpretation (SI) represents one of the most daunting frontiers in the translation industry, with product-level automatic systems long plagued by intractable challenges: subpar transcription and translation quality, lack of real-time speech generation, multi-speaker confusion, and translated speech inflation, especially in long-form discourses. In this study, we introduce Seed-LiveInterpret 2.0, an end-to-end SI model that delivers high-fidelity, ultra-low-latency speech-to-speech generation with voice cloning capabilities. As a fully operational product-level solution, Seed-LiveInterpret 2.0 tackles these challenges head-on through our novel duplex speech-to-speech understanding-generating framework. Experimental results demonstrate that through large-scale pretraining and reinforcement learning, the model achieves a significantly better balance between translation accuracy and latency, validated by human interpreters to exceed 70% correctness in complex scenarios. Notably, Seed-LiveInterpret 2.0 outperforms commercial SI solutions by significant margins in translation quality, while slashing the average latency of cloned speech from nearly 10 seconds to a near-real-time 3 seconds, which is around a near 70% reduction that drastically enhances practical usability.
SeqPO-SiMT: Sequential Policy Optimization for Simultaneous Machine Translation
May 27, 2025



We present Sequential Policy Optimization for Simultaneous Machine Translation (SeqPO-SiMT), a new policy optimization framework that defines the simultaneous machine translation (SiMT) task as a sequential decision making problem, incorporating a tailored reward to enhance translation quality while reducing latency. In contrast to popular Reinforcement Learning from Human Feedback (RLHF) methods, such as PPO and DPO, which are typically applied in single-step tasks, SeqPO-SiMT effectively tackles the multi-step SiMT task. This intuitive framework allows the SiMT LLMs to simulate and refine the SiMT process using a tailored reward. We conduct experiments on six datasets from diverse domains for En to Zh and Zh to En SiMT tasks, demonstrating that SeqPO-SiMT consistently achieves significantly higher translation quality with lower latency. In particular, SeqPO-SiMT outperforms the supervised fine-tuning (SFT) model by 1.13 points in COMET, while reducing the Average Lagging by 6.17 in the NEWSTEST2021 En to Zh dataset. While SiMT operates with far less context than offline translation, the SiMT results of SeqPO-SiMT on 7B LLM surprisingly rival the offline translation of high-performing LLMs, including Qwen-2.5-7B-Instruct and LLaMA-3-8B-Instruct.
From Tens of Hours to Tens of Thousands: Scaling Back-Translation for Speech Recognition
May 22, 2025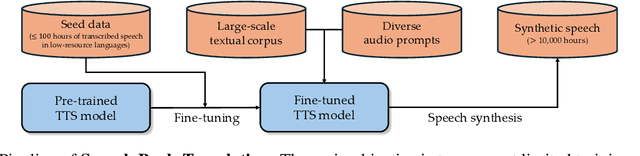
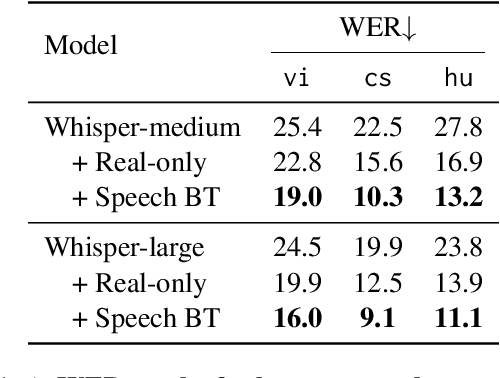
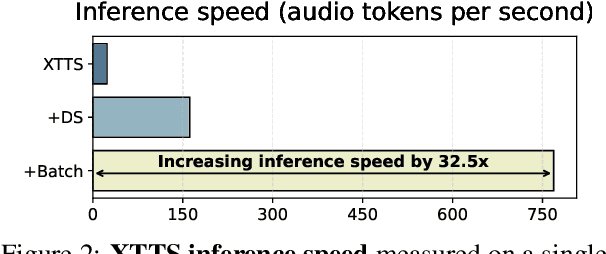

Recent advances in Automatic Speech Recognition (ASR) have been largely fueled by massive speech corpora. However, extending coverage to diverse languages with limited resources remains a formidable challenge. This paper introduces Speech Back-Translation, a scalable pipeline that improves multilingual ASR models by converting large-scale text corpora into synthetic speech via off-the-shelf text-to-speech (TTS) models. We demonstrate that just tens of hours of real transcribed speech can effectively train TTS models to generate synthetic speech at hundreds of times the original volume while maintaining high quality. To evaluate synthetic speech quality, we develop an intelligibility-based assessment framework and establish clear thresholds for when synthetic data benefits ASR training. Using Speech Back-Translation, we generate more than 500,000 hours of synthetic speech in ten languages and continue pre-training Whisper-large-v3, achieving average transcription error reductions of over 30\%. These results highlight the scalability and effectiveness of Speech Back-Translation for enhancing multilingual ASR systems.
Trans-Zero: Self-Play Incentivizes Large Language Models for Multilingual Translation Without Parallel Data
Apr 20, 2025The rise of Large Language Models (LLMs) has reshaped machine translation (MT), but multilingual MT still relies heavily on parallel data for supervised fine-tuning (SFT), facing challenges like data scarcity for low-resource languages and catastrophic forgetting. To address these issues, we propose TRANS-ZERO, a self-play framework that leverages only monolingual data and the intrinsic multilingual knowledge of LLM. TRANS-ZERO combines Genetic Monte-Carlo Tree Search (G-MCTS) with preference optimization, achieving strong translation performance that rivals supervised methods. Experiments demonstrate that this approach not only matches the performance of models trained on large-scale parallel data but also excels in non-English translation directions. Further analysis reveals that G-MCTS itself significantly enhances translation quality by exploring semantically consistent candidates through iterative translations, providing a robust foundation for the framework's succuss.
Towards Achieving Human Parity on End-to-end Simultaneous Speech Translation via LLM Agent
Jul 31, 2024



