 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Really Need to Use Constraint Violation in Constrained Evolutionary Multi-Objective Optimization?
May 28, 2022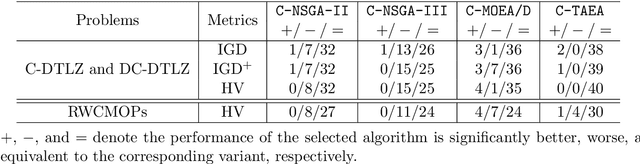
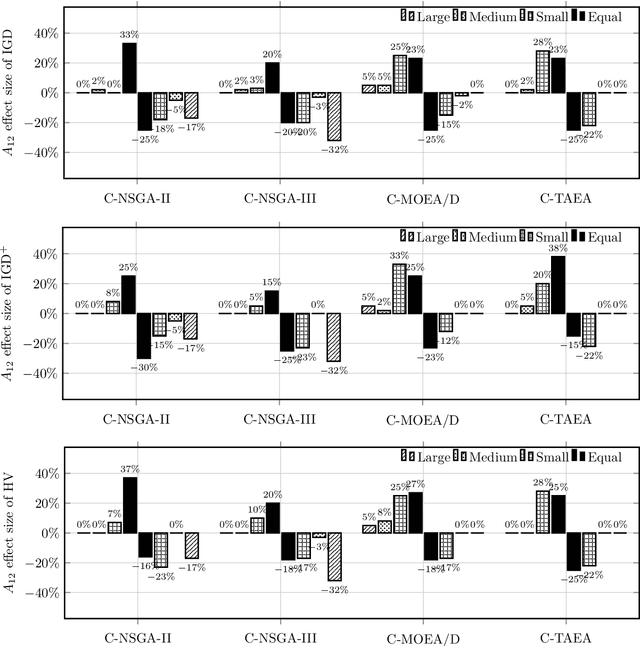
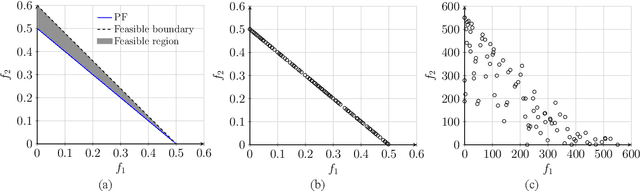
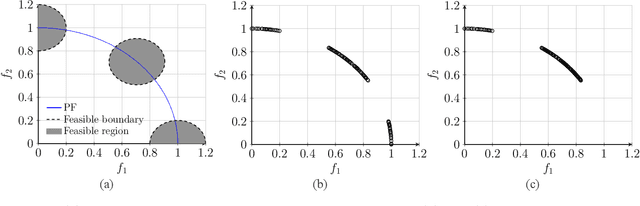
Constraint violation has been a building block to design evolutionary multi-objective optimization algorithms for solving constrained multi-objective optimization problems. However, it is not uncommon that the constraint violation is hardly approachable in real-world black-box optimization scenarios. It is unclear that whether the existing constrained evolutionary multi-objective optimization algorithms, whose environmental selection mechanism are built upon the constraint violation, can still work or not when the formulations of the constraint functions are unknown. Bearing this consideration in mind, this paper picks up four widely used constrained evolutionary multi-objective optimization algorithms as the baseline and develop the corresponding variants that replace the constraint violation by a crisp value. From our experiments on both synthetic and real-world benchmark test problems, we find that the performance of the selected algorithms have not been significantly influenced when the constraint violation is not used to guide the environmental selection.
Improving Transferability for Domain Adaptive Detection Transformers
Apr 29, 2022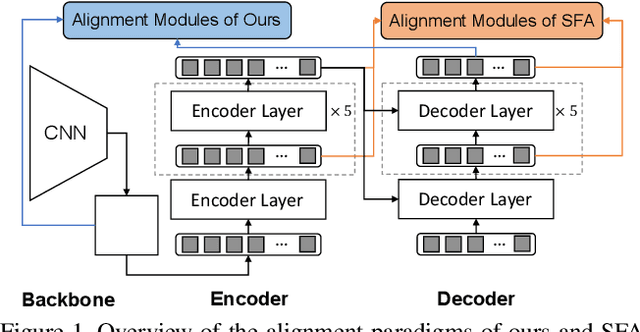
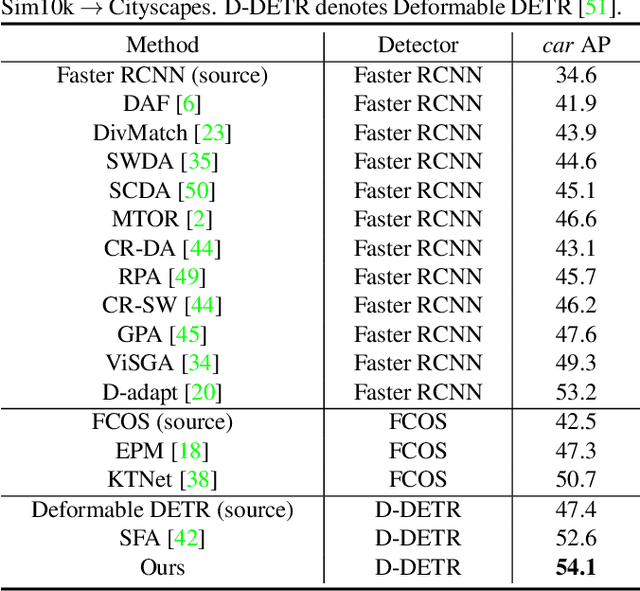
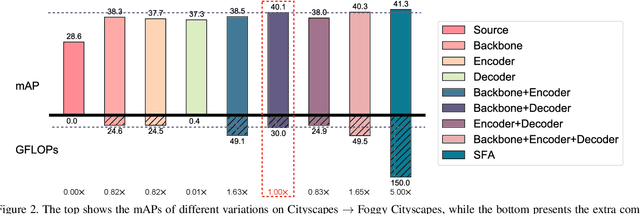
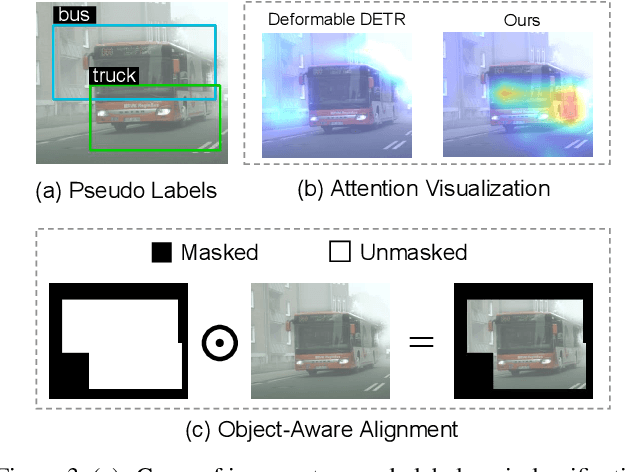
DETR-style detectors stand out amongst in-domain scenarios, but their properties in domain shift settings are under-explored. This paper aims to build a simple but effective baseline with a DETR-style detector on domain shift settings based on two findings. For one, mitigating the domain shift on the backbone and the decoder output features excels in getting favorable results. For another, advanced domain alignment methods in both parts further enhance the