 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured interactions improve distributed coordination beyond model scaling in a real-world multi-robot system
May 28, 2026Scaling individual robot capabilities is common but costly. Here we investigate a system-level design question in real-world multi-robot coordination: given matched hardware budgets, does restructuring communication among robots yield larger gains than increasing onboard model size? Using a representative transport-and-mapping task with 10 physical robots (5 runs per condition, 60 runs total), we find that switching from fully connected to modular hierarchical interactions improves normalised performance by 47 points (0--100), whereas doubling neural network hidden size yields at most 9 points. Nested mixed-effects model comparisons show a substantially larger improvement in model fit for topology than for scale. The pattern is confirmed in independent SMAC replications; heterogeneous benchmark reanalyses provide secondary supporting consistency checks rather than primary evidence. Performance saturation beyond 1024 hidden units is observed in simulation-calibrated extrapolation, not directly on hardware. These results indicate that interaction structure can play a dominant role within the tested system and task setting, while broader quantitative generalisation remains to be established.
From swept contact to pose: Probe-aware registration via complementary-shape docking
May 20, 2026Accurate registration between a prior model and the real scene is essential for high-precision robotic manipulation, yet optical methods suffer from long calibration chains, line-of-sight constraints, and fabrication errors. We propose a calibration-free alternative that reformulates contact registration as complementary-shape docking between the object and the probe's swept volume, explicitly accounting for probe geometry and leveraging both contact and non-contact evidence. Our solver integrates a global-to-local search via 3D FFT correlation over low-discrepancy SO(3) samples, then followed by continuous SE(3) refinement using Lie-algebra updates and analytic contact sensitivities. This pipeline yields efficient exploration and metric-grade convergence without fragile point correspondences. Simulation across free-form meshes achieved sub-0.04 mm and sub-0.4° accuracy and robustness to pose noise and contact loss. On a tooth-preparation robot, our method attained 0.42 mm and 3.75°, outperforming an optical tracker registration while requiring no external sensors. These results demonstrate a practical and precise registration strategy for surgical and industrial robots.
HopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
Mar 19, 2026Vision-language models (VLMs) show strong multimodal capabilities but still struggle with fine-grained vision-language reasoning. We find that long chain-of-thought (CoT) reasoning exposes diverse failure modes, including perception, reasoning, knowledge, and hallucination errors, which can compound across intermediate steps. However, most existing vision-language data used for reinforcement learning with verifiable rewards (RLVR) does not involve complex reasoning chains that rely on visual evidence throughout, leaving these weaknesses largely unexposed. We therefore propose HopChain, a scalable framework for synthesizing multi-hop vision-language reasoning data for RLVR training of VLMs. Each synthesized multi-hop query forms a logically dependent chain of instance-grounded hops, where earlier hops establish the instances, sets, or conditions needed for later hops, while the final answer remains a specific, unambiguous number suitable for verifiable rewards. We train Qwen3.5-35B-A3B and Qwen3.5-397B-A17B under two RLVR settings: the original data alone, and the original data plus HopChain's multi-hop data, and compare them across 24 benchmarks spanning STEM and Puzzle, General VQA, Text Recognition and Document Understanding, and Video Understanding. Although this multi-hop data is not synthesized for any specific benchmark, it improves 20 of 24 benchmarks on both models, indicating broad and generalizable gains. Consistently, replacing full chained queries with half-multi-hop or single-hop variants reduces the average score across five representative benchmarks from 70.4 to 66.7 and 64.3, respectively. Notably, multi-hop gains peak in long-CoT vision-language reasoning, exceeding 50 points in the ultra-long-CoT regime. These experiments establish HopChain as an effective, scalable framework for synthesizing multi-hop data that improves generalizable vision-language reasoning.
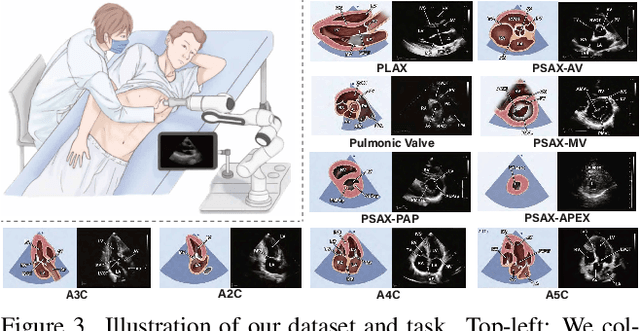
UltraStar: Semantic-Aware Star Graph Modeling for Echocardiography Navigation
Mar 02, 2026Echocardiography is critical for diagnosing cardiovascular diseases, yet the shortage of skilled sonographers hinders timely patient care, due to high operational difficulties. Consequently, research on automated probe navigation has significant clinical potential. To achieve robust navigation, it is essential to leverage historical scanning information, mimicking how experts rely on past feedback to adjust subsequent maneuvers. Practical scanning data collected from sonographers typically consists of noisy trajectories inherently generated through trial-and-error exploration. However, existing methods typically model this history as a sequential chain, forcing models to overfit these noisy paths, leading to performance degradation on long sequences. In this paper, we propose UltraStar, which reformulates probe navigation from path regression to anchor-based global localization. By establishing a Star Graph, UltraStar treats historical keyframes as spatial anchors connected directly to the current view, explicitly modeling geometric constraints for precise positioning. We further enhance the Star Graph with a semantic-aware sampling strategy that actively selects the representative landmarks from massive history logs, reducing redundancy for accurate anchoring. Extensive experiments on a dataset with over 1.31 million samples demonstrate that UltraStar outperforms baselines and scales better with longer input lengths, revealing a more effective topology for history modeling under noisy exploration.
