 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Summary Generation for Interpretable Multimodal Depression Detection
Apr 13, 2026Depression remains widely underdiagnosed and undertreated because stigma and subjective symptom ratings hinder reliable screening. To address this challenge, we propose a coarse-to-fine, multi-stage framework that leverages large language models (LLMs) for accurate and interpretable detection. The pipeline performs binary screening, five-class severity classification, and continuous regression. At each stage, an LLM produces progressively richer clinical summaries that guide a multimodal fusion module integrating text, audio, and video features, yielding predictions with transparent rationale. The system then consolidates all summaries into a concise, human-readable assessment report. Experiments on the E-DAIC and CMDC datasets show significant improvements over state-of-the-art baselines in both accuracy and interpretability.
SMES: Towards Scalable Multi-Task Recommendation via Expert Sparsity
Feb 10, 2026Industrial recommender systems typically rely on multi-task learning to estimate diverse user feedback signals and aggregate them for ranking. Recent advances in model scaling have shown promising gains in recommendation. However, naively increasing model capacity imposes prohibitive online inference costs and often yields diminishing returns for sparse tasks with skewed label distributions. This mismatch between uniform parameter scaling and heterogeneous task capacity demands poses a fundamental challenge for scalable multi-task recommendation. In this work, we investigate parameter sparsification as a principled scaling paradigm and identify two critical obstacles when applying sparse Mixture-of-Experts (MoE) to multi-task recommendation: exploded expert activation that undermines instance-level sparsity and expert load skew caused by independent task-wise routing. To address these challenges, we propose SMES, a scalable sparse MoE framework with progressive expert routing. SMES decomposes expert activation into a task-shared expert subset jointly selected across tasks and task-adaptive private experts, explicitly bounding per-instance expert execution while preserving task-specific capacity. In addition, SMES introduces a global multi-gate load-balancing regularizer that stabilizes training by regulating aggregated expert utilization across all tasks. SMES has been deployed in Kuaishou large-scale short-video services, supporting over 400 million daily active users. Extensive online experiments demonstrate stable improvements, with GAUC gain of 0.29% and a 0.31% uplift in user watch time.
Fun-Audio-Chat Technical Report
Dec 23, 2025Recent advancements in joint speech-text models show great potential for seamless voice interactions. However, existing models face critical challenges: temporal resolution mismatch between speech tokens (25Hz) and text tokens (~3Hz) dilutes semantic information, incurs high computational costs, and causes catastrophic forgetting of text LLM knowledge. We introduce Fun-Audio-Chat, a Large Audio Language Model addressing these limitations via two innovations from our previous work DrVoice. First, Dual-Resolution Speech Representations (DRSR): the Shared LLM processes audio at efficient 5Hz (via token grouping), while the Speech Refined Head generates high-quality tokens at 25Hz, balancing efficiency (~50% GPU reduction) and quality. Second, Core-Cocktail Training, a two-stage fine-tuning with intermediate merging that mitigates catastrophic forgetting. We then apply Multi-Task DPO Training to enhance robustness, audio understanding, instruction-following and voice empathy. This multi-stage post-training enables Fun-Audio-Chat to retain text LLM knowledge while gaining powerful audio understanding, reasoning, and generation. Unlike recent LALMs requiring large-scale audio-text pre-training, Fun-Audio-Chat leverages pre-trained models and extensive post-training. Fun-Audio-Chat 8B and MoE 30B-A3B achieve competitive performance on Speech-to-Text and Speech-to-Speech tasks, ranking top among similar-scale models on Spoken QA benchmarks. They also achieve competitive to superior performance on Audio Understanding, Speech Function Calling, Instruction-Following and Voice Empathy. We develop Fun-Audio-Chat-Duplex, a full-duplex variant with strong performance on Spoken QA and full-duplex interactions. We open-source Fun-Audio-Chat-8B with training and inference code, and provide an interactive demo.
A Text-Image Fusion Method with Data Augmentation Capabilities for Referring Medical Image Segmentation
Oct 14, 2025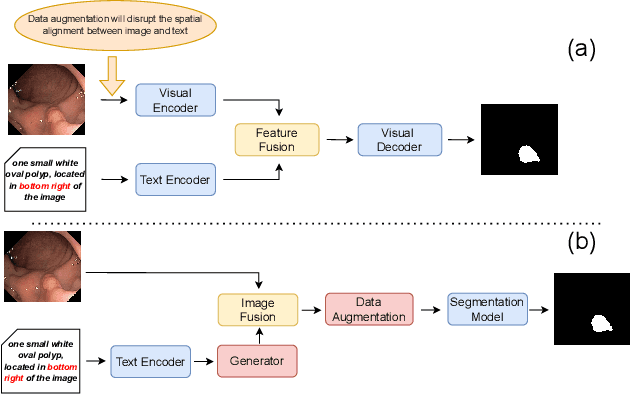
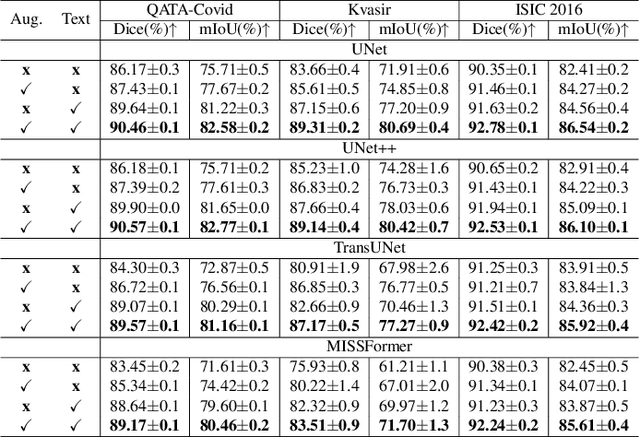
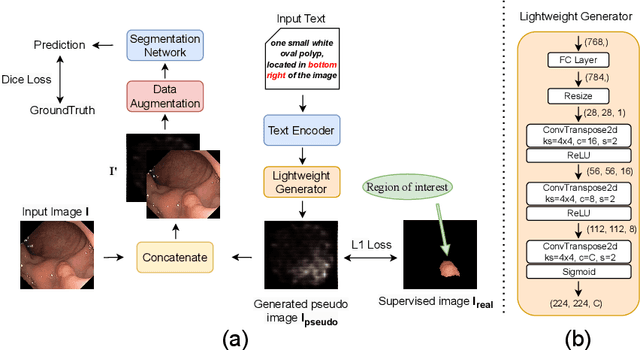