performance. Thus, we propose the Object-Aware Alignment (OAA) module and the Optimal Transport based Alignment (OTA) module to achieve comprehensive domain alignment on the outputs of the backbone and the detector. The OAA module aligns the foreground regions identified by pseudo-labels in the backbone outputs, leading to domain-invariant based features. The OTA module utilizes sliced Wasserstein distance to maximize the retention of location information while minimizing the domain gap in the decoder outputs. We implement the findings and the alignment modules into our adaptation method, and it benchmarks the DETR-style detector on the domain shift settings. Experiments on various domain adaptive scenarios validate the effectiveness of our method.
ROMA: Cross-Domain Region Similarity Matching for Unpaired Nighttime Infrared to Daytime Visible Video Translation
Apr 26, 2022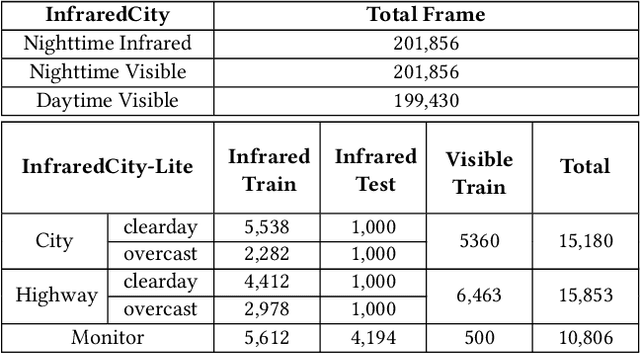
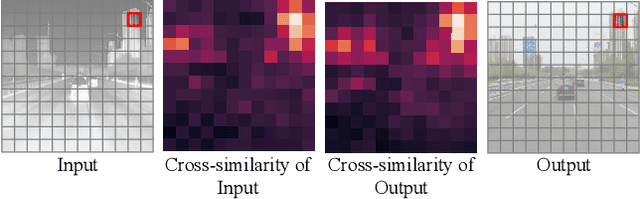
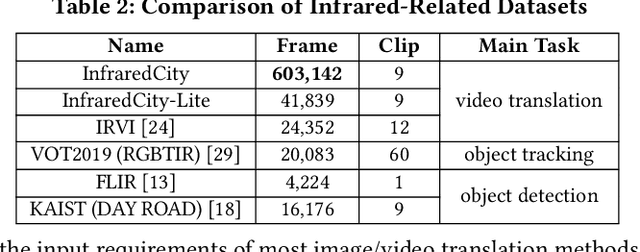
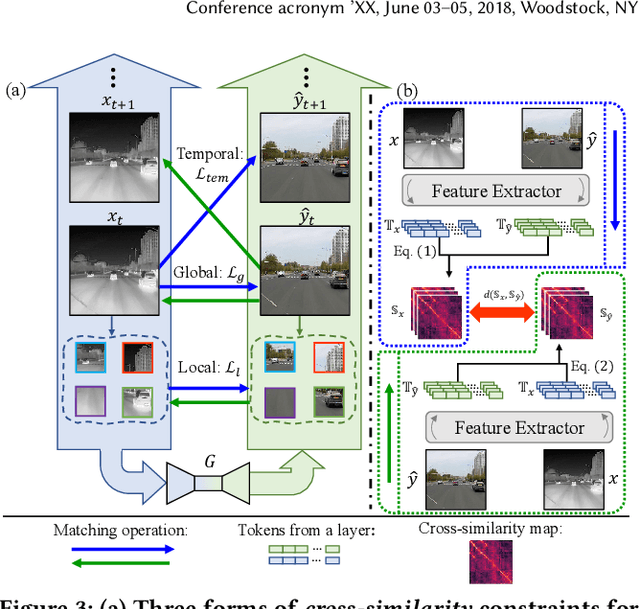
Infrared cameras are often utilized to enhance the night vision since the visible light cameras exhibit inferior efficacy without sufficient illumination. However, infrared data possesses inadequate color contrast and representation ability attributed to its intrinsic heat-related imaging principle. This makes it arduous to capture and analyze information for human beings, meanwhile hindering its application. Although, the domain gaps between unpaired nighttime infrared and daytime visible videos are even huger than paired ones that captured at the same time, establishing an effective translation mapping will greatly contribute to various fields. In this case, the structural knowledge within nighttime infrared videos and semantic information contained in the translated daytime visible pairs could be utilized simultaneously. To this end, we propose a tailored framework ROMA that couples with our introduced cRoss-domain regiOn siMilarity mAtching technique for bridging the huge gaps. To be specific, ROMA could efficiently translate the unpaired nighttime