 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSE: Resolving Manifold Misalignment in Visual Tokenization via Topological Orthogonality
May 07, 2026Unified visual tokenization faces a fundamental trade-off between high-fidelity pixel reconstruction (spatial equivariance) and semantic abstraction (conceptual invariance). We attribute this conflict to Manifold Misalignment: naive joint optimization induces opposing gradients, creating a zero-sum game between reconstruction and perception. To address this, we propose MUSE, a framework based on Topological Orthogonality. By treating Structure as an orthogonal bridge, MUSE decouples optimization within Transformers: structural gradients refine attention topology, while semantic gradients update feature values. This turns destructive interference into Mutual Reinforcement. Experiments show that MUSE breaks the trade-off, achieving state-of-the-art generation quality (gFID 3.08) and surpassing its teacher InternViT-300M in linear probing (85.2\% vs. 82.5\%), demonstrating that structurally aligned reconstruction can enhance semantic perception. Code is available at https://github.com/PanqiYang1/MUSE.
LUMOS: Universal Semi-Supervised OCT Retinal Layer Segmentation with Hierarchical Reliable Mutual Learning
Apr 07, 2026Optical Coherence Tomography (OCT) layer segmentation faces challenges due to annotation scarcity and heterogeneous label granularities across datasets. While semi-supervised learning helps alleviate label scarcity, existing methods typically assume a fixed granularity, failing to fully exploit cross-granularity supervision. This paper presents LUMOS, a semi-supervised universal OCT retinal layer segmentation framework based on a Dual-Decoder Network with a Hierarchical Prompting Strategy (DDN-HPS) and Reliable Progressive Multi-granularity Learning (RPML). DDN-HPS combines a dual-branch architecture with a multi-granularity prompting strategy to effectively suppress pseudo-label noise propagation. Meanwhile, RPML introduces region-level reliability weighing and a progressive training approach that guides the model from easier to more difficult tasks, ensuring the reliable selection of cross-granularity consistency targets, thereby achieving stable cross-granularity alignment. Experiments on six OCT datasets demonstrate that LUMOS largely outperforms existing methods and exhibits exceptional cross-domain and cross-granularity generalization capability.
IDProxy: Cold-Start CTR Prediction for Ads and Recommendation at Xiaohongshu with Multimodal LLMs
Mar 02, 2026Click-through rate (CTR) models in advertising and recommendation systems rely heavily on item ID embeddings, which struggle in item cold-start settings. We present IDProxy, a solution that leverages multimodal large language models (MLLMs) to generate proxy embeddings from rich content signals, enabling effective CTR prediction for new items without usage data. These proxies are explicitly aligned with the existing ID embedding space and are optimized end-to-end under CTR objectives together with the ranking model, allowing seamless integration into existing large-scale ranking pipelines. Offline experiments and online A/B tests demonstrate the effectiveness of IDProxy, which has been successfully deployed in both Content Feed and Display Ads features of Xiaohongshu's Explore Feed, serving hundreds of millions of users daily.
Full end-to-end diagnostic workflow automation of 3D OCT via foundation model-driven AI for retinal diseases
Feb 03, 2026Optical coherence tomography (OCT) has revolutionized retinal disease diagnosis with its high-resolution and three-dimensional imaging nature, yet its full diagnostic automation in clinical practices remains constrained by multi-stage workflows and conventional single-slice single-task AI models. We present Full-process OCT-based Clinical Utility System (FOCUS), a foundation model-driven framework enabling end-to-end automation of 3D OCT retinal disease diagnosis. FOCUS sequentially performs image quality assessment with EfficientNetV2-S, followed by abnormality detection and multi-disease classification using a fine-tuned Vision Foundation Model. Crucially, FOCUS leverages a unified adaptive aggregation method to intelligently integrate 2D slices-level predictions into comprehensive 3D patient-level diagnosis. Trained and tested on 3,300 patients (40,672 slices), and externally validated on 1,345 patients (18,498 slices) across four different-tier centers and diverse OCT devices, FOCUS achieved high F1 scores for quality assessment (99.01%), abnormally detection (97.46%), and patient-level diagnosis (94.39%). Real-world validation across centers also showed stable performance (F1: 90.22%-95.24%). In human-machine comparisons, FOCUS matched expert performance in abnormality detection (F1: 95.47% vs 90.91%) and multi-disease diagnosis (F1: 93.49% vs 91.35%), while demonstrating better efficiency. FOCUS automates the image-to-diagnosis pipeline, representing a critical advance towards unmanned ophthalmology with a validated blueprint for autonomous screening to enhance population scale retinal care accessibility and efficiency.
