 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Is No Longer Believing: Frontier Image Generation Models, Synthetic Visual Evidence, and Real-World Risk
Apr 27, 2026Frontier image generation has moved from artistic synthesis toward synthetic visual evidence. Systems such as GPT Image 2, Nano Banana Pro, Nano Banana 2, Grok Imagine, Qwen Image 2.0 Pro, and Seedream 5.0 Lite combine photorealistic rendering, readable typography, reference consistency, editing control, and in several cases reasoning or search-grounded image construction. These capabilities create large benefits for design, education, accessibility, and communication, yet they also weaken one of society's most common trust shortcuts: the belief that a plausible picture is a reliable record. This paper provides a source-grounded technical and policy analysis of synthetic visual risk. We first summarize the public capabilities of recent image models, then analyze public incidents involving fake crisis images, celebrity and public-figure imagery, medical scans, forged-looking documents, synthetic screenshots, phishing assets, and market-moving rumors. We introduce a capability-weighted risk framework that links model affordances to real-world harm in finance, medicine, news, law, emergency response, identity verification, and civic discourse. Our findings show that risk is driven less by photorealism alone than by the convergence of realism, legible text, identity persistence, fast iteration, and distribution context. We argue for layered control: model-side restrictions, cryptographic provenance, visible labeling, platform friction, sector-grade verification, and incident response. The paper closes with practical recommendations for model providers, platforms, newsrooms, financial institutions, healthcare systems, legal organizations, regulators, and ordinary users.
The Rise of Verbal Tics in Large Language Models: A Systematic Analysis Across Frontier Models
Apr 21, 2026As Large Language Models (LLMs) continue to evolve through alignment techniques such as Reinforcement Learning from Human Feedback (RLHF) and Constitutional AI, a growing and increasingly conspicuous phenomenon has emerged: the proliferation of verbal tics -- repetitive, formulaic linguistic patterns that pervade model outputs. These range from sycophantic openers ("That's a great question!", "Awesome!") to pseudo-empathetic affirmations ("I completely understand your concern", "I'm right here to catch you") and overused vocabulary ("delve", "tapestry", "nuanced"). In this paper, we present a systematic analysis of the verbal tic phenomenon across eight state-of-the-art LLMs: GPT-5.4, Claude Opus 4.7, Gemini 3.1 Pro, Grok 4.2, Doubao-Seed-2.0-pro, Kimi K2.5, DeepSeek V3.2, and MiMo-V2-Pro. Utilizing a custom evaluation framework for standardized API-based evaluation, we assess 10,000 prompts across 10 task categories in both English and Chinese, yielding 160,000 model responses. We introduce the Verbal Tic Index (VTI), a composite metric quantifying tic prevalence, and analyze its correlation with sycophancy, lexical diversity, and human-perceived naturalness. Our findings reveal significant inter-model variation: Gemini 3.1 Pro exhibits the highest VTI (0.590), while DeepSeek V3.2 achieves the lowest (0.295). We further demonstrate that verbal tics accumulate over multi-turn conversations, are amplified in subjective tasks, and show distinct cross-lingual patterns. Human evaluation (N = 120) confirms a strong inverse relationship between sycophancy and perceived naturalness (r = -0.87, p < 0.001). These results underscore the "alignment tax" of current training paradigms and highlight the urgent need for more authentic human-AI interaction frameworks.
Council Mode: Mitigating Hallucination and Bias in LLMs via Multi-Agent Consensus
Apr 03, 2026Large Language Models (LLMs), particularly those employing Mixture-of-Experts (MoE) architectures, have achieved remarkable capabilities across diverse natural language processing tasks. However, these models frequently suffer from hallucinations -- generating plausible but factually incorrect content -- and exhibit systematic biases that are amplified by uneven expert activation during inference. In this paper, we propose the Council Mode, a novel multi-agent consensus framework that addresses these limitations by dispatching queries to multiple heterogeneous frontier LLMs in parallel and synthesizing their outputs through a dedicated consensus model. The Council pipeline operates in three phases: (1) an intelligent triage classifier that routes queries based on complexity, (2) parallel expert generation across architecturally diverse models, and (3) a structured consensus synthesis that explicitly identifies agreement, disagreement, and unique findings before producing the final response. We implement and evaluate this architecture within an open-source AI workspace. Our comprehensive evaluation across multiple benchmarks demonstrates that the Council Mode achieves a 35.9% relative reduction in hallucination rates on the HaluEval benchmark and a 7.8-point improvement on TruthfulQA compared to the best-performing individual model, while maintaining significantly lower bias variance across domains. We provide the mathematical formulation of the consensus mechanism, detail the system architecture, and present extensive empirical results with ablation studies.
