 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpLang: Improved Exploration and Exploitation in LLM Reasoning with On-Policy Thinking Language Selection
Feb 25, 2026Current large reasoning models (LRMs) have shown strong ability on challenging tasks after reinforcement learning (RL) based post-training. However, previous work mainly focuses on English reasoning in expectation of the strongest performance, despite the demonstrated potential advantage of multilingual thinking, as well as the requirement for native thinking traces by global users. In this paper, we propose ExpLang, a novel LLM post-training pipeline that enables on-policy thinking language selection to improve exploration and exploitation during RL with the use of multiple languages. The results show that our method steadily outperforms English-only training with the same training budget, while showing high thinking language compliance for both seen and unseen languages. Analysis shows that, by enabling on-policy thinking language selection as an action during RL, ExpLang effectively extends the RL exploration space with diversified language preference and improves the RL exploitation outcome with leveraged non-English advantage. The method is orthogonal to most RL algorithms and opens up a new perspective on using multilinguality to improve LRMs.
Could Thinking Multilingually Empower LLM Reasoning?
Apr 16, 2025Previous work indicates that large language models exhibit a significant "English bias", i.e. they often perform better when tasks are presented in English. Interestingly, we have observed that using certain other languages in reasoning tasks can yield better performance than English. However, this phenomenon remains under-explored. In this paper, we explore the upper bound of harnessing multilingualism in reasoning tasks, suggesting that multilingual reasoning promises significantly (by nearly 10 Acc@$k$ points) and robustly (tolerance for variations in translation quality and language choice) higher upper bounds than English-only reasoning. Besides analyzing the reason behind the upper bound and challenges in reaching it, we also find that common answer selection methods cannot achieve this upper bound, due to their limitations and biases. These insights could pave the way for future research aimed at fully harnessing the potential of multilingual reasoning in LLMs.
Understanding LLMs' Cross-Lingual Context Retrieval: How Good It Is And Where It Comes From
Apr 15, 2025



The ability of cross-lingual context retrieval is a fundamental aspect of cross-lingual alignment of large language models (LLMs), where the model extracts context information in one language based on requests in another language. Despite its importance in real-life applications, this ability has not been adequately investigated for state-of-the-art models. In this paper, we evaluate the cross-lingual context retrieval ability of over 40 LLMs across 12 languages to understand the source of this ability, using cross-lingual machine reading comprehension (xMRC) as a representative scenario. Our results show that several small, post-trained open LLMs show strong cross-lingual context retrieval ability, comparable to closed-source LLMs such as GPT-4o, and their estimated oracle performances greatly improve after post-training. Our interpretability analysis shows that the cross-lingual context retrieval process can be divided into two main phases: question encoding and answer retrieval, which are formed in pre-training and post-training, respectively. The phasing stability correlates with xMRC performance, and the xMRC bottleneck lies at the last model layers in the second phase, where the effect of post-training can be evidently observed. Our results also indicate that larger-scale pretraining cannot improve the xMRC performance. Instead, larger LLMs need further multilingual post-training to fully unlock their cross-lingual context retrieval potential. Our code and is available at https://github.com/NJUNLP/Cross-Lingual-Context-Retrieval
Large Language Models Are Cross-Lingual Knowledge-Free Reasoners
Jun 24, 2024



Large Language Models have demonstrated impressive reasoning capabilities across multiple languages. However, the relationship between capabilities in different languages is less explored. In this work, we decompose the process of reasoning tasks into two separated parts: knowledge retrieval and knowledge-free reasoning, and analyze the cross-lingual transferability of them. With adapted and constructed knowledge-free reasoning datasets, we show that the knowledge-free reasoning capability can be nearly perfectly transferred across various source-target language directions despite the secondary impact of resource in some specific target languages, while cross-lingual knowledge retrieval significantly hinders the transfer. Moreover, by analyzing the hidden states and feed-forward network neuron activation during the reasoning tasks, we show that higher similarity of hidden representations and larger overlap of activated neurons could explain the better cross-lingual transferability of knowledge-free reasoning than knowledge retrieval. Thus, we hypothesize that knowledge-free reasoning embeds in some language-shared mechanism, while knowledge is stored separately in different languages.
Limited Out-of-Context Knowledge Reasoning in Large Language Models
Jun 11, 2024



Large Language Models (LLMs) have demonstrated strong capabilities as knowledge bases and significant in-context reasoning capabilities. However, previous work challenges their out-of-context reasoning ability, i.e., the ability to infer information from their training data, instead of from the context or prompt. This paper focuses on a significant facet of out-of-context reasoning: Out-of-Context Knowledge Reasoning (OCKR), which is to combine multiple knowledge to infer new knowledge. We designed a synthetic dataset with seven representative OCKR tasks to systematically assess the OCKR capabilities of LLMs. Using this dataset, we evaluated the LLaMA2-13B-chat model and discovered that its proficiency in this aspect is limited, regardless of whether the knowledge is trained in a separate or adjacent training settings. Moreover, training the model to reason with complete reasoning data did not result in significant improvement. Training the model to perform explicit knowledge retrieval helps in only one of the tasks, indicating that the model's limited OCKR capabilities are due to difficulties in retrieving relevant knowledge. Furthermore, we treat cross-lingual knowledge transfer as a distinct form of OCKR, and evaluate this ability. Our results show that the evaluated model also exhibits limited ability in transferring knowledge across languages. The dataset used in this study is available at https://github.com/NJUNLP/ID-OCKR.
Large Language Models are Good Spontaneous Multilingual Learners: Is the Multilingual Annotated Data Necessary?
May 22, 2024