infrared videos into fine-grained daytime visible ones, meanwhile maintain the spatiotemporal consistency via matching the cross-domain region similarity. Furthermore, we design a multiscale region-wise discriminator to distinguish the details from synthesized visible results and real references. Extensive experiments and evaluations for specific applications indicate ROMA outperforms the state-of-the-art methods. Moreover, we provide a new and challenging dataset encouraging further research for unpaired nighttime infrared and daytime visible video translation, named InfraredCity. In particular, it consists of 9 long video clips including City, Highway and Monitor scenarios. All clips could be split into 603,142 frames in total, which are 20 times larger than the recently released daytime infrared-to-visible dataset IRVI.
SePiCo: Semantic-Guided Pixel Contrast for Domain Adaptive Semantic Segmentation
Apr 19, 2022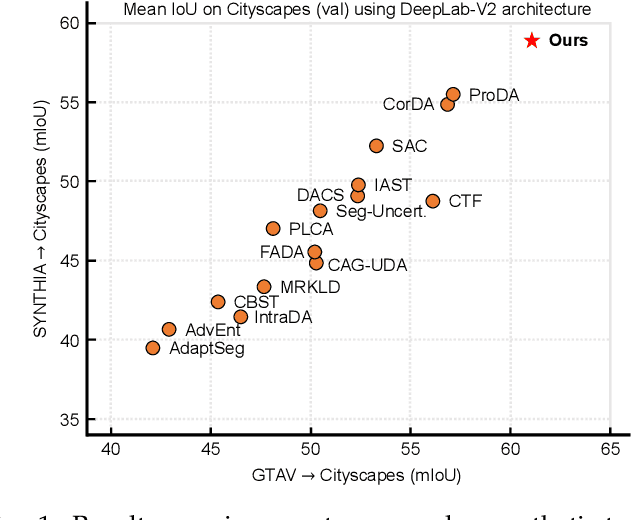
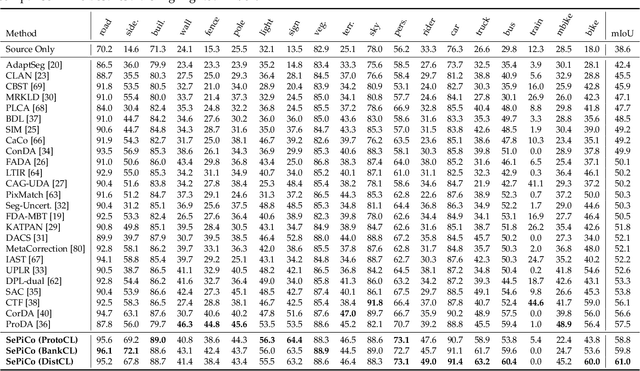
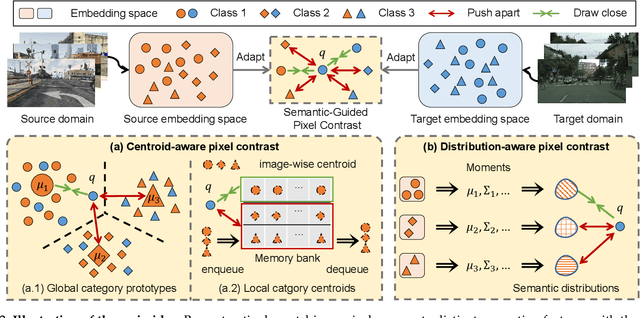
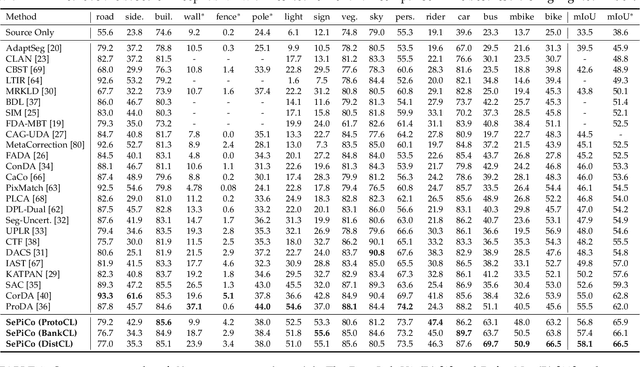
Domain adaptive semantic segmentation attempts to make satisfactory dense predictions on an unlabeled target domain by utilizing the model trained on a labeled source domain. One solution is self-training, which retrains models with target pseudo labels. Many methods tend to alleviate noisy pseudo labels, however, they ignore intrinsic connections among cross-domain pixels with similar semantic concepts. Thus, they would struggle to deal with the semantic variations across domains, leading to less discrimination and poor generalization. In this work, we propose Semantic-Guided Pixel Contrast (SePiCo), a novel one-stage adaptation framework that highlights the semantic concepts of individual pixel to promote learning of class-discriminative and class-balanced pixel embedding space across domains. Specifically, to explore proper semantic concepts, we first investigate a centroid-aware pixel contrast that employs the category centroids of the entire source domain or a single source image to guide the