CE-RM: A Pointwise Generative Reward Model Optimized via Two-Stage Rollout and Unified Criteria
Jan 28, 2026Automatic evaluation is crucial yet challenging for open-ended natural language generation, especially when rule-based metrics are infeasible. Compared with traditional methods, the recent LLM-as-a-Judge paradigms enable better and more flexible evaluation, and show promise as generative reward models for reinforcement learning. However, prior work has revealed a notable gap between their seemingly impressive benchmark performance and actual effectiveness in RL practice. We attribute this issue to some limitations in existing studies, including the dominance of pairwise evaluation and inadequate optimization of evaluation criteria. Therefore, we propose CE-RM-4B, a pointwise generative reward model trained with a dedicated two-stage rollout method, and adopting unified query-based criteria. Using only about 5.7K high-quality data curated from the open-source preference dataset, our CE-RM-4B achieves superior performance on diverse reward model benchmarks, especially in Best-of-N scenarios, and delivers more effective improvements in downstream RL practice.
CODE ACROSTIC: Robust Watermarking for Code Generation
Dec 14, 2025Watermarking large language models (LLMs) is vital for preventing their misuse, including the fabrication of fake news, plagiarism, and spam. It is especially important to watermark LLM-generated code, as it often contains intellectual property.However, we found that existing methods for watermarking LLM-generated code fail to address comment removal attack.In such cases, an attacker can simply remove the comments from the generated code without affecting its functionality, significantly reducing the effectiveness of current code-watermarking techniques.On the other hand, injecting a watermark into code is challenging because, as previous works have noted, most code represents a low-entropy scenario compared to natural language. Our approach to addressing this issue involves leveraging prior knowledge to distinguish between low-entropy and high-entropy parts of the code, as indicated by a Cue List of words.We then inject the watermark guided by this Cue List, achieving higher detectability and usability than existing methods.We evaluated our proposed method on HumanEvaland compared our method with three state-of-the-art code watermarking techniques. The results demonstrate the effectiveness of our approach.
SynthGuard: An Open Platform for Detecting AI-Generated Multimedia with Multimodal LLMs
Nov 16, 2025
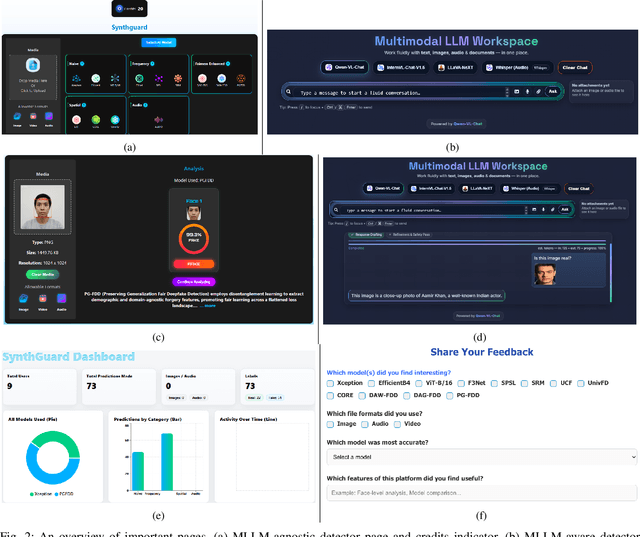
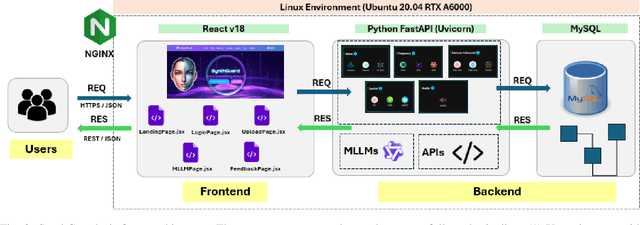
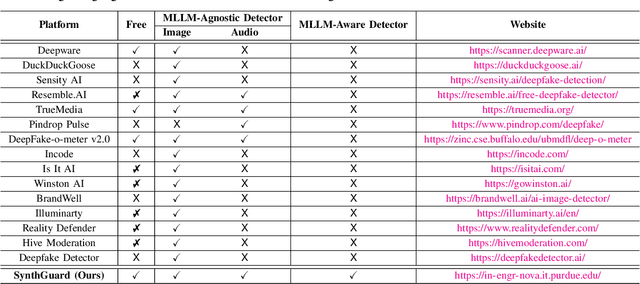
Artificial Intelligence (AI) has made it possible for anyone to create images, audio, and video with unprecedented ease, enriching education, communication, and creative expression. At the same time, the rapid rise of AI-generated media has introduced serious risks, including misinformation, identity misuse, and the erosion of public trust as synthetic content becomes increasingly indistinguishable from real media. Although deepfake detection has advanced, many existing tools remain closed-source, limited in modality, or lacking transparency and educational value, making it difficult for users to understand how detection decisions are made. To address these gaps, we introduce SynthGuard, an open, user-friendly platform for detecting and analyzing AI-generated multimedia using both traditional detectors and multimodal large language models (MLLMs). SynthGuard provides explainable inference, unified image and audio support, and an interactive interface designed to make forensic analysis accessible to researchers, educators, and the public. The SynthGuard platform is available at: https://in-engr-nova.it.purdue.edu/
HAD: HAllucination Detection Language Models Based on a Comprehensive Hallucination Taxonomy
