 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResearchRubrics: A Benchmark of Prompts and Rubrics For Evaluating Deep Research Agents
Nov 10, 2025Deep Research (DR) is an emerging agent application that leverages large language models (LLMs) to address open-ended queries. It requires the integration of several capabilities, including multi-step reasoning, cross-document synthesis, and the generation of evidence-backed, long-form answers. Evaluating DR remains challenging because responses are lengthy and diverse, admit many valid solutions, and often depend on dynamic information sources. We introduce ResearchRubrics, a standardized benchmark for DR built with over 2,800+ hours of human labor that pairs realistic, domain-diverse prompts with 2,500+ expert-written, fine-grained rubrics to assess factual grounding, reasoning soundness, and clarity. We also propose a new complexity framework for categorizing DR tasks along three axes: conceptual breadth, logical nesting, and exploration. In addition, we develop human and model-based evaluation protocols that measure rubric adherence for DR agents. We evaluate several state-of-the-art DR systems and find that even leading agents like Gemini's DR and OpenAI's DR achieve under 68% average compliance with our rubrics, primarily due to missed implicit context and inadequate reasoning about retrieved information. Our results highlight the need for robust, scalable assessment of deep research capabilities, to which end we release ResearchRubrics(including all prompts, rubrics, and evaluation code) to facilitate progress toward well-justified research assistants.
Online Rubrics Elicitation from Pairwise Comparisons
Oct 08, 2025



Rubrics provide a flexible way to train LLMs on open-ended long-form answers where verifiable rewards are not applicable and human preferences provide coarse signals. Prior work shows that reinforcement learning with rubric-based rewards leads to consistent gains in LLM post-training. Most existing approaches rely on rubrics that remain static over the course of training. Such static rubrics, however, are vulnerable to reward-hacking type behaviors and fail to capture emergent desiderata that arise during training. We introduce Online Rubrics Elicitation (OnlineRubrics), a method that dynamically curates evaluation criteria in an online manner through pairwise comparisons of responses from current and reference policies. This online process enables continuous identification and mitigation of errors as training proceeds. Empirically, this approach yields consistent improvements of up to 8% over training exclusively with static rubrics across AlpacaEval, GPQA, ArenaHard as well as the validation sets of expert questions and rubrics. We qualitatively analyze the elicited criteria and identify prominent themes such as transparency, practicality, organization, and reasoning.
Agent-RLVR: Training Software Engineering Agents via Guidance and Environment Rewards
Jun 13, 2025Reinforcement Learning from Verifiable Rewards (RLVR) has been widely adopted as the de facto method for enhancing the reasoning capabilities of large language models and has demonstrated notable success in verifiable domains like math and competitive programming tasks. However, the efficacy of RLVR diminishes significantly when applied to agentic environments. These settings, characterized by multi-step, complex problem solving, lead to high failure rates even for frontier LLMs, as the reward landscape is too sparse for effective model training via conventional RLVR. In this work, we introduce Agent-RLVR, a framework that makes RLVR effective in challenging agentic settings, with an initial focus on software engineering tasks. Inspired by human pedagogy, Agent-RLVR introduces agent guidance, a mechanism that actively steers the agent towards successful trajectories by leveraging diverse informational cues. These cues, ranging from high-level strategic plans to dynamic feedback on the agent's errors and environmental interactions, emulate a teacher's guidance, enabling the agent to navigate difficult solution spaces and promotes active self-improvement via additional environment exploration. In the Agent-RLVR training loop, agents first attempt to solve tasks to produce initial trajectories, which are then validated by unit tests and supplemented with agent guidance. Agents then reattempt with guidance, and the agent policy is updated with RLVR based on the rewards of these guided trajectories. Agent-RLVR elevates the pass@1 performance of Qwen-2.5-72B-Instruct from 9.4% to 22.4% on SWE-Bench Verified. We find that our guidance-augmented RLVR data is additionally useful for test-time reward model training, shown by further boosting pass@1 to 27.8%. Agent-RLVR lays the groundwork for training agents with RLVR in complex, real-world environments where conventional RL methods struggle.
InterNeRF: Scaling Radiance Fields via Parameter Interpolation
Jun 17, 2024Neural Radiance Fields (NeRFs) have unmatched fidelity on large, real-world scenes. A common approach for scaling NeRFs is to partition the scene into regions, each of which is assigned its own parameters. When implemented naively, such an approach is limited by poor test-time scaling and inconsistent appearance and geometry. We instead propose InterNeRF, a novel architecture for rendering a target view using a subset of the model's parameters. Our approach enables out-of-core training and rendering, increasing total model capacity with only a modest increase to training time. We demonstrate significant improvements in multi-room scenes while remaining competitive on standard benchmarks.
