 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Procedural Knowledge and Task Hierarchies for Efficient Instructional Video Pre-training
Feb 24, 2025Instructional videos provide a convenient modality to learn new tasks (ex. cooking a recipe, or assembling furniture). A viewer will want to find a corresponding video that reflects both the overall task they are interested in as well as contains the relevant steps they need to carry out the task. To perform this, an instructional video model should be capable of inferring both the tasks and the steps that occur in an input video. Doing this efficiently and in a generalizable fashion is key when compute or relevant video topics used to train this model are limited. To address these requirements we explicitly mine task hierarchies and the procedural steps associated with instructional videos. We use this prior knowledge to pre-train our model, $\texttt{Pivot}$, for step and task prediction. During pre-training, we also provide video augmentation and early stopping strategies to optimally identify which model to use for downstream tasks. We test this pre-trained model on task recognition, step recognition, and step prediction tasks on two downstream datasets. When pre-training data and compute are limited, we outperform previous baselines along these tasks. Therefore, leveraging prior task and step structures enables efficient training of $\texttt{Pivot}$ for instructional video recommendation.
Exploring Efficient Foundational Multi-modal Models for Video Summarization
Oct 09, 2024Foundational models are able to generate text outputs given prompt instructions and text, audio, or image inputs. Recently these models have been combined to perform tasks on video, such as video summarization. Such video foundation models perform pre-training by aligning outputs from each modality-specific model into the same embedding space. Then the embeddings from each model are used within a language model, which is fine-tuned on a desired instruction set. Aligning each modality during pre-training is computationally expensive and prevents rapid testing of different base modality models. During fine-tuning, evaluation is carried out within in-domain videos where it is hard to understand the generalizability and data efficiency of these methods. To alleviate these issues we propose a plug-and-play video language model. It directly uses the texts generated from each input modality into the language model, avoiding pre-training alignment overhead. Instead of fine-tuning we leverage few-shot instruction adaptation strategies. We compare the performance versus the computational costs for our plug-and-play style method and baseline tuning methods. Finally, we explore the generalizability of each method during domain shift and present insights on what data is useful when training data is limited. Through this analysis, we present practical insights on how to leverage multi-modal foundational models for effective results given realistic compute and data limitations.
On the Efficacy of Text-Based Input Modalities for Action Anticipation
Jan 23, 2024Although the task of anticipating future actions is highly uncertain, information from additional modalities help to narrow down plausible action choices. Each modality provides different environmental context for the model to learn from. While previous multi-modal methods leverage information from modalities such as video and audio, we primarily explore how text inputs for actions and objects can also enable more accurate action anticipation. Therefore, we propose a Multi-modal Anticipative Transformer (MAT), an attention-based video transformer architecture that jointly learns from multi-modal features and text captions. We train our model in two-stages, where the model first learns to predict actions in the video clip by aligning with captions, and during the second stage, we fine-tune the model to predict future actions. Compared to existing methods, MAT has the advantage of learning additional environmental context from two kinds of text inputs: action descriptions during the pre-training stage, and the text inputs for detected objects and actions during modality feature fusion. Through extensive experiments, we evaluate the effectiveness of the pre-training stage, and show that our model outperforms previous methods on all datasets. In addition, we examine the impact of object and action information obtained via text and perform extensive ablations. We evaluate the performance on on three datasets: EpicKitchens-100, EpicKitchens-55 and EGTEA GAZE+; and show that text descriptions do indeed aid in more effective action anticipation.
