 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanoidVerse: A Versatile Humanoid for Vision-Language Guided Multi-Object Rearrangement
Aug 23, 2025We introduce HumanoidVerse, a novel framework for vision-language guided humanoid control that enables a single physically simulated robot to perform long-horizon, multi-object rearrangement tasks across diverse scenes. Unlike prior methods that operate in fixed settings with single-object interactions, our approach supports consecutive manipulation of multiple objects, guided only by natural language instructions and egocentric camera RGB observations. HumanoidVerse is trained via a multi-stage curriculum using a dual-teacher distillation pipeline, enabling fluid transitions between sub-tasks without requiring environment resets. To support this, we construct a large-scale dataset comprising 350 multi-object tasks spanning four room layouts. Extensive experiments in the Isaac Gym simulator demonstrate that our method significantly outperforms prior state-of-the-art in both task success rate and spatial precision, and generalizes well to unseen environments and instructions. Our work represents a key step toward robust, general-purpose humanoid agents capable of executing complex, sequential tasks under real-world sensory constraints. The video visualization results can be found on the project page: https://haozhuo-zhang.github.io/HumanoidVerse-project-page/.
$NavA^3$: Understanding Any Instruction, Navigating Anywhere, Finding Anything
Aug 06, 2025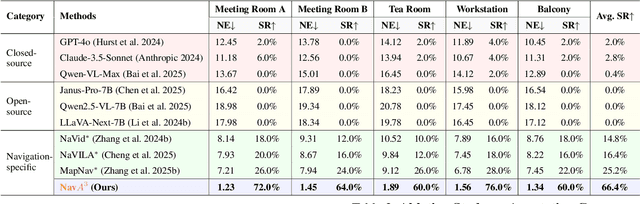
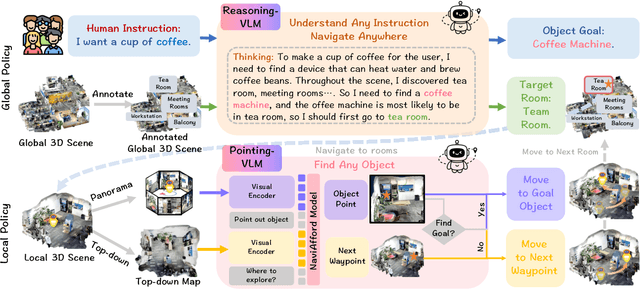
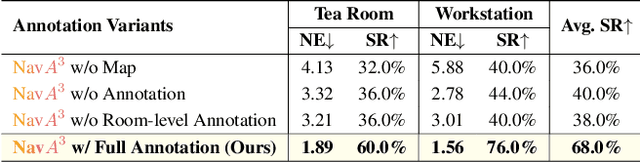
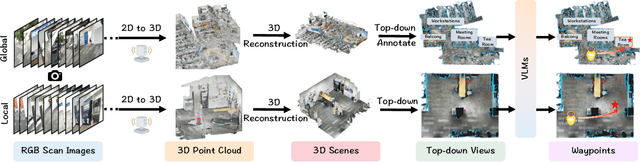
Embodied navigation is a fundamental capability of embodied intelligence, enabling robots to move and interact within physical environments. However, existing navigation tasks primarily focus on predefined object navigation or instruction following, which significantly differs from human needs in real-world scenarios involving complex, open-ended scenes. To bridge this gap, we introduce a challenging long-horizon navigation task that requires understanding high-level human instructions and performing spatial-aware object navigation in real-world environments. Existing embodied navigation methods struggle with such tasks due to their limitations in comprehending high-level human instructions and localizing objects with an open vocabulary. In this paper, we propose $NavA^3$, a hierarchical framework divided into two stages: global and local policies. In the global policy, we leverage the reasoning capabilities of Reasoning-VLM to parse high-level human instructions and integrate them with global 3D scene views. This allows us to reason and navigate to regions most likely to contain the goal object. In the local policy, we have collected a dataset of 1.0 million samples of spatial-aware object affordances to train the NaviAfford model (PointingVLM), which provides robust open-vocabulary object localization and spatial awareness for precise goal identification and navigation in complex environments. Extensive experiments demonstrate that $NavA^3$ achieves SOTA results in navigation performance and can successfully complete longhorizon navigation tasks across different robot embodiments in real-world settings, paving the way for universal embodied navigation. The dataset and code will be made available. Project website: https://NavigationA3.github.io/.