Deep learning relies heavily on data augmentation to mitigate limited data, especially in medical imaging. Recent multimodal learning integrates text and images for segmentation, known as referring or text-guided image segmentation. However, common augmentations like rotation and flipping disrupt spatial alignment between image and text, weakening performance. To address this, we propose an early fusion framework that combines text and visual features before augmentation, preserving spatial consistency. We also design a lightweight generator that projects text embeddings into visual space, bridging semantic gaps. Visualization of generated pseudo-images shows accurate region localization. Our method is evaluated on three medical imaging tasks and four segmentation frameworks, achieving state-of-the-art results. Code is publicly available on GitHub: https://github.com/11yxk/MedSeg_EarlyFusion.
OmniDRCA: Parallel Speech-Text Foundation Model via Dual-Resolution Speech Representations and Contrastive Alignment
Jun 11, 2025Recent studies on end-to-end speech generation with large language models (LLMs) have attracted significant community attention, with multiple works extending text-based LLMs to generate discrete speech tokens. Existing approaches primarily fall into two categories: (1) Methods that generate discrete speech tokens independently without incorporating them into the LLM's autoregressive process, resulting in text generation being unaware of concurrent speech synthesis. (2) Models that generate interleaved or parallel speech-text tokens through joint autoregressive modeling, enabling mutual modality awareness during generation. This paper presents OmniDRCA, a parallel speech-text foundation model based on joint autoregressive modeling, featuring dual-resolution speech representations and contrastive cross-modal alignment. Our approach processes speech and text representations in parallel while enhancing audio comprehension through contrastive alignment. Experimental results on Spoken Question Answering benchmarks demonstrate that OmniDRCA establishes new state-of-the-art (SOTA) performance among parallel joint speech-text modeling based foundation models, and achieves competitive performance compared to interleaved models. Additionally, we explore the potential of extending the framework to full-duplex conversational scenarios.
Enhancing Depression Detection with Chain-of-Thought Prompting: From Emotion to Reasoning Using Large Language Models
Feb 09, 2025Depression is one of the leading causes of disability worldwide, posing a severe burden on individuals, healthcare systems, and society at large. Recent advancements in Large Language Models (LLMs) have shown promise in addressing mental health challenges, including the detection of depression through text-based analysis. However, current LLM-based methods often struggle with nuanced symptom identification and lack a transparent, step-by-step reasoning process, making it difficult to accurately classify and explain mental health conditions. To address these challenges, we propose a Chain-of-Thought Prompting approach that enhances both the performance and interpretability of LLM-based depression detection. Our method breaks down the detection process into four stages: (1) sentiment analysis, (2) binary depression classification, (3) identification of underlying causes, and (4) assessment of severity. By guiding the model through these structured reasoning steps, we improve interpretability and reduce the risk of overlooking subtle clinical indicators. We validate our method on the E-DAIC dataset, where we test multiple state-of-the-art large language models. Experimental results indicate that our Chain-of-Thought Prompting technique yields superior performance in both classification accuracy and the granularity of diagnostic insights, compared to baseline approaches.
MinMo: A Multimodal Large Language Model for Seamless Voice Interaction
Jan 10, 2025