RexDrug: Reliable Multi-Drug Combination Extraction through Reasoning-Enhanced LLMs
Mar 09, 2026Automated Drug Combination Extraction (DCE) from large-scale biomedical literature is crucial for advancing precision medicine and pharmacological research. However, existing relation extraction methods primarily focus on binary interactions and struggle to model variable-length n-ary drug combinations, where complex compatibility logic and distributed evidence need to be considered. To address these limitations, we propose RexDrug, an end-to-end reasoning-enhanced relation extraction framework for n-ary drug combination extraction based on large language models. RexDrug adopts a two-stage training strategy. First, a multi-agent collaborative mechanism is utilized to automatically generate high-quality expert-like reasoning traces for supervised fine-tuning. Second, reinforcement learning with a multi-dimensional reward function specifically tailored for DCE is applied to further refine reasoning quality and extraction accuracy. Extensive experiments on the DrugComb dataset show that RexDrug consistently outperforms state-of-the-art baselines for n-ary extraction. Additional evaluation on the DDI13 corpus confirms its generalizability to binary drugdrug interaction tasks. Human expert assessment and automatic reasoning metrics further indicates that RexDrug produces coherent medical reasoning while accurately identifying complex therapeutic regimens. These results establish RexDrug as a scalable and reliable solution for complex biomedical relation extraction from unstructured text. The source code and data are available at https://github.com/DUTIR-BioNLP/RexDrug
Self-Improving Multilingual Long Reasoning via Translation-Reasoning Integrated Training
Feb 05, 2026Long reasoning models often struggle in multilingual settings: they tend to reason in English for non-English questions; when constrained to reasoning in the question language, accuracies drop substantially. The struggle is caused by the limited abilities for both multilingual question understanding and multilingual reasoning. To address both problems, we propose TRIT (Translation-Reasoning Integrated Training), a self-improving framework that integrates the training of translation into multilingual reasoning. Without external feedback or additional multilingual data, our method jointly enhances multilingual question understanding and response generation. On MMATH, our method outperforms multiple baselines by an average of 7 percentage points, improving both answer correctness and language consistency. Further analysis reveals that integrating translation training improves cross-lingual question alignment by over 10 percentage points and enhances translation quality for both mathematical questions and general-domain text, with gains up to 8.4 COMET points on FLORES-200.
Making Mathematical Reasoning Adaptive
Oct 06, 2025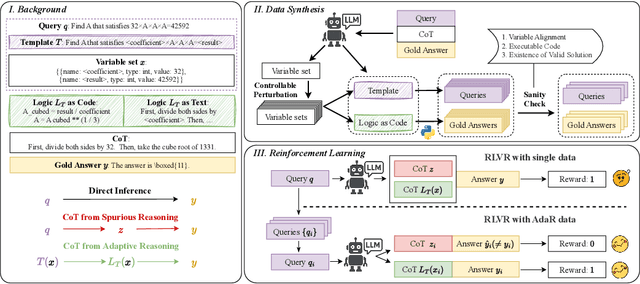
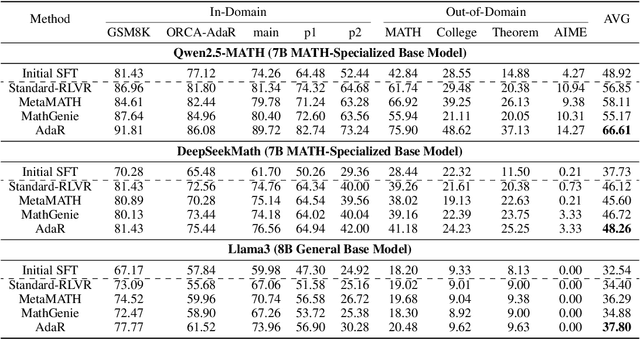


Mathematical reasoning is a primary indicator of large language models (LLMs) intelligence. However, existing LLMs exhibit failures of robustness and generalization. This paper attributes these deficiencies to spurious reasoning, i.e., producing answers from superficial features. To address this challenge, we propose the AdaR framework to enable adaptive reasoning, wherein models rely on problem-solving logic to produce answers. AdaR synthesizes logically equivalent queries by varying variable values, and trains models with RLVR on these data to penalize spurious logic while encouraging adaptive logic. To improve data quality, we extract the problem-solving logic from the original query and generate the corresponding answer by code execution, then apply a sanity check. Experimental results demonstrate that AdaR improves robustness and generalization, achieving substantial improvement in mathematical reasoning while maintaining high data efficiency. Analysis indicates that data synthesis and RLVR function in a coordinated manner to enable adaptive reasoning in LLMs. Subsequent analyses derive key design insights into the effect of critical factors and the applicability to instruct LLMs. Our project is available at https://github.com/LaiZhejian/AdaR
Investigating and Scaling up Code-Switching for Multilingual Language Model Pre-Training
Apr 02, 2025Large language models (LLMs) exhibit remarkable multilingual capabilities despite the extreme language imbalance in the pre-training data. In this paper, we closely examine the reasons behind this phenomenon, focusing on the pre-training corpus. We find that the existence of code-switching, alternating between different languages within a context, is key to multilingual capabilities. We conduct an analysis to investigate code-switching in the pre-training corpus, examining its presence and categorizing it into four types within two quadrants. We then assess its impact on multilingual performance. These types of code-switching data are unbalanced in proportions and demonstrate different effects on facilitating language transfer. To better explore the power of code-switching for language alignment during pre-training, we investigate the strategy of synthetic code-switching. We continuously scale up the synthetic code-switching data and observe remarkable improvements in both benchmarks and representation space. Extensive experiments indicate that incorporating synthetic code-switching data enables better language alignment and generalizes well to high, medium, and low-resource languages with pre-training corpora of varying qualities.