RoboBrain 2.0 Technical Report
Jul 02, 2025We introduce RoboBrain 2.0, our latest generation of embodied vision-language foundation models, designed to unify perception, reasoning, and planning for complex embodied tasks in physical environments. It comes in two variants: a lightweight 7B model and a full-scale 32B model, featuring a heterogeneous architecture with a vision encoder and a language model. Despite its compact size, RoboBrain 2.0 achieves strong performance across a wide spectrum of embodied reasoning tasks. On both spatial and temporal benchmarks, the 32B variant achieves leading results, surpassing prior open-source and proprietary models. In particular, it supports key real-world embodied AI capabilities, including spatial understanding (e.g., affordance prediction, spatial referring, trajectory forecasting) and temporal decision-making (e.g., closed-loop interaction, multi-agent long-horizon planning, and scene graph updating). This report details the model architecture, data construction, multi-stage training strategies, infrastructure and practical applications. We hope RoboBrain 2.0 advances embodied AI research and serves as a practical step toward building generalist embodied agents. The code, checkpoint and benchmark are available at https://superrobobrain.github.io.
AC-DiT: Adaptive Coordination Diffusion Transformer for Mobile Manipulation
Jul 02, 2025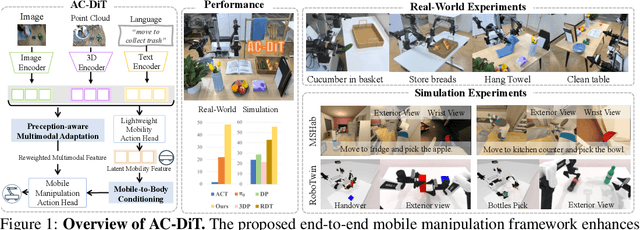
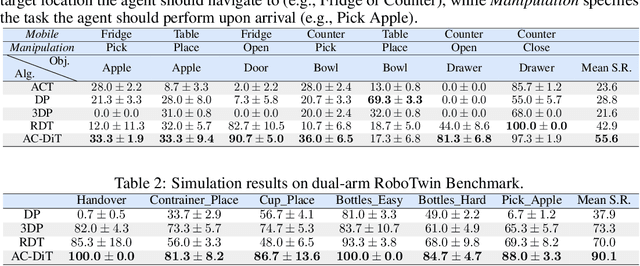
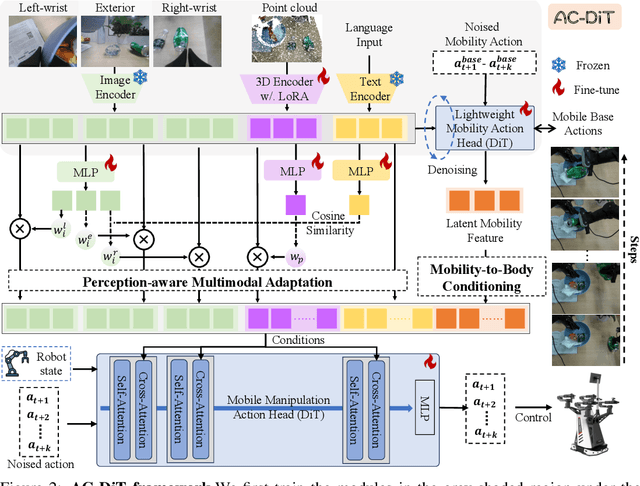

Recently, mobile manipulation has attracted increasing attention for enabling language-conditioned robotic control in household tasks. However, existing methods still face challenges in coordinating mobile base and manipulator, primarily due to two limitations. On the one hand, they fail to explicitly model the influence of the mobile base on manipulator control, which easily leads to error accumulation under high degrees of freedom. On the other hand, they treat the entire mobile manipulation process with the same visual observation modality (e.g., either all 2D or all 3D), overlooking the distinct multimodal perception requirements at different stages during mobile manipulation. To address this, we propose the Adaptive Coordination Diffusion Transformer (AC-DiT), which enhances mobile base and manipulator coordination for end-to-end mobile manipulation. First, since the motion of the mobile base directly influences the manipulator's actions, we introduce a mobility-to-body conditioning mechanism that guides the model to first extract base motion representations, which are then used as context prior for predicting whole-body actions. This enables whole-body control that accounts for the potential impact of the mobile base's motion. Second, to meet the perception requirements at different stages of mobile manipulation, we design a perception-aware multimodal conditioning strategy that dynamically adjusts the fusion weights between various 2D visual images and 3D point clouds, yielding visual features tailored to the current perceptual needs. This allows the model to, for example, adaptively rely more on 2D inputs when semantic information is crucial for action prediction, while placing greater emphasis on 3D geometric information when precise spatial understanding is required. We validate AC-DiT through extensive experiments on both simulated and real-world mobile manipulation tasks.