Oct 22, 2025The increasing reliance on natural language generation (NLG) models, particularly large language models, has raised concerns about the reliability and accuracy of their outputs. A key challenge is hallucination, where models produce plausible but incorrect information. As a result, hallucination detection has become a critical task. In this work, we introduce a comprehensive hallucination taxonomy with 11 categories across various NLG tasks and propose the HAllucination Detection (HAD) models https://github.com/pku0xff/HAD, which integrate hallucination detection, span-level identification, and correction into a single inference process. Trained on an elaborate synthetic dataset of about 90K samples, our HAD models are versatile and can be applied to various NLG tasks. We also carefully annotate a test set for hallucination detection, called HADTest, which contains 2,248 samples. Evaluations on in-domain and out-of-domain test sets show that our HAD models generally outperform the existing baselines, achieving state-of-the-art results on HaluEval, FactCHD, and FaithBench, confirming their robustness and versatility.
AniMer+: Unified Pose and Shape Estimation Across Mammalia and Aves via Family-Aware Transformer
Aug 01, 2025In the era of foundation models, achieving a unified understanding of different dynamic objects through a single network has the potential to empower stronger spatial intelligence. Moreover, accurate estimation of animal pose and shape across diverse species is essential for quantitative analysis in biological research. However, this topic remains underexplored due to the limited network capacity of previous methods and the scarcity of comprehensive multi-species datasets. To address these limitations, we introduce AniMer+, an extended version of our scalable AniMer framework. In this paper, we focus on a unified approach for reconstructing mammals (mammalia) and birds (aves). A key innovation of AniMer+ is its high-capacity, family-aware Vision Transformer (ViT) incorporating a Mixture-of-Experts (MoE) design. Its architecture partitions network layers into taxa-specific components (for mammalia and aves) and taxa-shared components, enabling efficient learning of both distinct and common anatomical features within a single model. To overcome the critical shortage of 3D training data, especially for birds, we introduce a diffusion-based conditional image generation pipeline. This pipeline produces two large-scale synthetic datasets: CtrlAni3D for quadrupeds and CtrlAVES3D for birds. To note, CtrlAVES3D is the first large-scale, 3D-annotated dataset for birds, which is crucial for resolving single-view depth ambiguities. Trained on an aggregated collection of 41.3k mammalian and 12.4k avian images (combining real and synthetic data), our method demonstrates superior performance over existing approaches across a wide range of benchmarks, including the challenging out-of-domain Animal Kingdom dataset. Ablation studies confirm the effectiveness of both our novel network architecture and the generated synthetic datasets in enhancing real-world application performance.
LEDOM: An Open and Fundamental Reverse Language Model
Jul 02, 2025We introduce LEDOM, the first purely reverse language model, trained autoregressively on 435B tokens with 2B and 7B parameter variants, which processes sequences in reverse temporal order through previous token prediction. For the first time, we present the reverse language model as a potential foundational model across general tasks, accompanied by a set of intriguing examples and insights. Based on LEDOM, we further introduce a novel application: Reverse Reward, where LEDOM-guided reranking of forward language model outputs leads to substantial performance improvements on mathematical reasoning tasks. This approach leverages LEDOM's unique backward reasoning capability to refine generation quality through posterior evaluation. Our findings suggest that LEDOM exhibits unique characteristics with broad application potential. We will release all models, training code, and pre-training data to facilitate future research.