Emulating Human-like Adaptive Vision for Efficient and Flexible Machine Visual Perception
Sep 18, 2025Human vision is highly adaptive, efficiently sampling intricate environments by sequentially fixating on task-relevant regions. In contrast, prevailing machine vision models passively process entire scenes at once, resulting in excessive resource demands scaling with spatial-temporal input resolution and model size, yielding critical limitations impeding both future advancements and real-world application. Here we introduce AdaptiveNN, a general framework aiming to drive a paradigm shift from 'passive' to 'active, adaptive' vision models. AdaptiveNN formulates visual perception as a coarse-to-fine sequential decision-making process, progressively identifying and attending to regions pertinent to the task, incrementally combining information across fixations, and actively concluding observation when sufficient. We establish a theory integrating representation learning with self-rewarding reinforcement learning, enabling end-to-end training of the non-differentiable AdaptiveNN without additional supervision on fixation locations. We assess AdaptiveNN on 17 benchmarks spanning 9 tasks, including large-scale visual recognition, fine-grained discrimination, visual search, processing images from real driving and medical scenarios, language-driven embodied AI, and side-by-side comparisons with humans. AdaptiveNN achieves up to 28x inference cost reduction without sacrificing accuracy, flexibly adapts to varying task demands and resource budgets without retraining, and provides enhanced interpretability via its fixation patterns, demonstrating a promising avenue toward efficient, flexible, and interpretable computer vision. Furthermore, AdaptiveNN exhibits closely human-like perceptual behaviors in many cases, revealing its potential as a valuable tool for investigating visual cognition. Code is available at https://github.com/LeapLabTHU/AdaptiveNN.
CheXWorld: Exploring Image World Modeling for Radiograph Representation Learning
Apr 18, 2025



Humans can develop internal world models that encode common sense knowledge, telling them how the world works and predicting the consequences of their actions. This concept has emerged as a promising direction for establishing general-purpose machine-learning models in recent preliminary works, e.g., for visual representation learning. In this paper, we present CheXWorld, the first effort towards a self-supervised world model for radiographic images. Specifically, our work develops a unified framework that simultaneously models three aspects of medical knowledge essential for qualified radiologists, including 1) local anatomical structures describing the fine-grained characteristics of local tissues (e.g., architectures, shapes, and textures); 2) global anatomical layouts describing the global organization of the human body (e.g., layouts of organs and skeletons); and 3) domain variations that encourage CheXWorld to model the transitions across different appearance domains of radiographs (e.g., varying clarity, contrast, and exposure caused by collecting radiographs from different hospitals, devices, or patients). Empirically, we design tailored qualitative and quantitative analyses, revealing that CheXWorld successfully captures these three dimensions of medical knowledge. Furthermore, transfer learning experiments across eight medical image classification and segmentation benchmarks showcase that CheXWorld significantly outperforms existing SSL methods and large-scale medical foundation models. Code & pre-trained models are available at https://github.com/LeapLabTHU/CheXWorld.