learning of discriminative features. Considering the possible lack of category diversity in semantic concepts, we then blaze a trail of distributional perspective to involve a sufficient quantity of instances, namely distribution-aware pixel contrast, in which we approximate the true distribution of each semantic category from the statistics of labeled source data. Moreover, such an optimization objective can derive a closed-form upper bound by implicitly involving an infinite number of (dis)similar pairs. Extensive experiments show that SePiCo not only helps stabilize training but also yields discriminative features, making significant progress in both daytime and nighttime scenarios. Most notably, SePiCo establishes excellent results on tasks of GTAV/SYNTHIA-to-Cityscapes and Cityscapes-to-Dark Zurich, improving by 12.8, 8.8, and 9.2 mIoUs compared to the previous best method, respectively.
Causality Inspired Representation Learning for Domain Generalization
Mar 27, 2022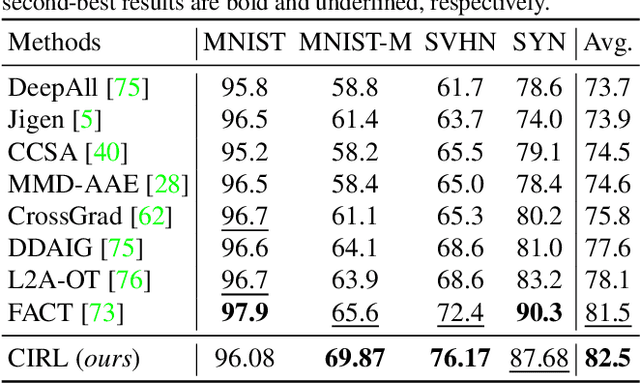

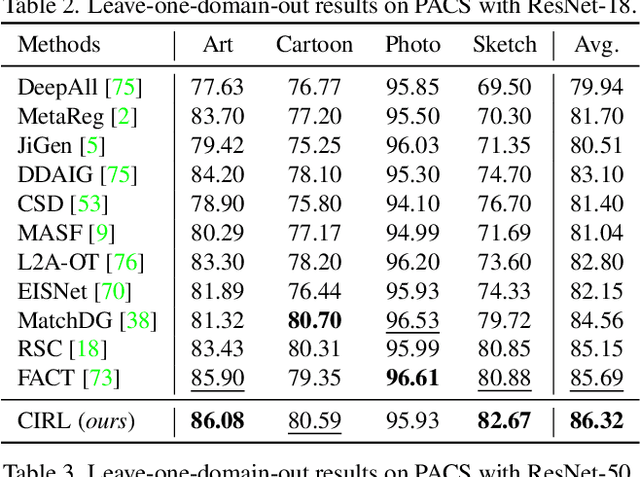
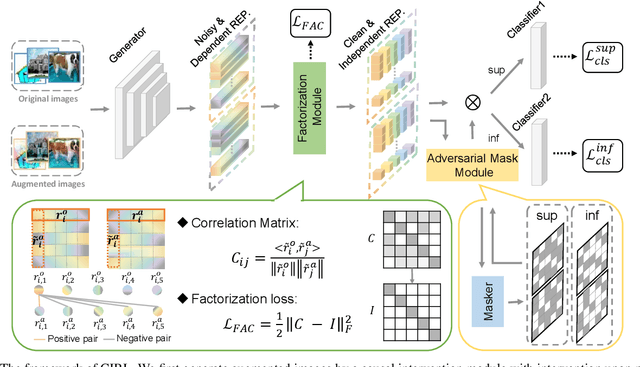
Domain generalization (DG) is essentially an out-of-distribution problem, aiming to generalize the knowledge learned from multiple source domains to an unseen target domain. The mainstream is to leverage statistical models to model the dependence between data and labels, intending to learn representations independent of domain. Nevertheless, the statistical models are superficial descriptions of reality since they are only required to model dependence instead of the intrinsic causal mechanism. When the dependence changes with the target distribution, the statistic models may fail to generalize. In this regard, we introduce a general structural causal model to formalize the DG problem. Specifically, we assume that each input is constructed from a mix of causal factors (whose relationship with the label is invariant across domains) and non-causal factors (category-independent), and only the former cause the classification judgments. Our goal is to extract the causal factors from inputs and