Recently, Large Language Models (LLMs) have shown impressive language capabilities. However, most of the existing LLMs are all English-centric, which have very unstable and unbalanced performance across different languages. Multilingual alignment is an effective method to enhance the LLMs' multilingual capabilities. In this work, we explore the multilingual alignment paradigm which utilizes translation data and comprehensively investigate the spontaneous multilingual improvement of LLMs. We find that LLMs only instruction-tuned on question translation data without annotated answers are able to get significant multilingual performance enhancement even across a wide range of languages unseen during instruction-tuning. Additionally, we utilize different settings and mechanistic interpretability methods to comprehensively analyze the LLM's performance in the multilingual scenario.
Multilingual Pretraining and Instruction Tuning Improve Cross-Lingual Knowledge Alignment, But Only Shallowly
Apr 06, 2024



Despite their strong ability to retrieve knowledge in English, current large language models show imbalance abilities in different languages. Two approaches are proposed to address this, i.e., multilingual pretraining and multilingual instruction tuning. However, whether and how do such methods contribute to the cross-lingual knowledge alignment inside the models is unknown. In this paper, we propose CLiKA, a systematic framework to assess the cross-lingual knowledge alignment of LLMs in the Performance, Consistency and Conductivity levels, and explored the effect of multilingual pretraining and instruction tuning on the degree of alignment. Results show that: while both multilingual pretraining and instruction tuning are beneficial for cross-lingual knowledge alignment, the training strategy needs to be carefully designed. Namely, continued pretraining improves the alignment of the target language at the cost of other languages, while mixed pretraining affect other languages less. Also, the overall cross-lingual knowledge alignment, especially in the conductivity level, is unsatisfactory for all tested LLMs, and neither multilingual pretraining nor instruction tuning can substantially improve the cross-lingual knowledge conductivity.
Measuring Meaning Composition in the Human Brain with Composition Scores from Large Language Models
Mar 07, 2024The process of meaning composition, wherein smaller units like morphemes or words combine to form the meaning of phrases and sentences, is essential for human sentence comprehension. Despite extensive neurolinguistic research into the brain regions involved in meaning composition, a computational metric to quantify the extent of composition is still lacking. Drawing on the key-value memory interpretation of transformer feed-forward network blocks, we introduce the Composition Score, a novel model-based metric designed to quantify the degree of meaning composition during sentence comprehension. Experimental findings show that this metric correlates with brain clusters associated with word frequency, structural processing, and general sensitivity to words, suggesting the multifaceted nature of meaning composition during human sentence comprehension.
Roles of Scaling and Instruction Tuning in Language Perception: Model vs. Human Attention
Oct 29, 2023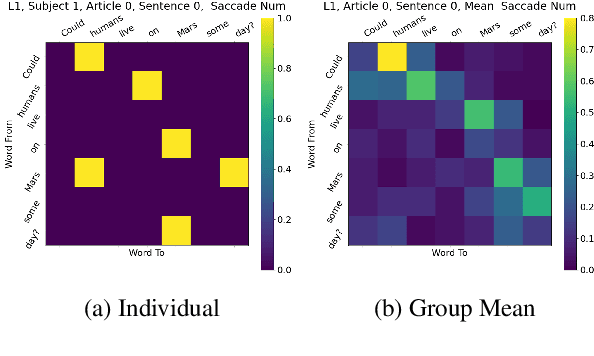
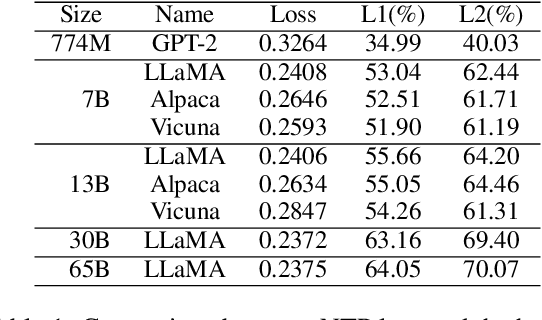
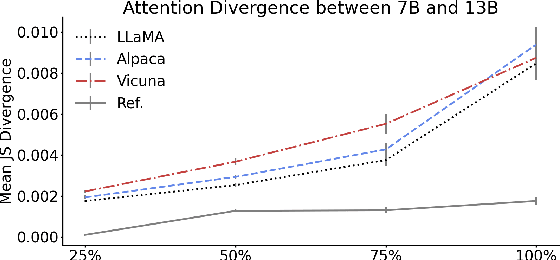
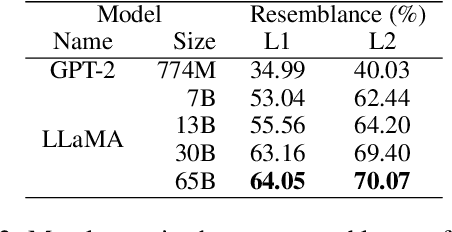
Recent large language models (LLMs) have revealed strong abilities to understand natural language. Since most of them share the same basic structure, i.e. the transformer block, possible contributors to their success in the training process are scaling and instruction tuning. However, how these factors affect the models' language perception is unclear. This work compares the self-attention of several existing LLMs (LLaMA, Alpaca and Vicuna) in different sizes (7B, 13B, 30B, 65B), together with eye saccade, an aspect of human reading attention, to assess the effect of scaling and instruction tuning on language perception. Results show that scaling enhances the human resemblance and improves the effective attention by reducing the trivial pattern reliance, while instruction tuning does not. However, instruction tuning significantly enhances the models' sensitivity to instructions. We also find that current LLMs are consistently closer to non-native than native speakers in attention, suggesting a sub-optimal language perception of all models. Our code and data used in the analysis is available on GitHub.