In this paper, we present Cross Language Agent -- Simultaneous Interpretation, CLASI, a high-quality and human-like Simultaneous Speech Translation (SiST) System. Inspired by professional human interpreters, we utilize a novel data-driven read-write strategy to balance the translation quality and latency. To address the challenge of translating in-domain terminologies, CLASI employs a multi-modal retrieving module to obtain relevant information to augment the translation. Supported by LLMs, our approach can generate error-tolerated translation by considering the input audio, historical context, and retrieved information. Experimental results show that our system outperforms other systems by significant margins. Aligned with professional human interpreters, we evaluate CLASI with a better human evaluation metric, valid information proportion (VIP), which measures the amount of information that can be successfully conveyed to the listeners. In the real-world scenarios, where the speeches are often disfluent, informal, and unclear, CLASI achieves VIP of 81.3% and 78.0% for Chinese-to-English and English-to-Chinese translation directions, respectively. In contrast, state-of-the-art commercial or open-source systems only achieve 35.4% and 41.6%. On the extremely hard dataset, where other systems achieve under 13% VIP, CLASI can still achieve 70% VIP.
Retaining Key Information under High Compression Ratios: Query-Guided Compressor for LLMs
Jun 04, 2024



The growing popularity of Large Language Models has sparked interest in context compression for Large Language Models (LLMs). However, the performance of previous methods degrades dramatically as compression ratios increase, sometimes even falling to the closed-book level. This decline can be attributed to the loss of key information during the compression process. Our preliminary study supports this hypothesis, emphasizing the significance of retaining key information to maintain model performance under high compression ratios. As a result, we introduce Query-Guided Compressor (QGC), which leverages queries to guide the context compression process, effectively preserving key information within the compressed context. Additionally, we employ a dynamic compression strategy. We validate the effectiveness of our proposed QGC on the Question Answering task, including NaturalQuestions, TriviaQA, and HotpotQA datasets. Experimental results show that QGC can consistently perform well even at high compression ratios, which also offers significant benefits in terms of inference cost and throughput.
G-DIG: Towards Gradient-based DIverse and hiGh-quality Instruction Data Selection for Machine Translation
May 21, 2024Large Language Models (LLMs) have demonstrated remarkable abilities in general scenarios. Instruction finetuning empowers them to align with humans in various tasks. Nevertheless, the Diversity and Quality of the instruction data remain two main challenges for instruction finetuning. With regard to this, in this paper, we propose a novel gradient-based method to automatically select high-quality and diverse instruction finetuning data for machine translation. Our key innovation centers around analyzing how individual training examples influence the model during training. Specifically, we select training examples that exert beneficial influences on the model as high-quality ones by means of Influence Function plus a small high-quality seed dataset. Moreover, to enhance the diversity of the training data we maximize the variety of influences they have on the model by clustering on their gradients and resampling. Extensive experiments on WMT22 and FLORES translation tasks demonstrate the superiority of our methods, and in-depth analysis further validates their effectiveness and generalization.
MT-PATCHER: Selective and Extendable Knowledge Distillation from Large Language Models for Machine Translation
Apr 01, 2024



Large Language Models (LLM) have demonstrated their strong ability in the field of machine translation (MT), yet they suffer from high computational cost and latency. Therefore, transferring translation knowledge from giant LLMs to medium-sized machine translation models is a promising research direction. However, traditional knowledge distillation methods do not take the capability of student and teacher models into consideration, therefore repeatedly teaching student models on the knowledge they have learned, and failing to extend to novel contexts and knowledge. In this paper, we propose a framework called MT-Patcher, which transfers knowledge from LLMs to existing MT models in a selective, comprehensive and proactive manner. Considering the current translation ability of student MT models, we only identify and correct their translation errors, instead of distilling the whole translation from the teacher. Leveraging the strong language abilities of LLMs, we instruct LLM teachers to synthesize diverse contexts and anticipate more potential errors for the student. Experiment results on translating both specific language phenomena and general MT benchmarks demonstrate that finetuning the student MT model on about 10% examples can achieve comparable results to the traditional knowledge distillation method, and synthesized potential errors and diverse contexts further improve translation performances on unseen contexts and words.