2D Integrated Bayesian Tomography of Plasma Electron Density Profile for HL-3 Based on Gaussian Process
Feb 13, 2025This paper introduces an integrated Bayesian model that combines line integral measurements and point values using Gaussian Process (GP). The proposed method leverages Gaussian Process Regression (GPR) to incorporate point values into 2D profiles and employs coordinate mapping to integrate magnetic flux information for 2D inversion. The average relative error of the reconstructed profile, using the integrated Bayesian tomography model with normalized magnetic flux, is as low as 3.60*10^(-4). Additionally, sensitivity tests were conducted on the number of grids, the standard deviation of synthetic diagnostic data, and noise levels, laying a solid foundation for the application of the model to experimental data. This work not only achieves accurate 2D inversion using the integrated Bayesian model but also provides a robust framework for decoupling pressure information from equilibrium reconstruction, thus making it possible to optimize equilibrium reconstruction using inversion results.
ONION: Physics-Informed Deep Learning Model for Line Integral Diagnostics Across Fusion Devices
Nov 27, 2024This paper introduces a Physics-Informed model architecture that can be adapted to various backbone networks. The model incorporates physical information as additional input and is constrained by a Physics-Informed loss function. Experimental results demonstrate that the additional input of physical information substantially improve the model's ability with a increase in performance observed. Besides, the adoption of the Softplus activation function in the final two fully connected layers significantly enhances model performance. The incorporation of a Physics-Informed loss function has been shown to correct the model's predictions, bringing the back-projections closer to the actual inputs and reducing the errors associated with inversion algorithms. In this work, we have developed a Phantom Data Model to generate customized line integral diagnostic datasets and have also collected SXR diagnostic datasets from EAST and HL-2A. The code, models, and some datasets are publicly available at https://github.com/calledice/onion.
MoE-LPR: Multilingual Extension of Large Language Models through Mixture-of-Experts with Language Priors Routing
Aug 21, 2024



Large Language Models (LLMs) are often English-centric due to the disproportionate distribution of languages in their pre-training data. Enhancing non-English language capabilities through post-pretraining often results in catastrophic forgetting of the ability of original languages. Previous methods either achieve good expansion with severe forgetting or slight forgetting with poor expansion, indicating the challenge of balancing language expansion while preventing forgetting. In this paper, we propose a method called MoE-LPR (Mixture-of-Experts with Language Priors Routing) to alleviate this problem. MoE-LPR employs a two-stage training approach to enhance the multilingual capability. First, the model is post-pretrained into a Mixture-of-Experts (MoE) architecture by upcycling, where all the original parameters are frozen and new experts are added. In this stage, we focus improving the ability on expanded languages, without using any original language data. Then, the model reviews the knowledge of the original languages with replay data amounting to less than 1% of post-pretraining, where we incorporate language priors routing to better recover the abilities of the original languages. Evaluations on multiple benchmarks show that MoE-LPR outperforms other post-pretraining methods. Freezing original parameters preserves original language knowledge while adding new experts preserves the learning ability. Reviewing with LPR enables effective utilization of multilingual knowledge within the parameters. Additionally, the MoE architecture maintains the same inference overhead while increasing total model parameters. Extensive experiments demonstrate MoE-LPR's effectiveness in improving expanded languages and preserving original language proficiency with superior scalability. Code and scripts are freely available at https://github.com/zjwang21/MoE-LPR.git.