 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRenewable Lasso without Batch-Number Constraints: A Gradient-Enhanced Approach
Jun 10, 2026We study online estimation for high-dimensional generalized linear models with streaming data. First, for the non-distributed setting, we propose a gradient-enhanced surrogate loss that approximates the cumulative loss using only historical summaries, which modifies and improves upon the existing renewable estimation approach for the same model in the high-dimensional setting, and removes the batch-number constraint in previous studies. We then extend the method to distributed streaming data under the master-client architecture, where batches are partitioned across sites and only summaries (gradient vectors) are exchanged. Instead of directing applying the popular method of Jordan et al. (2019) to the surrogate quadratic loss, our adjusted approach does not require the clients to compute the full surrogate loss. We derive non-asymptotic error bounds under the high-dimensional scaling, without the stringent constraint on the number of batches in the previous studies. Simulation results under linear and logistic models, together with a real-data application, show improved accuracy over existing renewable estimators.
HEART-Bench: Do LLM Agents Exhibit Human-like Psychology?
May 28, 2026While LLM agents have demonstrated remarkable task-oriented abilities such as planning, reasoning, and action, few works have treated them as complete human personalities where emotional dimensions hold equal importance. In this paper, we introduce a novel benchmark to systematically assess whether LLM agents can simulate coherent, human-like psychology. Specifically, our benchmark constructs 11 diverse human characters grounded in orthogonal Big Five personality traits, with each profile deeply integrated with 1,000 structured autobiographical-style episodic memories distributed across theory-grounded developmental life stages. To rigorously evaluate the psychological manifestations of LLMs, we designed a curated suite of 64 decision-making scenarios, guided by the DIAMONDS taxonomy, a psychological framework that characterizes situations along eight dimensions: Duty, Intellect, Adversity, Mating, pOsitivity, Negativity, Deception, and Sociality. By subjecting agents to varying scenarios, the benchmark evaluates whether they can consolidate their innate personality traits and autobiographical memories to make behavioral decisions that are consistent with their specific psychological profiles. After systematic human validation and filtering, we obtained a benchmark consisting of 673 multiple-choice questions (MCQs). We believe this benchmark provides a principled and scalable testbed for studying human-like emotions, personality consistency, and value-consistent behavioural decision-making in LLM-based agents.
SWE-Pruner: Self-Adaptive Context Pruning for Coding Agents
Jan 23, 2026LLM agents have demonstrated remarkable capabilities in software development, but their performance is hampered by long interaction contexts, which incur high API costs and latency. While various context compression approaches such as LongLLMLingua have emerged to tackle this challenge, they typically rely on fixed metrics such as PPL, ignoring the task-specific nature of code understanding. As a result, they frequently disrupt syntactic and logical structure and fail to retain critical implementation details. In this paper, we propose SWE-Pruner, a self-adaptive context pruning framework tailored for coding agents. Drawing inspiration from how human programmers "selectively skim" source code during development and debugging, SWE-Pruner performs task-aware adaptive pruning for long contexts. Given the current task, the agent formulates an explicit goal (e.g., "focus on error handling") as a hint to guide the pruning targets. A lightweight neural skimmer (0.6B parameters) is trained to dynamically select relevant lines from the surrounding context given the goal. Evaluations across four benchmarks and multiple models validate SWE-Pruner's effectiveness in various scenarios, achieving 23-54% token reduction on agent tasks like SWE-Bench Verified and up to 14.84x compression on single-turn tasks like LongCodeQA with minimal performance impact.
MemGovern: Enhancing Code Agents through Learning from Governed Human Experiences
Jan 13, 2026While autonomous software engineering (SWE) agents are reshaping programming paradigms, they currently suffer from a "closed-world" limitation: they attempt to fix bugs from scratch or solely using local context, ignoring the immense historical human experience available on platforms like GitHub. Accessing this open-world experience is hindered by the unstructured and fragmented nature of real-world issue-tracking data. In this paper, we introduce MemGovern, a framework designed to govern and transform raw GitHub data into actionable experiential memory for agents. MemGovern employs experience governance to convert human experience into agent-friendly experience cards and introduces an agentic experience search strategy that enables logic-driven retrieval of human expertise. By producing 135K governed experience cards, MemGovern achieves a significant performance boost, improving resolution rates on the SWE-bench Verified by 4.65%. As a plug-in approach, MemGovern provides a solution for agent-friendly memory infrastructure.