Learning Temporal Rules from Noisy Timeseries Data
Feb 11, 2022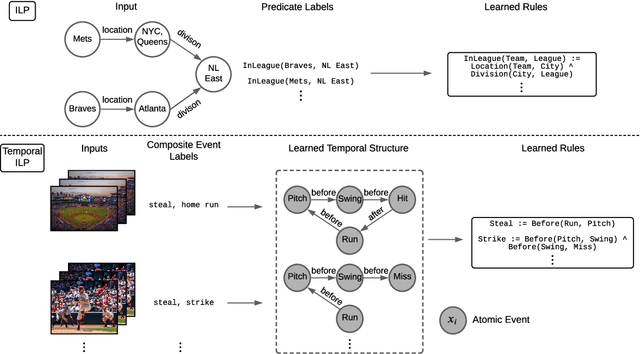
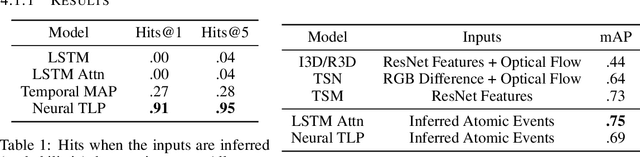
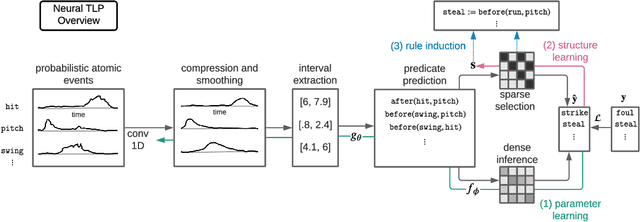
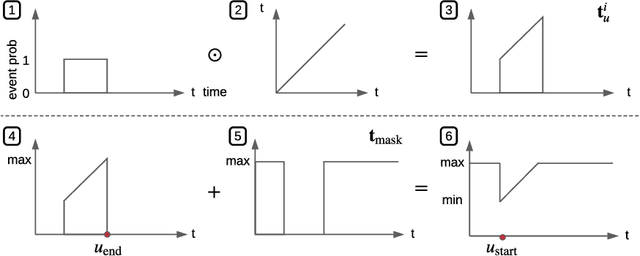
Events across a timeline are a common data representation, seen in different temporal modalities. Individual atomic events can occur in a certain temporal ordering to compose higher level composite events. Examples of a composite event are a patient's medical symptom or a baseball player hitting a home run, caused distinct temporal orderings of patient vitals and player movements respectively. Such salient composite events are provided as labels in temporal datasets and most works optimize models to predict these composite event labels directly. We focus on uncovering the underlying atomic events and their relations that lead to the composite events within a noisy temporal data setting. We propose Neural Temporal Logic Programming (Neural TLP) which first learns implicit temporal relations between atomic events and then lifts logic rules for composite events, given only the composite events labels for supervision. This is done through efficiently searching through the combinatorial space of all temporal logic rules in an end-to-end differentiable manner. We evaluate our method on video and healthcare datasets where it outperforms the baseline methods for rule discovery.
ProTo: Program-Guided Transformer for Program-Guided Tasks
Oct 16, 2021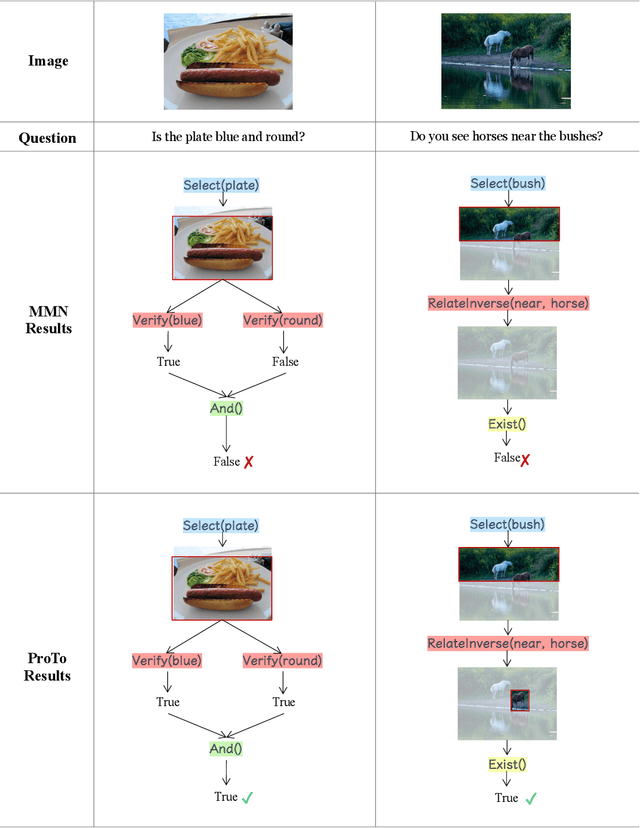
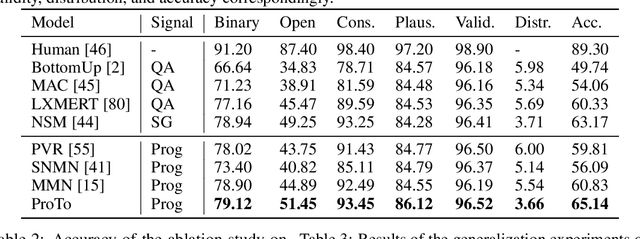
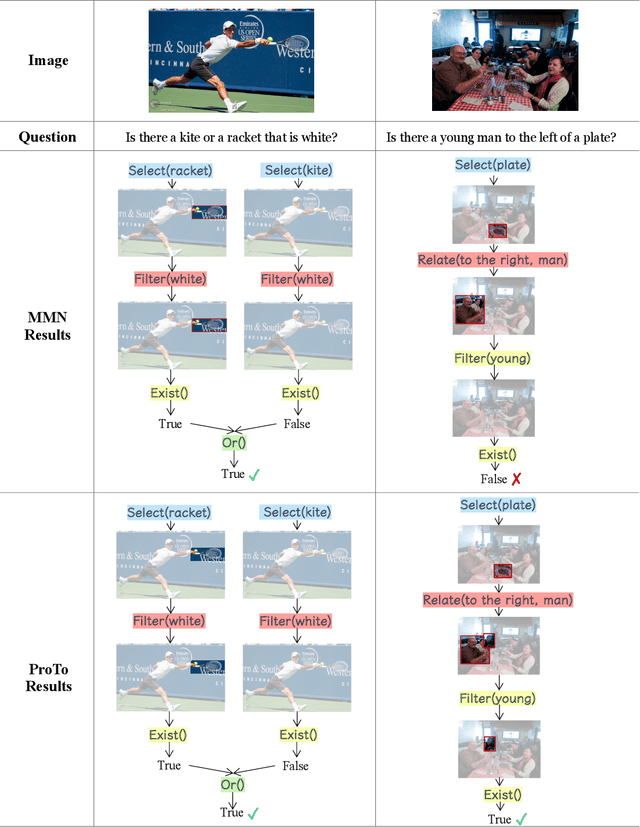
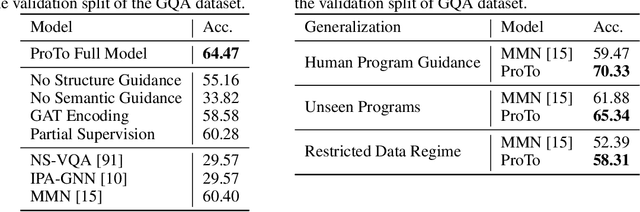
