 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHER: Human-like Reasoning and Reinforcement Learning for LLM Role-playing
Jan 29, 2026LLM role-playing, i.e., using LLMs to simulate specific personas, has emerged as a key capability in various applications, such as companionship, content creation, and digital games. While current models effectively capture character tones and knowledge, simulating the inner thoughts behind their behaviors remains a challenge. Towards cognitive simulation in LLM role-play, previous efforts mainly suffer from two deficiencies: data with high-quality reasoning traces, and reliable reward signals aligned with human preferences. In this paper, we propose HER, a unified framework for cognitive-level persona simulation. HER introduces dual-layer thinking, which distinguishes characters' first-person thinking from LLMs' third-person thinking. To bridge these gaps, we curate reasoning-augmented role-playing data via reverse engineering and construct human-aligned principles and reward models. Leveraging these resources, we train \method models based on Qwen3-32B via supervised and reinforcement learning. Extensive experiments validate the effectiveness of our approach. Notably, our models significantly outperform the Qwen3-32B baseline, achieving a 30.26 improvement on the CoSER benchmark and a 14.97 gain on the Minimax Role-Play Bench. Our datasets, principles, and models will be released to facilitate future research.
CLIP-Guided Unsupervised Semantic-Aware Exposure Correction
Jan 27, 2026Improper exposure often leads to severe loss of details, color distortion, and reduced contrast. Exposure correction still faces two critical challenges: (1) the ignorance of object-wise regional semantic information causes the color shift artifacts; (2) real-world exposure images generally have no ground-truth labels, and its labeling entails massive manual editing. To tackle the challenges, we propose a new unsupervised semantic-aware exposure correction network. It contains an adaptive semantic-aware fusion module, which effectively fuses the semantic information extracted from a pre-trained Fast Segment Anything Model into a shared image feature space. Then the fused features are used by our multi-scale residual spatial mamba group to restore the details and adjust the exposure. To avoid manual editing, we propose a pseudo-ground truth generator guided by CLIP, which is fine-tuned to automatically identify exposure situations and instruct the tailored corrections. Also, we leverage the rich priors from the FastSAM and CLIP to develop a semantic-prompt consistency loss to enforce semantic consistency and image-prompt alignment for unsupervised training. Comprehensive experimental results illustrate the effectiveness of our method in correcting real-world exposure images and outperforms state-of-the-art unsupervised methods both numerically and visually.
Multi-Modal LLM based Image Captioning in ICT: Bridging the Gap Between General and Industry Domain
Jan 14, 2026In the information and communications technology (ICT) industry, training a domain-specific large language model (LLM) or constructing a retrieval-augmented generation system requires a substantial amount of high-value domain knowledge. However, the knowledge is not only hidden in the textual modality but also in the image modality. Traditional methods can parse text from domain documents but dont have image captioning ability. Multi-modal LLM (MLLM) can understand images, but they do not have sufficient domain knowledge. To address the above issues, this paper proposes a multi-stage progressive training strategy to train a Domain-specific Image Captioning Model (DICModel) in ICT, and constructs a standard evaluation system to validate the performance of DICModel. Specifically, this work first synthesizes about 7K image-text pairs by combining the Mermaid tool and LLMs, which are used for the first-stage supervised-fine-tuning (SFT) of DICModel. Then, ICT-domain experts manually annotate about 2K image-text pairs for the second-stage SFT of DICModel. Finally, experts and LLMs jointly synthesize about 1.5K visual question answering data for the instruction-based SFT. Experimental results indicate that our DICModel with only 7B parameters performs better than other state-of-the-art models with 32B parameters. Compared to the SOTA models with 7B and 32B parameters, our DICModel increases the BLEU metric by approximately 56.8% and 20.8%, respectively. On the objective questions constructed by ICT domain experts, our DICModel outperforms Qwen2.5-VL 32B by 1% in terms of accuracy rate. In summary, this work can efficiently and accurately extract the logical text from images, which is expected to promote the development of multimodal models in the ICT domain.
EvoFSM: Controllable Self-Evolution for Deep Research with Finite State Machines
Jan 14, 2026While LLM-based agents have shown promise for deep research, most existing approaches rely on fixed workflows that struggle to adapt to real-world, open-ended queries. Recent work therefore explores self-evolution by allowing agents to rewrite their own code or prompts to improve problem-solving ability, but unconstrained optimization often triggers instability, hallucinations, and instruction drift. We propose EvoFSM, a structured self-evolving framework that achieves both adaptability and control by evolving an explicit Finite State Machine (FSM) instead of relying on free-form rewriting. EvoFSM decouples the optimization space into macroscopic Flow (state-transition logic) and microscopic Skill (state-specific behaviors), enabling targeted improvements under clear behavioral boundaries. Guided by a critic mechanism, EvoFSM refines the FSM through a small set of constrained operations, and further incorporates a self-evolving memory that distills successful trajectories as reusable priors and failure patterns as constraints for future queries. Extensive evaluations on five multi-hop QA benchmarks demonstrate the effectiveness of EvoFSM. In particular, EvoFSM reaches 58.0% accuracy on the DeepSearch benchmark. Additional results on interactive decision-making tasks further validate its generalization.