Watching, Reasoning, and Searching: A Video Deep Research Benchmark on Open Web for Agentic Video Reasoning
Jan 11, 2026In real-world video question answering scenarios, videos often provide only localized visual cues, while verifiable answers are distributed across the open web; models therefore need to jointly perform cross-frame clue extraction, iterative retrieval, and multi-hop reasoning-based verification. To bridge this gap, we construct the first video deep research benchmark, VideoDR. VideoDR centers on video-conditioned open-domain video question answering, requiring cross-frame visual anchor extraction, interactive web retrieval, and multi-hop reasoning over joint video-web evidence; through rigorous human annotation and quality control, we obtain high-quality video deep research samples spanning six semantic domains. We evaluate multiple closed-source and open-source multimodal large language models under both the Workflow and Agentic paradigms, and the results show that Agentic is not consistently superior to Workflow: its gains depend on a model's ability to maintain the initial video anchors over long retrieval chains. Further analysis indicates that goal drift and long-horizon consistency are the core bottlenecks. In sum, VideoDR provides a systematic benchmark for studying video agents in open-web settings and reveals the key challenges for next-generation video deep research agents.
Online Deep Learning from Doubly-Streaming Data
Apr 27, 2022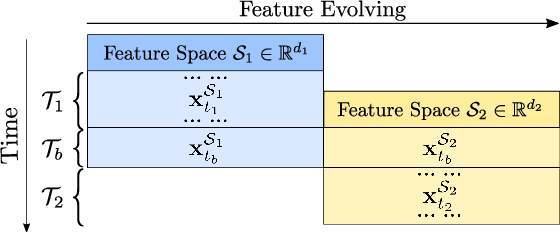
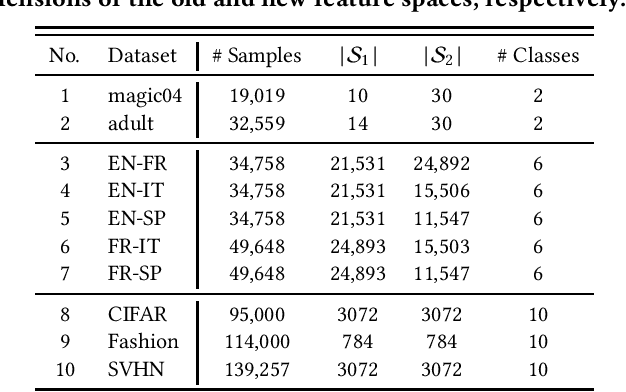
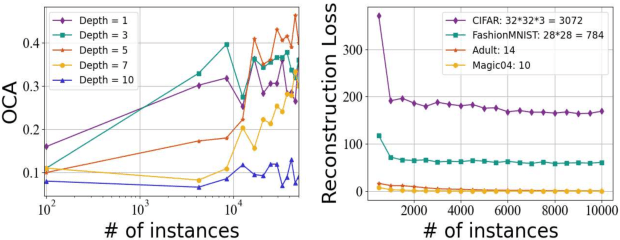
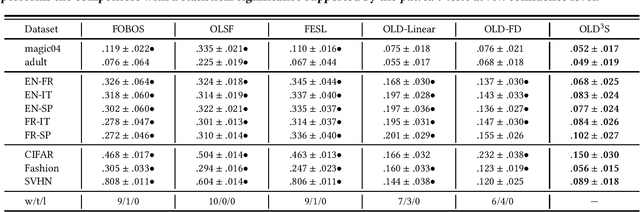
This paper investigates a new online learning problem with doubly-streaming data, where the data streams are described by feature spaces that constantly evolve, with new features emerging and old features fading away. The challenges of this problem are two folds: 1) Data samples ceaselessly flowing in may carry shifted patterns over time, requiring learners to update hence adapt on-the-fly. 2) Newly emerging features are described by very few samples, resulting in weak learners that tend to make error predictions. A plausible idea to overcome the challenges is to establish relationship between the pre-and-post evolving feature spaces, so that an online learner can leverage the knowledge learned from the old features to better the learning performance on the new features. Unfortunately, this idea does not scale up to high-dimensional media streams with complex feature interplay, which suffers an tradeoff between onlineness (biasing shallow learners) and expressiveness(requiring deep learners). Motivated by this, we propose a novel OLD^3S paradigm, where a shared latent subspace is discovered to summarize information from the old and new feature spaces, building intermediate feature mapping relationship. A key trait of OLD^3S is to treat the model capacity as a learnable semantics, yields optimal model depth and parameters jointly, in accordance with the complexity and non-linearity of the input data streams in an online fashion. Both theoretical analyses and empirical studies substantiate the viability and effectiveness of our proposal.