Programs, consisting of semantic and structural information, play an important role in the communication between humans and agents. Towards learning general program executors to unify perception, reasoning, and decision making, we formulate program-guided tasks which require learning to execute a given program on the observed task specification. Furthermore, we propose the Program-guided Transformer (ProTo), which integrates both semantic and structural guidance of a program by leveraging cross-attention and masked self-attention to pass messages between the specification and routines in the program. ProTo executes a program in a learned latent space and enjoys stronger representation ability than previous neural-symbolic approaches. We demonstrate that ProTo significantly outperforms the previous state-of-the-art methods on GQA visual reasoning and 2D Minecraft policy learning datasets. Additionally, ProTo demonstrates better generalization to unseen, complex, and human-written programs.
How to Design Sample and Computationally Efficient VQA Models
Mar 22, 2021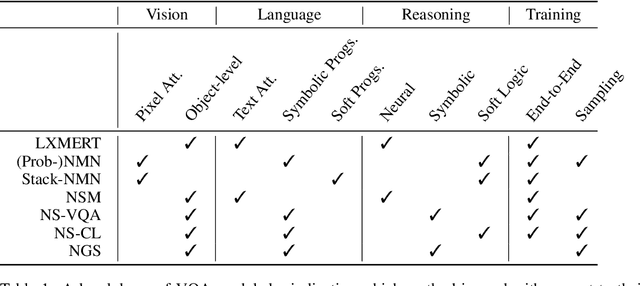
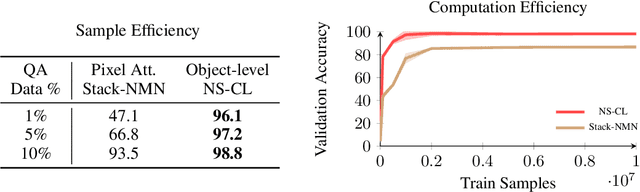
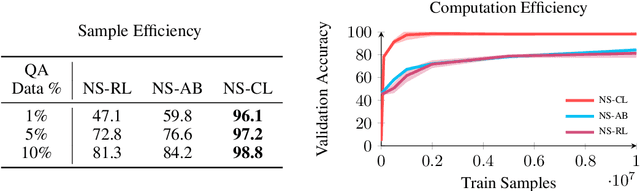
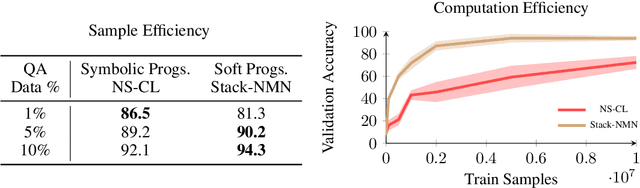
In multi-modal reasoning tasks, such as visual question answering (VQA), there have been many modeling and training paradigms tested. Previous models propose different methods for the vision and language tasks, but which ones perform the best while being sample and computationally efficient? Based on our experiments, we find that representing the text as probabilistic programs and images as object-level scene graphs best satisfy these desiderata. We extend existing models to leverage these soft programs and scene graphs to train on question answer pairs in an end-to-end manner. Empirical results demonstrate that this differentiable end-to-end program executor is able to maintain state-of-the-art accuracy while being sample and computationally efficient.