MemGovern: Enhancing Code Agents through Learning from Governed Human Experiences
Jan 13, 2026While autonomous software engineering (SWE) agents are reshaping programming paradigms, they currently suffer from a "closed-world" limitation: they attempt to fix bugs from scratch or solely using local context, ignoring the immense historical human experience available on platforms like GitHub. Accessing this open-world experience is hindered by the unstructured and fragmented nature of real-world issue-tracking data. In this paper, we introduce MemGovern, a framework designed to govern and transform raw GitHub data into actionable experiential memory for agents. MemGovern employs experience governance to convert human experience into agent-friendly experience cards and introduces an agentic experience search strategy that enables logic-driven retrieval of human expertise. By producing 135K governed experience cards, MemGovern achieves a significant performance boost, improving resolution rates on the SWE-bench Verified by 4.65%. As a plug-in approach, MemGovern provides a solution for agent-friendly memory infrastructure.
Watching, Reasoning, and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning
Jan 11, 2026In real-world video question answering scenarios, videos often provide only localized visual cues, while verifiable answers are distributed across the open web; models therefore need to jointly perform cross-frame clue extraction, iterative retrieval, and multi-hop reasoning-based verification. To bridge this gap, we construct the first video deep research benchmark, VideoDR. VideoDR centers on video-conditioned open-domain video question answering, requiring cross-frame visual anchor extraction, interactive web retrieval, and multi-hop reasoning over joint video-web evidence; through rigorous human annotation and quality control, we obtain high-quality video deep research samples spanning six semantic domains. We evaluate multiple closed-source and open-source multimodal large language models under both the Workflow and Agentic paradigms, and the results show that Agentic is not consistently superior to Workflow: its gains depend on a model's ability to maintain the initial video anchors over long retrieval chains. Further analysis indicates that goal drift and long-horizon consistency are the core bottlenecks. In sum, VideoDR provides a systematic benchmark for studying video agents in open-web settings and reveals the key challenges for next-generation video deep research agents.
EgoReAct: Egocentric Video-Driven 3D Human Reaction Generation
Dec 28, 2025Humans exhibit adaptive, context-sensitive responses to egocentric visual input. However, faithfully modeling such reactions from egocentric video remains challenging due to the dual requirements of strictly causal generation and precise 3D spatial alignment. To tackle this problem, we first construct the Human Reaction Dataset (HRD) to address data scarcity and misalignment by building a spatially aligned egocentric video-reaction dataset, as existing datasets (e.g., ViMo) suffer from significant spatial inconsistency between the egocentric video and reaction motion, e.g., dynamically moving motions are always paired with fixed-camera videos. Leveraging HRD, we present EgoReAct, the first autoregressive framework that generates 3D-aligned human reaction motions from egocentric video streams in real-time. We first compress the reaction motion into a compact yet expressive latent space via a Vector Quantised-Variational AutoEncoder and then train a Generative Pre-trained Transformer for reaction generation from the visual input. EgoReAct incorporates 3D dynamic features, i.e., metric depth, and head dynamics during the generation, which effectively enhance spatial grounding. Extensive experiments demonstrate that EgoReAct achieves remarkably higher realism, spatial consistency, and generation efficiency compared with prior methods, while maintaining strict causality during generation. We will release code, models, and data upon acceptance.
Depth Anything in $360^\circ$: Towards Scale Invariance in the Wild
Dec 28, 2025Panoramic depth estimation provides a comprehensive solution for capturing complete $360^\circ$ environmental structural information, offering significant benefits for robotics and AR/VR applications. However, while extensively studied in indoor settings, its zero-shot generalization to open-world domains lags far behind perspective images, which benefit from abundant training data. This disparity makes transferring capabilities from the perspective domain an attractive solution. To bridge this gap, we present Depth Anything in $360^\circ$ (DA360), a panoramic-adapted version of Depth Anything V2. Our key innovation involves learning a shift parameter from the ViT backbone, transforming the model's scale- and shift-invariant output into a scale-invariant estimate that directly yields well-formed 3D point clouds. This is complemented by integrating circular padding into the DPT decoder to eliminate seam artifacts, ensuring spatially coherent depth maps that respect spherical continuity. Evaluated on standard indoor benchmarks and our newly curated outdoor dataset, Metropolis, DA360 shows substantial gains over its base model, achieving over 50\% and 10\% relative depth error reduction on indoor and outdoor benchmarks, respectively. Furthermore, DA360 significantly outperforms robust panoramic depth estimation methods, achieving about 30\% relative error improvement compared to PanDA across all three test datasets and establishing new state-of-the-art performance for zero-shot panoramic depth estimation.