A debiased distributed estimation for sparse partially linear models in diverging dimensions
Aug 18, 2017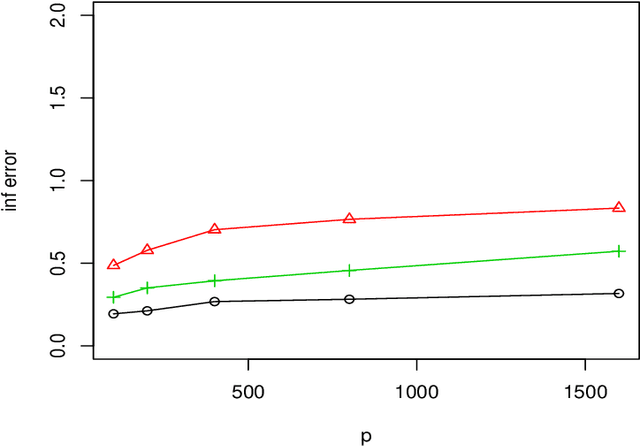
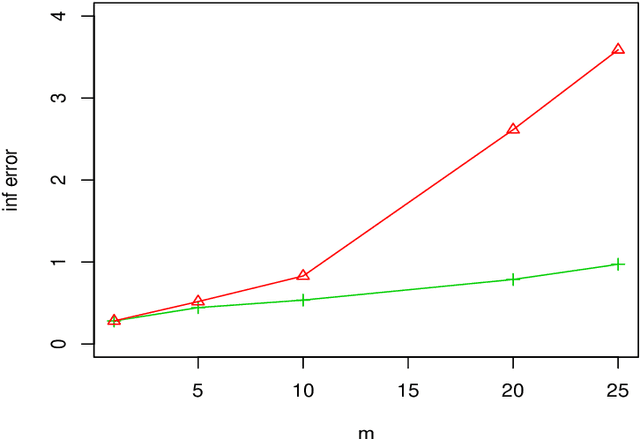
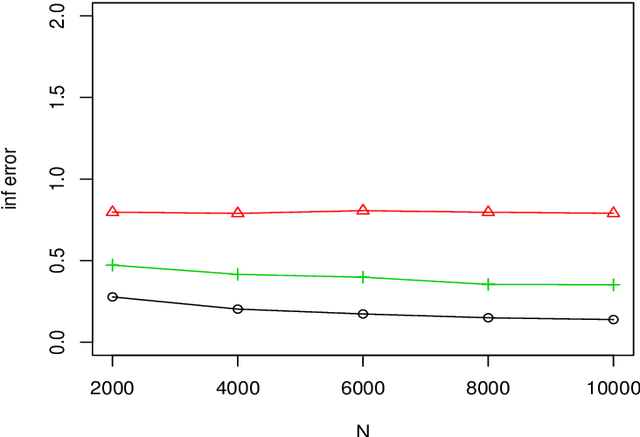
We consider a distributed estimation of the double-penalized least squares approach for high dimensional partial linear models, where the sample with a total of $N$ data points is randomly distributed among $m$ machines and the parameters of interest are calculated by merging their $m$ individual estimators. This paper primarily focuses on the investigation of the high dimensional linear components in partial linear models, which is often of more interest. We propose a new debiased averaging estimator of parametric coefficients on the basis of each individual estimator, and establish new non-asymptotic oracle results in high dimensional and distributed settings, provided that $m\leq \sqrt{N/\log p}$ and other mild conditions are satisfied, where $p$ is the linear coefficient dimension. We also provide an experimental evaluation of the proposed method, indicating the numerical effectiveness on simulated data. Even under the classical non-distributed setting, we give the optimal rates of the parametric estimator with a looser tuning parameter limitation, which is required for our error analysis.