Recent advancements in large language models (LLMs) and multimodal speech-text models have laid the groundwork for seamless voice interactions, enabling real-time, natural, and human-like conversations. Previous models for voice interactions are categorized as native and aligned. Native models integrate speech and text processing in one framework but struggle with issues like differing sequence lengths and insufficient pre-training. Aligned models maintain text LLM capabilities but are often limited by small datasets and a narrow focus on speech tasks. In this work, we introduce MinMo, a Multimodal Large Language Model with approximately 8B parameters for seamless voice interaction. We address the main limitations of prior aligned multimodal models. We train MinMo through multiple stages of speech-to-text alignment, text-to-speech alignment, speech-to-speech alignment, and duplex interaction alignment, on 1.4 million hours of diverse speech data and a broad range of speech tasks. After the multi-stage training, MinMo achieves state-of-the-art performance across various benchmarks for voice comprehension and generation while maintaining the capabilities of text LLMs, and also facilitates full-duplex conversation, that is, simultaneous two-way communication between the user and the system. Moreover, we propose a novel and simple voice decoder that outperforms prior models in voice generation. The enhanced instruction-following capabilities of MinMo supports controlling speech generation based on user instructions, with various nuances including emotions, dialects, and speaking rates, and mimicking specific voices. For MinMo, the speech-to-text latency is approximately 100ms, full-duplex latency is approximately 600ms in theory and 800ms in practice. The MinMo project web page is https://funaudiollm.github.io/minmo, and the code and models will be released soon.
OmniFlatten: An End-to-end GPT Model for Seamless Voice Conversation
Oct 23, 2024



Full-duplex spoken dialogue systems significantly advance over traditional turn-based dialogue systems, as they allow simultaneous bidirectional communication, closely mirroring human-human interactions. However, achieving low latency and natural interactions in full-duplex dialogue systems remains a significant challenge, especially considering human conversation dynamics such as interruptions, backchannels, and overlapping speech. In this paper, we introduce a novel End-to-End GPT-based model OmniFlatten for full-duplex conversation, capable of effectively modeling the complex behaviors inherent to natural conversations with low latency. To achieve full-duplex communication capabilities, we propose a multi-stage post-training scheme that progressively adapts a text-based large language model (LLM) backbone into a speech-text dialogue LLM, capable of generating text and speech in real time, without modifying the architecture of the backbone LLM. The training process comprises three stages: modality alignment, half-duplex dialogue learning, and full-duplex dialogue learning. Throughout all training stages, we standardize the data using a flattening operation, which allows us to unify the training methods and the model architecture across different modalities and tasks. Our approach offers a straightforward modeling technique and a promising research direction for developing efficient and natural end-to-end full-duplex spoken dialogue systems. Audio samples of dialogues generated by OmniFlatten can be found at this web site (https://omniflatten.github.io/).
Recording for Eyes, Not Echoing to Ears: Contextualized Spoken-to-Written Conversion of ASR Transcripts
Aug 19, 2024



Automatic Speech Recognition (ASR) transcripts exhibit recognition errors and various spoken language phenomena such as disfluencies, ungrammatical sentences, and incomplete sentences, hence suffering from poor readability. To improve readability, we propose a Contextualized Spoken-to-Written conversion (CoS2W) task to address ASR and grammar errors and also transfer the informal text into the formal style with content preserved, utilizing contexts and auxiliary information. This task naturally matches the in-context learning capabilities of Large Language Models (LLMs). To facilitate comprehensive comparisons of various LLMs, we construct a document-level Spoken-to-Written conversion of ASR Transcripts Benchmark (SWAB) dataset. Using SWAB, we study the impact of different granularity levels on the CoS2W performance, and propose methods to exploit contexts and auxiliary information to enhance the outputs. Experimental results reveal that LLMs have the potential to excel in the CoS2W task, particularly in grammaticality and formality, our methods achieve effective understanding of contexts and auxiliary information by LLMs. We further investigate the effectiveness of using LLMs as evaluators and find that LLM evaluators show strong correlations with human evaluations on rankings of faithfulness and formality, which validates the reliability of LLM evaluators for the CoS2W task.
Multimodal Fusion and Coherence Modeling for Video Topic Segmentation
Aug 01, 2024



The video topic segmentation (VTS) task segments videos into intelligible, non-overlapping topics, facilitating efficient comprehension of video content and quick access to specific content. VTS is also critical to various downstream video understanding tasks. Traditional VTS methods using shallow features or unsupervised approaches struggle to accurately discern the nuances of topical transitions. Recently, supervised approaches have achieved superior performance on video action or scene segmentation over unsupervised approaches. In this work, we improve supervised VTS by thoroughly exploring multimodal fusion and multimodal coherence modeling. Specifically, (1) we enhance multimodal fusion by exploring different architectures using cross-attention and mixture of experts. (2) To generally strengthen multimodality alignment and fusion, we pre-train and fine-tune the model with multimodal contrastive learning. (3) We propose a new pre-training task tailored for the VTS task, and a novel fine-tuning task for enhancing multimodal coherence modeling for VTS. We evaluate the proposed approaches on educational videos, in the form of lectures, due to the vital role of topic segmentation of educational videos in boosting learning experiences. Additionally, we introduce a large-scale Chinese lecture video dataset to augment the existing English corpus, promoting further research in VTS. Experiments on both English and Chinese lecture datasets demonstrate that our model achieves superior VTS performance compared to competitive unsupervised and supervised baselines.