A Text-Image Fusion Method with Data Augmentation Capabilities for Referring Medical Image Segmentation
Oct 14, 2025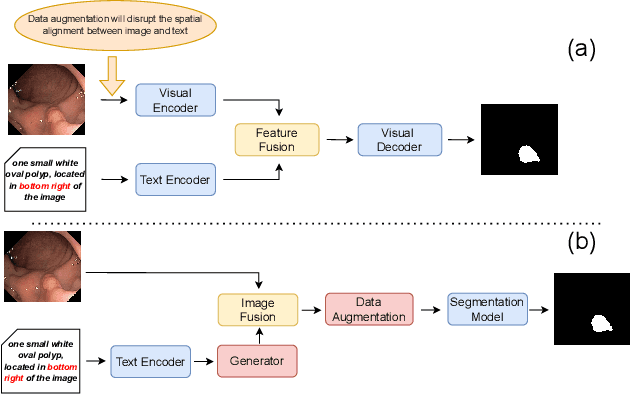
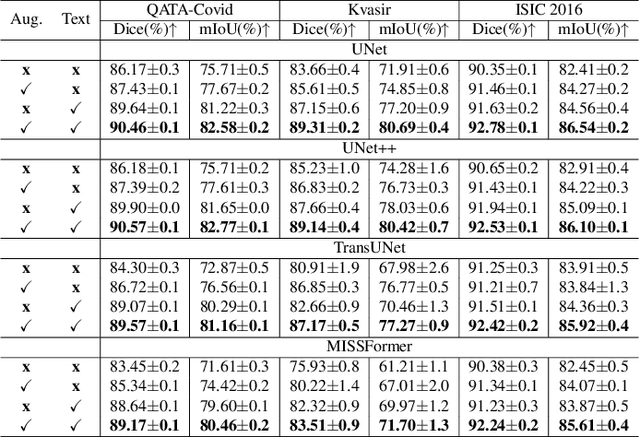
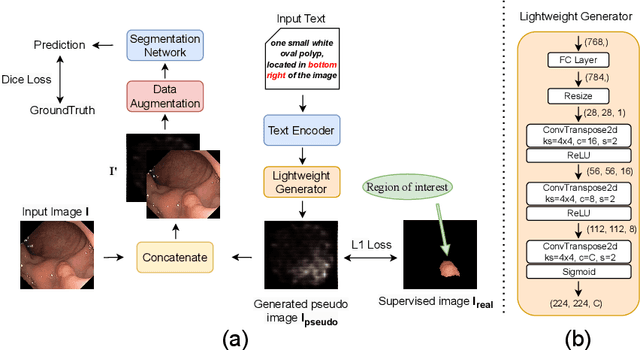

Deep learning relies heavily on data augmentation to mitigate limited data, especially in medical imaging. Recent multimodal learning integrates text and images for segmentation, known as referring or text-guided image segmentation. However, common augmentations like rotation and flipping disrupt spatial alignment between image and text, weakening performance. To address this, we propose an early fusion framework that combines text and visual features before augmentation, preserving spatial consistency. We also design a lightweight generator that projects text embeddings into visual space, bridging semantic gaps. Visualization of generated pseudo-images shows accurate region localization. Our method is evaluated on three medical imaging tasks and four segmentation frameworks, achieving state-of-the-art results. Code is publicly available on GitHub: https://github.com/11yxk/MedSeg_EarlyFusion.
PartSAM: A Scalable Promptable Part Segmentation Model Trained on Native 3D Data
Sep 26, 2025Segmenting 3D objects into parts is a long-standing challenge in computer vision. To overcome taxonomy constraints and generalize to unseen 3D objects, recent works turn to open-world part segmentation. These approaches typically transfer supervision from 2D foundation models, such as SAM, by lifting multi-view masks into 3D. However, this indirect paradigm fails to capture intrinsic geometry, leading to surface-only understanding, uncontrolled decomposition, and limited generalization. We present PartSAM, the first promptable part segmentation model trained natively on large-scale 3D data. Following the design philosophy of SAM, PartSAM employs an encoder-decoder architecture in which a triplane-based dual-branch encoder produces spatially structured tokens for scalable part-aware representation learning. To enable large-scale supervision, we further introduce a model-in-the-loop annotation pipeline that curates over five million 3D shape-part pairs from online assets, providing diverse and fine-grained labels. This combination of scalable architecture and diverse 3D data yields emergent open-world capabilities: with a single prompt, PartSAM achieves highly accurate part identification, and in a Segment-Every-Part mode, it automatically decomposes shapes into both surface and internal structures. Extensive experiments show that PartSAM outperforms state-of-the-art methods by large margins across multiple benchmarks, marking a decisive step toward foundation models for 3D part understanding. Our code and model will be released soon.