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Apr 18, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has recently demonstrated notable success in enhancing the reasoning capabilities of LLMs, particularly in mathematics and programming tasks. It is widely believed that RLVR enables LLMs to continuously self-improve, thus acquiring novel reasoning abilities that exceed corresponding base models' capacity. In this study, however, we critically re-examines this assumption by measuring the pass@\textit{k} metric with large values of \textit{k} to explore the reasoning capability boundary of the models across a wide range of model families and benchmarks. Surprisingly, the RL does \emph{not}, in fact, elicit fundamentally new reasoning patterns. While RL-trained models outperform their base models at smaller values of $k$ (\eg, $k$=1), base models can achieve a comparable or even higher pass@$k$ score compared to their RL counterparts at large $k$ values. The reasoning paths generated by RL-trained models are already included in the base models' sampling distribution, suggesting that most reasoning abilities manifested in RL-trained models are already obtained by base models. Further analysis shows that RL training boosts the performance by biasing the model's output distribution toward paths that are more likely to yield rewards, therefore sampling correct responses more efficiently. But this also results in a narrower reasoning capability boundary compared to base models. Similar results are observed in visual reasoning tasks trained with RLVR. Moreover, we find that distillation can genuinely introduce new knowledge into the model, different from RLVR. These findings underscore a critical limitation of RLVR in advancing LLM reasoning abilities which requires us to fundamentally rethink the impact of RL training in reasoning LLMs and the need of a better paradigm. Project Page: https://limit-of-RLVR.github.io
EchoWorld: Learning Motion-Aware World Models for Echocardiography Probe Guidance
Apr 17, 2025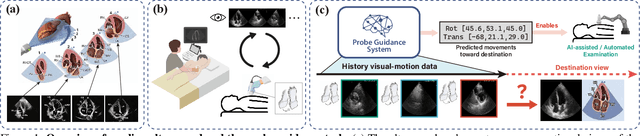


Echocardiography is crucial for cardiovascular disease detection but relies heavily on experienced sonographers. Echocardiography probe guidance systems, which provide real-time movement instructions for acquiring standard plane images, offer a promising solution for AI-assisted or fully autonomous scanning. However, developing effective machine learning models for this task remains challenging, as they must grasp heart anatomy and the intricate interplay between probe motion and visual signals. To address this, we present EchoWorld, a motion-aware world modeling framework for probe guidance that encodes anatomical knowledge and motion-induced visual dynamics, while effectively leveraging past visual-motion sequences to enhance guidance precision. EchoWorld employs a pre-training strategy inspired by world modeling principles, where the model predicts masked anatomical regions and simulates the visual outcomes of probe adjustments. Built upon this pre-trained model, we introduce a motion-aware attention mechanism in the fine-tuning stage that effectively integrates historical visual-motion data, enabling precise and adaptive probe guidance. Trained on more than one million ultrasound images from over 200 routine scans, EchoWorld effectively captures key echocardiographic knowledge, as validated by qualitative analysis. Moreover, our method significantly reduces guidance errors compared to existing visual backbones and guidance frameworks, excelling in both single-frame and sequential evaluation protocols. Code is available at https://github.com/LeapLabTHU/EchoWorld.
Uni-AdaFocus: Spatial-temporal Dynamic Computation for Video Recognition
Dec 15, 2024



This paper presents a comprehensive exploration of the phenomenon of data redundancy in video understanding, with the aim to improve computational efficiency. Our investigation commences with an examination of spatial redundancy, which refers to the observation that the most informative region in each video frame usually corresponds to a small image patch, whose shape, size and location shift smoothly across frames. Motivated by this phenomenon, we formulate the patch localization problem as a dynamic decision task, and introduce a spatially adaptive video recognition approach, termed AdaFocus. In specific, a lightweight encoder is first employed to quickly process the full video sequence, whose features are then utilized by a policy network to identify the most task-relevant regions. Subsequently, the selected patches are inferred by a high-capacity deep network for the final prediction. The full model can be trained in end-to-end conveniently. Furthermore, AdaFocus can be extended by further considering temporal and sample-wise redundancies, i.e., allocating the majority of computation to the most task-relevant frames, and minimizing the computation spent on relatively "easier" videos. Our resulting approach, Uni-AdaFocus, establishes a comprehensive framework that seamlessly integrates spatial, temporal, and sample-wise dynamic computation, while it preserves the merits of AdaFocus in terms of efficient end-to-end training and hardware friendliness. In addition, Uni-AdaFocus is general and flexible as it is compatible with off-the-shelf efficient backbones (e.g., TSM and X3D), which can be readily deployed as our feature extractor, yielding a significantly improved computational efficiency. Empirically, extensive experiments based on seven benchmark datasets and three application scenarios substantiate that Uni-AdaFocus is considerably more efficient than the competitive baselines.
Bridging the Divide: Reconsidering Softmax and Linear Attention
Dec 09, 2024



Widely adopted in modern Vision Transformer designs, Softmax attention can effectively capture long-range visual information; however, it incurs excessive computational cost when dealing with high-resolution inputs. In contrast, linear attention naturally enjoys linear complexity and has great potential to scale up to higher-resolution images. Nonetheless, the unsatisfactory performance of linear attention greatly limits its practical application in various scenarios. In this paper, we take a step forward to close the gap between the linear and Softmax attention with novel theoretical analyses, which demystify the core factors behind the performance deviations. Specifically, we present two key perspectives to understand and alleviate the limitations of linear attention: the injective property and the local modeling ability. Firstly, we prove that linear attention is not injective, which is prone to assign identical attention weights to different query vectors, thus adding to severe semantic confusion since different queries correspond to the same outputs. Secondly, we confirm that effective local modeling is essential for the success of Softmax attention, in which linear attention falls short. The aforementioned two fundamental differences significantly contribute to the disparities between these two attention paradigms, which is demonstrated by our substantial empirical validation in the paper. In addition, more experiment results indicate that linear attention, as long as endowed with these two properties, can outperform Softmax attention across various tasks while maintaining lower computation complexity. Code is available at https://github.com/LeapLabTHU/InLine.