Total Variation, Adaptive Total Variation and Nonconvex Smoothly Clipped Absolute Deviation Penalty for Denoising Blocky Images
Jun 02, 2009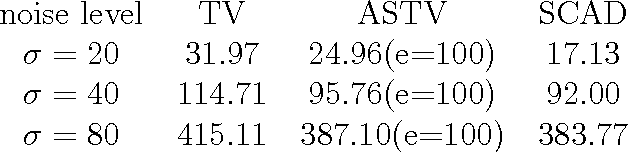
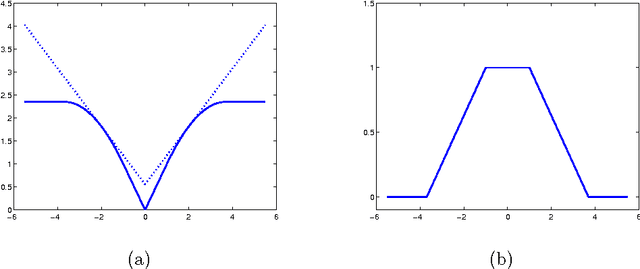


The total variation-based image denoising model has been generalized and extended in numerous ways, improving its performance in different contexts. We propose a new penalty function motivated by the recent progress in the statistical literature on high-dimensional variable selection. Using a particular instantiation of the majorization-minimization algorithm, the optimization problem can be efficiently solved and the computational procedure realized is similar to the spatially adaptive total variation model. Our two-pixel image model shows theoretically that the new penalty function solves the bias problem inherent in the total variation model. The superior performance of the new penalty is demonstrated through several experiments. Our investigation is limited to "blocky" images which have small total variation.
Bayesian Nonlinear Principal Component Analysis Using Random Fields
Feb 09, 2008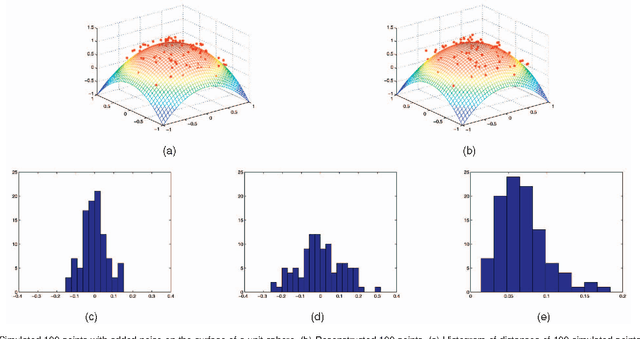
We propose a novel model for nonlinear dimension reduction motivated by the probabilistic formulation of principal component analysis. Nonlinearity is achieved by specifying different transformation matrices at different locations of the latent space and smoothing the transformation using a Markov random field type prior. The computation is made feasible by the recent advances in sampling from von Mises-Fisher distributions.
Variational local structure estimation for image super-resolution
Sep 12, 2007


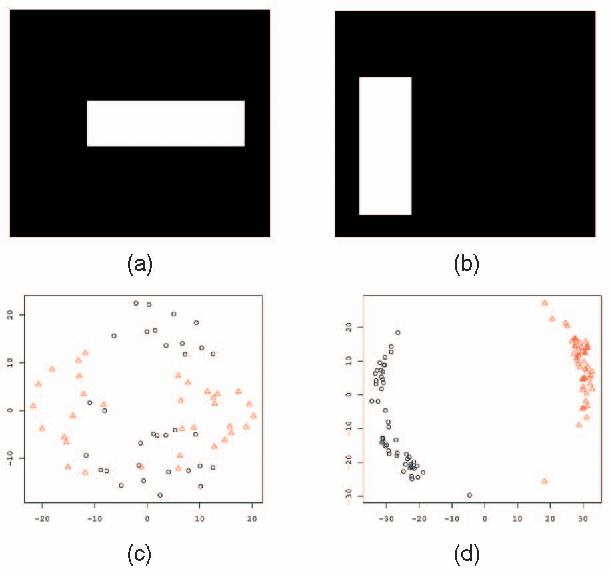
Super-resolution is an important but difficult problem in image/video processing. If a video sequence or some training set other than the given low-resolution image is available, this kind of extra information can greatly aid in the reconstruction of the high-resolution image. The problem is substantially more difficult with only a single low-resolution image on hand. The image reconstruction methods designed primarily for denoising is insufficient for super-resolution problem in the sense that it tends to oversmooth images with essentially no noise. We propose a new adaptive linear interpolation method based on variational method and inspired by local linear embedding (LLE). The experimental result shows that our method avoids the problem of oversmoothing and preserves image structures well.