MinD: Unified Visual Imagination and Control via Hierarchical World Models
Jun 23, 2025



Video generation models (VGMs) offer a promising pathway for unified world modeling in robotics by integrating simulation, prediction, and manipulation. However, their practical application remains limited due to (1) slowgeneration speed, which limits real-time interaction, and (2) poor consistency between imagined videos and executable actions. To address these challenges, we propose Manipulate in Dream (MinD), a hierarchical diffusion-based world model framework that employs a dual-system design for vision-language manipulation. MinD executes VGM at low frequencies to extract video prediction features, while leveraging a high-frequency diffusion policy for real-time interaction. This architecture enables low-latency, closed-loop control in manipulation with coherent visual guidance. To better coordinate the two systems, we introduce a video-action diffusion matching module (DiffMatcher), with a novel co-training strategy that uses separate schedulers for each diffusion model. Specifically, we introduce a diffusion-forcing mechanism to DiffMatcher that aligns their intermediate representations during training, helping the fast action model better understand video-based predictions. Beyond manipulation, MinD also functions as a world simulator, reliably predicting task success or failure in latent space before execution. Trustworthy analysis further shows that VGMs can preemptively evaluate task feasibility and mitigate risks. Extensive experiments across multiple benchmarks demonstrate that MinD achieves state-of-the-art manipulation (63%+) in RL-Bench, advancing the frontier of unified world modeling in robotics.
Video-CoT: A Comprehensive Dataset for Spatiotemporal Understanding of Videos Based on Chain-of-Thought
Jun 12, 2025



Video content comprehension is essential for various applications, ranging from video analysis to interactive systems. Despite advancements in large-scale vision-language models (VLMs), these models often struggle to capture the nuanced, spatiotemporal details essential for thorough video analysis. To address this gap, we introduce Video-CoT, a groundbreaking dataset designed to enhance spatiotemporal understanding using Chain-of-Thought (CoT) methodologies. Video-CoT contains 192,000 fine-grained spa-tiotemporal question-answer pairs and 23,000 high-quality CoT-annotated samples, providing a solid foundation for evaluating spatiotemporal understanding in video comprehension. Additionally, we provide a comprehensive benchmark for assessing these tasks, with each task featuring 750 images and tailored evaluation metrics. Our extensive experiments reveal that current VLMs face significant challenges in achieving satisfactory performance, high-lighting the difficulties of effective spatiotemporal understanding. Overall, the Video-CoT dataset and benchmark open new avenues for research in multimedia understanding and support future innovations in intelligent systems requiring advanced video analysis capabilities. By making these resources publicly available, we aim to encourage further exploration in this critical area. Project website:https://video-cot.github.io/ .
Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs
Jun 12, 2025



In multimodal large language models (MLLMs), the length of input visual tokens is often significantly greater than that of their textual counterparts, leading to a high inference cost. Many works aim to address this issue by removing redundant visual tokens. However, current approaches either rely on attention-based pruning, which retains numerous duplicate tokens, or use similarity-based pruning, overlooking the instruction relevance, consequently causing suboptimal performance. In this paper, we go beyond attention or similarity by proposing a novel visual token pruning method named CDPruner, which maximizes the conditional diversity of retained tokens. We first define the conditional similarity between visual tokens conditioned on the instruction, and then reformulate the token pruning problem with determinantal point process (DPP) to maximize the conditional diversity of the selected subset. The proposed CDPruner is training-free and model-agnostic, allowing easy application to various MLLMs. Extensive experiments across diverse MLLMs show that CDPruner establishes new state-of-the-art on various vision-language benchmarks. By maximizing conditional diversity through DPP, the selected subset better represents the input images while closely adhering to user instructions, thereby preserving strong performance even with high reduction ratios. When applied to LLaVA, CDPruner reduces FLOPs by 95\% and CUDA latency by 78\%, while maintaining 94\% of the original accuracy. Our code is available at https://github.com/Theia-4869/CDPruner.