then reconstruct the invariant causal mechanisms. However, the theoretical idea is far from practical of DG since the required causal/non-causal factors are unobserved. We highlight that ideal causal factors should meet three basic properties: separated from the non-causal ones, jointly independent, and causally sufficient for the classification. Based on that, we propose a Causality Inspired Representation Learning (CIRL) algorithm that enforces the representations to satisfy the above properties and then uses them to simulate the causal factors, which yields improved generalization ability. Extensive experimental results on several widely used datasets verify the effectiveness of our approach.
Domain Adaptation via Prompt Learning
Feb 14, 2022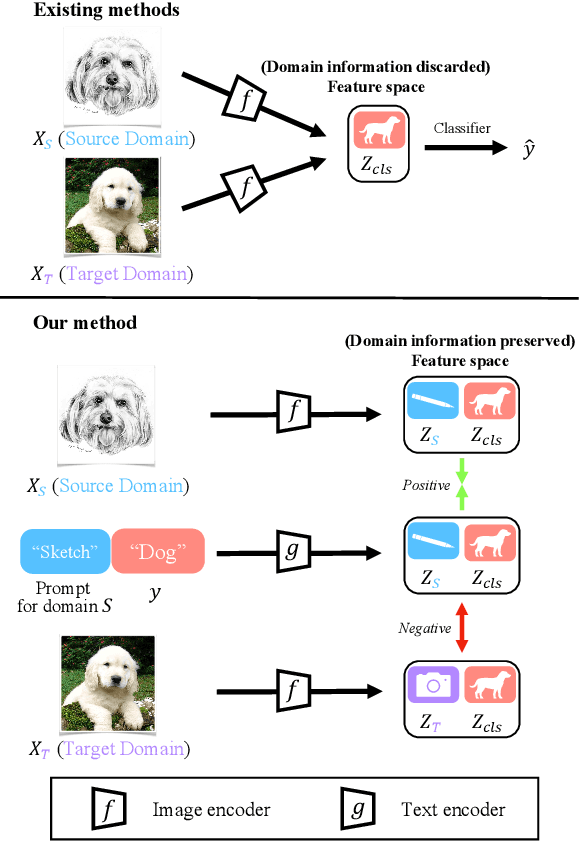

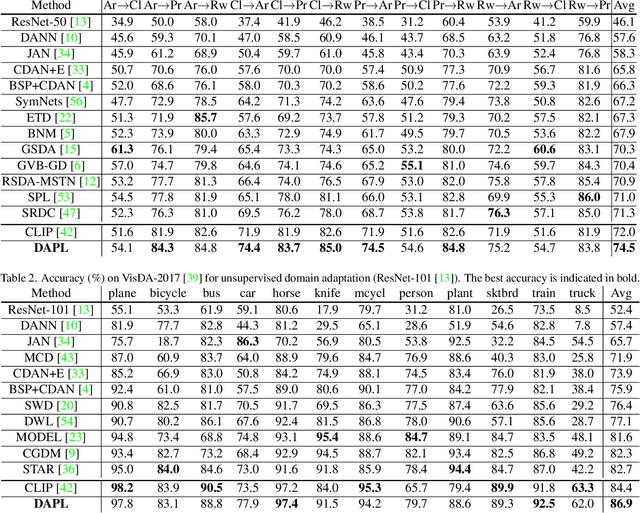
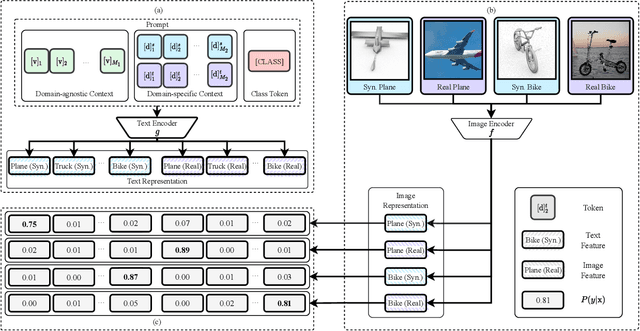
Unsupervised domain adaption (UDA) aims to adapt models learned from a well-annotated source domain to a target domain, where only unlabeled samples are given. Current UDA approaches learn domain-invariant features by aligning source and target feature spaces. Such alignments are imposed by constraints such as statistical discrepancy minimization or adversarial training. However, these constraints could lead to the distortion of semantic feature structures and loss of class discriminability. In this paper, we introduce a novel prompt learning paradigm for UDA, named Domain Adaptation via Prompt Learning (DAPL). In contrast to prior works, our approach makes use of pre-trained vision-language models and optimizes only very few parameters. The main idea is to embed domain information into prompts, a form of representations generated from natural language, which is then used to perform classification. This domain information is shared only by images from the same domain, thereby dynamically adapting the classifier according to each domain. By adopting this paradigm, we show that our model not only outperforms previous methods on several cross-domain benchmarks but also is very efficient to train and easy to implement.