Geometry Aware Field-to-field Transformations for 3D Semantic Segmentation
Oct 08, 2023



We present a novel approach to perform 3D semantic segmentation solely from 2D supervision by leveraging Neural Radiance Fields (NeRFs). By extracting features along a surface point cloud, we achieve a compact representation of the scene which is sample-efficient and conducive to 3D reasoning. Learning this feature space in an unsupervised manner via masked autoencoding enables few-shot segmentation. Our method is agnostic to the scene parameterization, working on scenes fit with any type of NeRF.
Pre-Trained Language Models for Interactive Decision-Making
Feb 03, 2022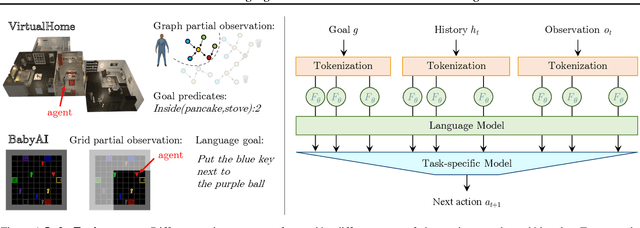
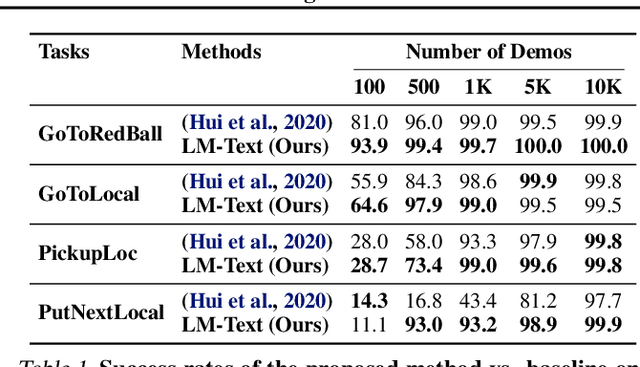
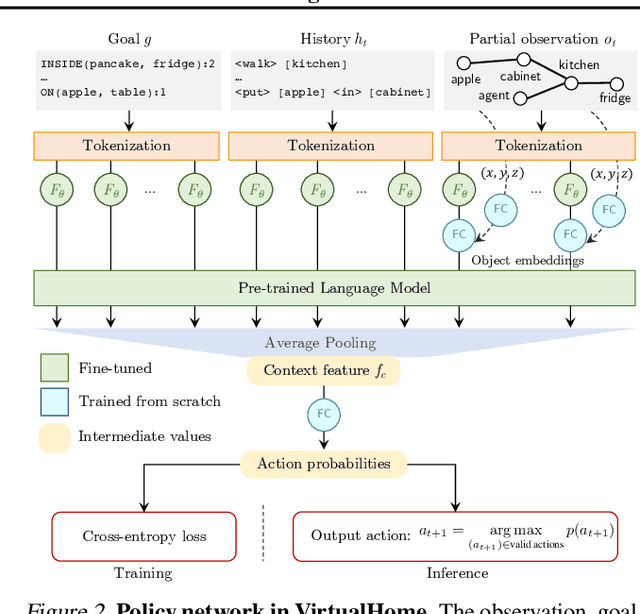
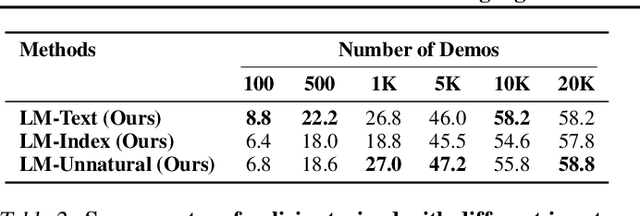
Language model (LM) pre-training has proven useful for a wide variety of language processing tasks, but can such pre-training be leveraged for more general machine learning problems? We investigate the effectiveness of language modeling to scaffold learning and generalization in autonomous decision-making. We describe a framework for imitation learning in which goals and observations are represented as a sequence of embeddings, and translated into actions using a policy network initialized with a pre-trained transformer LM. We demonstrate that this framework enables effective combinatorial generalization across different environments, such as VirtualHome and BabyAI. In particular, for test tasks involving novel goals or novel scenes, initializing policies with language models improves task completion rates by 43.6% in VirtualHome. We hypothesize and investigate three possible factors underlying the effectiveness of LM-based policy initialization. We find that sequential representations (vs. fixed-dimensional feature vectors) and the LM objective (not just the transformer architecture) are both important for generalization. Surprisingly, however, the format of the policy inputs encoding (e.g. as a natural language string vs. an arbitrary sequential encoding) has little influence. Together, these results suggest that language modeling induces representations that are useful for modeling not just language, but also goals and plans; these representations can aid learning and generalization even outside of language processing.