SpikePingpong: High-Frequency Spike Vision-based Robot Learning for Precise Striking in Table Tennis Game
Jun 07, 2025

Learning to control high-speed objects in the real world remains a challenging frontier in robotics. Table tennis serves as an ideal testbed for this problem, demanding both rapid interception of fast-moving balls and precise adjustment of their trajectories. This task presents two fundamental challenges: it requires a high-precision vision system capable of accurately predicting ball trajectories, and it necessitates intelligent strategic planning to ensure precise ball placement to target regions. The dynamic nature of table tennis, coupled with its real-time response requirements, makes it particularly well-suited for advancing robotic control capabilities in fast-paced, precision-critical domains. In this paper, we present SpikePingpong, a novel system that integrates spike-based vision with imitation learning for high-precision robotic table tennis. Our approach introduces two key attempts that directly address the aforementioned challenges: SONIC, a spike camera-based module that achieves millimeter-level precision in ball-racket contact prediction by compensating for real-world uncertainties such as air resistance and friction; and IMPACT, a strategic planning module that enables accurate ball placement to targeted table regions. The system harnesses a 20 kHz spike camera for high-temporal resolution ball tracking, combined with efficient neural network models for real-time trajectory correction and stroke planning. Experimental results demonstrate that SpikePingpong achieves a remarkable 91% success rate for 30 cm accuracy target area and 71% in the more challenging 20 cm accuracy task, surpassing previous state-of-the-art approaches by 38% and 37% respectively. These significant performance improvements enable the robust implementation of sophisticated tactical gameplay strategies, providing a new research perspective for robotic control in high-speed dynamic tasks.
RoboRefer: Towards Spatial Referring with Reasoning in Vision-Language Models for Robotics
Jun 04, 2025Spatial referring is a fundamental capability of embodied robots to interact with the 3D physical world. However, even with the powerful pretrained vision language models (VLMs), recent approaches are still not qualified to accurately understand the complex 3D scenes and dynamically reason about the instruction-indicated locations for interaction. To this end, we propose RoboRefer, a 3D-aware VLM that can first achieve precise spatial understanding by integrating a disentangled but dedicated depth encoder via supervised fine-tuning (SFT). Moreover, RoboRefer advances generalized multi-step spatial reasoning via reinforcement fine-tuning (RFT), with metric-sensitive process reward functions tailored for spatial referring tasks. To support SFT and RFT training, we introduce RefSpatial, a large-scale dataset of 20M QA pairs (2x prior), covering 31 spatial relations (vs. 15 prior) and supporting complex reasoning processes (up to 5 steps). In addition, we introduce RefSpatial-Bench, a challenging benchmark filling the gap in evaluating spatial referring with multi-step reasoning. Experiments show that SFT-trained RoboRefer achieves state-of-the-art spatial understanding, with an average success rate of 89.6%. RFT-trained RoboRefer further outperforms all other baselines by a large margin, even surpassing Gemini-2.5-Pro by 17.4% in average accuracy on RefSpatial-Bench. Notably, RoboRefer can be integrated with various control policies to execute long-horizon, dynamic tasks across diverse robots (e,g., UR5, G1 humanoid) in cluttered real-world scenes.
GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control
May 29, 2025Recent advancements in world models have revolutionized dynamic environment simulation, allowing systems to foresee future states and assess potential actions. In autonomous driving, these capabilities help vehicles anticipate the behavior of other road users, perform risk-aware planning, accelerate training in simulation, and adapt to novel scenarios, thereby enhancing safety and reliability. Current approaches exhibit deficiencies in maintaining robust 3D geometric consistency or accumulating artifacts during occlusion handling, both critical for reliable safety assessment in autonomous navigation tasks. To address this, we introduce GeoDrive, which explicitly integrates robust 3D geometry conditions into driving world models to enhance spatial understanding and action controllability. Specifically, we first extract a 3D representation from the input frame and then obtain its 2D rendering based on the user-specified ego-car trajectory. To enable dynamic modeling, we propose a dynamic editing module during training to enhance the renderings by editing the positions of the vehicles. Extensive experiments demonstrate that our method significantly outperforms existing models in both action accuracy and 3D spatial awareness, leading to more realistic, adaptable, and reliable scene modeling for safer autonomous driving. Additionally, our model can generalize to novel trajectories and offers interactive scene editing capabilities, such as object editing and object trajectory control.