Learning Temporal Rules from Noisy Timeseries Data
Feb 11, 2022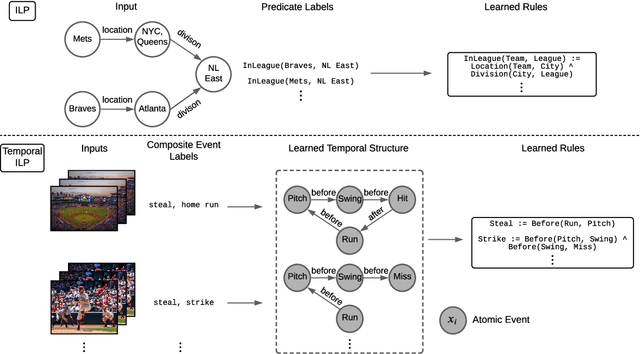
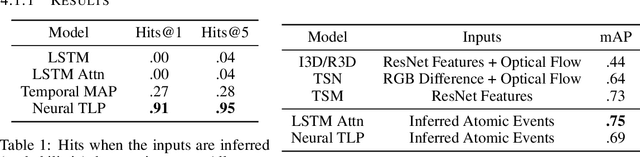
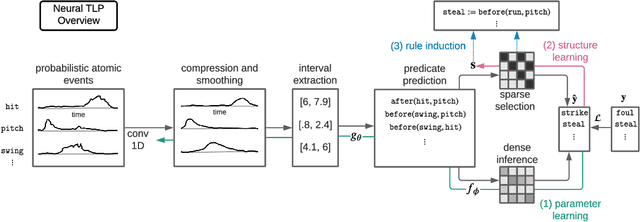
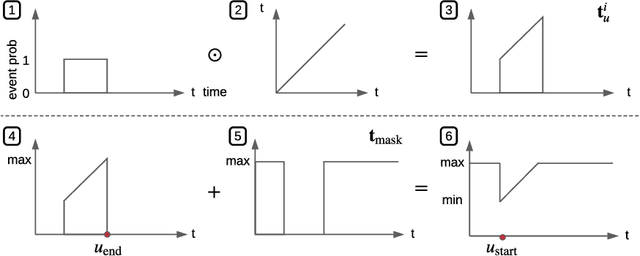
Events across a timeline are a common data representation, seen in different temporal modalities. Individual atomic events can occur in a certain temporal ordering to compose higher level composite events. Examples of a composite event are a patient's medical symptom or a baseball player hitting a home run, caused distinct temporal orderings of patient vitals and player movements respectively. Such salient composite events are provided as labels in temporal datasets and most works optimize models to predict these composite event labels directly. We focus on uncovering the underlying atomic events and their relations that lead to the composite events within a noisy temporal data setting. We propose Neural Temporal Logic Programming (Neural TLP) which first learns implicit temporal relations between atomic events and then lifts logic rules for composite events, given only the composite events labels for supervision. This is done through efficiently searching through the combinatorial space of all temporal logic rules in an end-to-end differentiable manner. We evaluate our method on video and healthcare datasets where it outperforms the baseline methods for rule discovery.
Pre-Trained Language Models for Interactive Decision-Making
Feb 03, 2022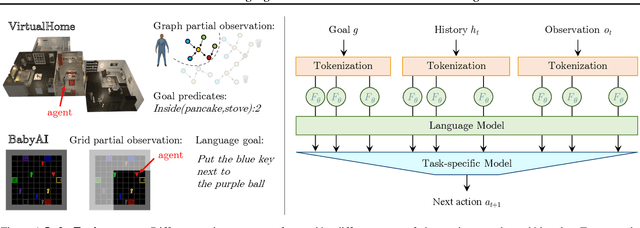
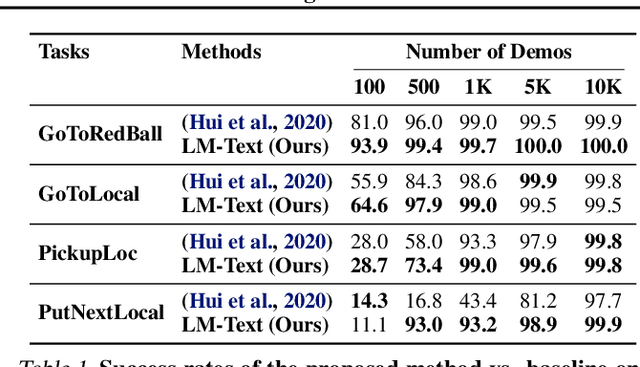
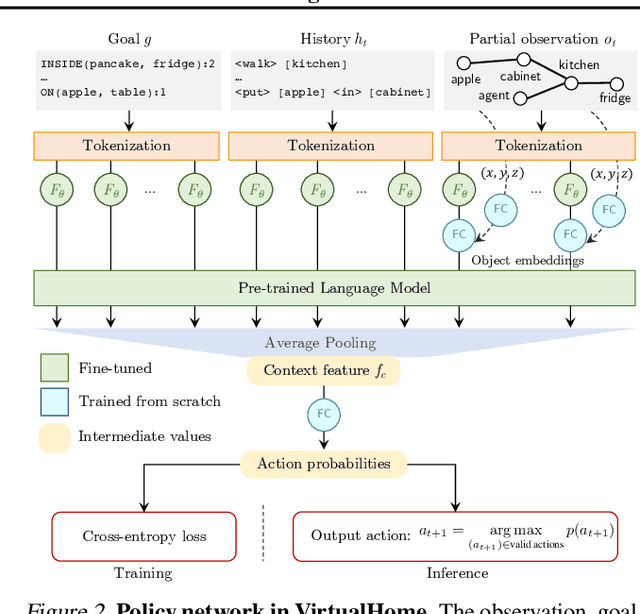
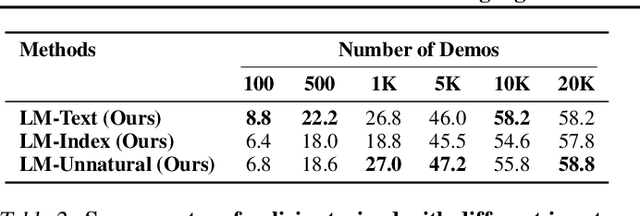
Language model (LM) pre-training has proven useful for a wide variety of language processing tasks, but can such pre-training be leveraged for more general machine learning problems? We investigate the effectiveness of language modeling to scaffold learning and generalization in autonomous decision-making. We describe a framework for imitation learning in which goals and observations are represented as a sequence of embeddings, and translated into actions using a policy network initialized with a pre-trained transformer LM. We demonstrate that this framework enables effective combinatorial generalization across different environments, such as VirtualHome and BabyAI. In particular, for test tasks involving novel goals or novel scenes, initializing policies with language models improves task completion rates by 43.6% in VirtualHome. We hypothesize and investigate three possible factors underlying the effectiveness of LM-based policy initialization. We find that sequential representations (vs. fixed-dimensional feature vectors) and the LM objective (not just the transformer architecture) are both important for generalization. Surprisingly, however, the format of the policy inputs encoding (e.g. as a natural language string vs. an arbitrary sequential encoding) has little influence. Together, these results suggest that language modeling induces representations that are useful for modeling not just language, but also goals and plans; these representations can aid learning and generalization even outside of language processing.
Inferring Commonsense Explanations as Prompts for Future Event Generation
Jan 18, 2022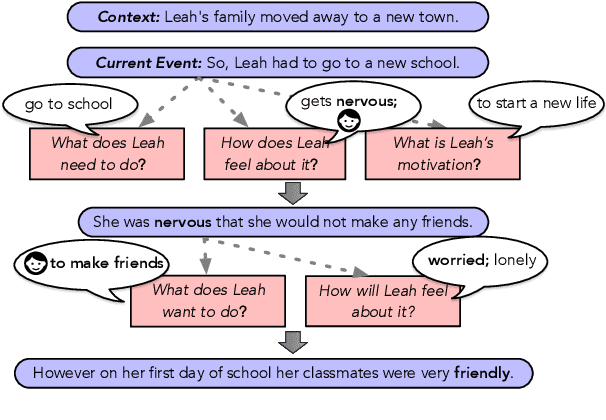

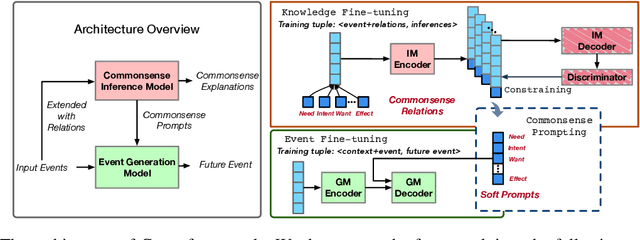
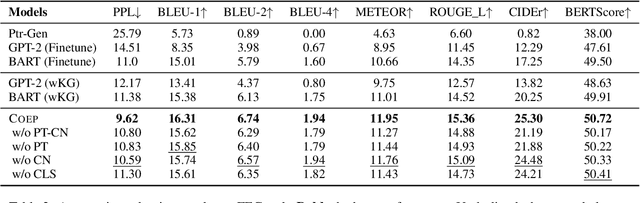
Future Event Generation aims to generate fluent and reasonable future event descriptions given preceding events. It requires not only fluent text generation but also commonsense reasoning to maintain the coherence of the entire event story. However, existing FEG methods are easily trapped into repeated or general events without imposing any logical constraint to the generation process. In this paper, we propose a novel explainable FEG framework that consists of a commonsense inference model (IM) and an event generation model (GM). The IM, which is pre-trained on a commonsense knowledge graph ATOMIC, learns to interpret the preceding events and conducts commonsense reasoning to reveal the characters psychology such as intent, reaction, and needs as latent variables. GM further takes the commonsense knowledge as prompts to guide and enforce the generation of logistically coherent future events. As unique merit, the commonsense prompts can be further decoded into textual descriptions, yielding explanations for the future event. Automatic and human evaluation demonstrate that our approach can generate more coherent, specific, and logical future events than the strong baselines.
Fast solver for J2-perturbed Lambert problem using deep neural network
Jan 09, 2022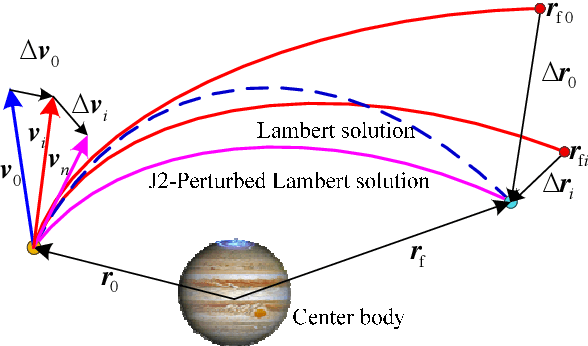
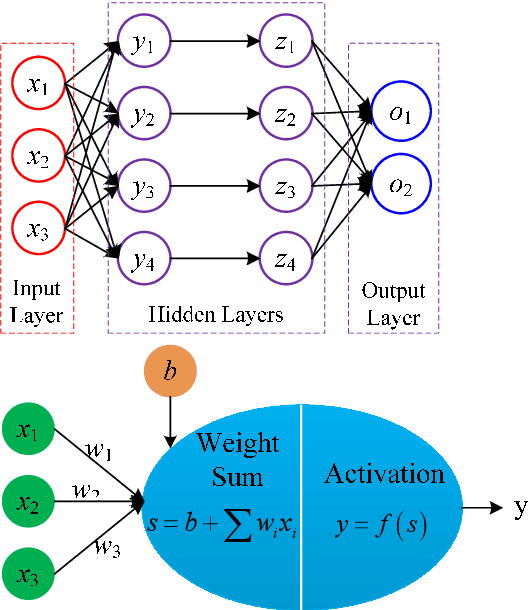

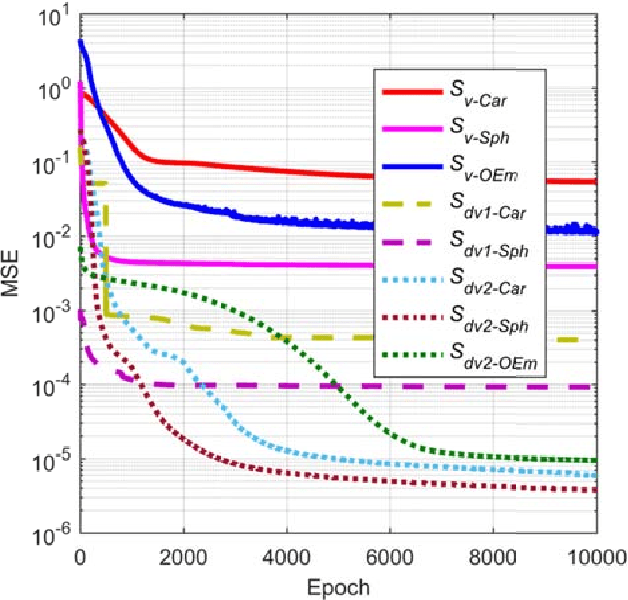
This paper presents a novel and fast solver for the J2-perturbed Lambert problem. The solver consists of an intelligent initial guess generator combined with a differential correction procedure. The intelligent initial guess generator is a deep neural network that is trained to correct the initial velocity vector coming from the solution of the unperturbed Lambert problem. The differential correction module takes the initial guess and uses a forward shooting procedure to further update the initial velocity and exactly meet the terminal conditions. Eight sample forms are analyzed and compared to find the optimum form to train the neural network on the J2-perturbed Lambert problem. The accuracy and performance of this novel approach will be demonstrated on a representative test case: the solution of a multi-revolution J2-perturbed Lambert problem in the Jupiter system. We will compare the performance of the proposed approach against a classical standard shooting method and a homotopy-based perturbed Lambert algorithm. It will be shown that, for a comparable level of accuracy, the proposed method is significantly faster than the other two.
* 10 pages