 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Causal Video Reasoning via Multi-Objective Alignment
Apr 06, 2026Human understanding of video dynamics is typically grounded in a structured mental representation of entities, actions, and temporal relations, rather than relying solely on immediate deductive reasoning. In contrast, existing Video-LLMs largely depend on unstructured video reasoning, where critical visual evidence is embedded in verbose textual descriptions and temporal causality is often weakly modeled. This leads to inefficient processes and fragile causal inference. To bridge this cognitive gap, we propose constructing a compact representation of salient events and their causal relationships, which we name Structured Event Facts, prior to the reasoning stage. This structured prior serves as an explicit constraint to promote concise and causally grounded reasoning, while also making intermediate evidence easier to verify. To effectively train models on such structured facts, we introduce CausalFact-60K and a four-stage training pipeline comprising facts alignment, format warm-start, thinking warm-start, and reinforcement learning-based post-training. During RL stage, we find that this framework introduces competing objectives, as structural completeness and causal fidelity must be balanced against reasoning length, making it difficult to optimize. We address this challenge by formulating the optimization as a Multi-Objective Reinforcement Learning (MORL) problem and explicitly optimizing toward the Pareto-Frontier to balance these trade-offs. As a result, we introduce Factum-4B, which yields more reliable reasoning and delivers stronger performance on challenging video understanding tasks requiring fine-grained temporal inference.
Controllable Complex Human Motion Video Generation via Text-to-Skeleton Cascades
Mar 09, 2026Generating videos of complex human motions such as flips, cartwheels, and martial arts remains challenging for current video diffusion models. Text-only conditioning is temporally ambiguous for fine-grained motion control, while explicit pose-based controls, though effective, require users to provide complete skeleton sequences that are costly to produce for long and dynamic actions. We propose a two-stage cascaded framework that addresses both limitations. First, an autoregressive text-to-skeleton model generates 2D pose sequences from natural language descriptions by predicting each joint conditioned on previously generated poses. This design captures long-range temporal dependencies and inter-joint coordination required for complex motions. Second, a pose-conditioned video diffusion model synthesizes videos from a reference image and the generated skeleton sequence. It employs DINO-ALF (Adaptive Layer Fusion), a multi-level reference encoder that preserves appearance and clothing details under large pose changes and self-occlusions. To address the lack of publicly available datasets for complex human motion video generation, we introduce a Blender-based synthetic dataset containing 2,000 videos with diverse characters performing acrobatic and stunt-like motions. The dataset provides full control over appearance, motion, and environment. It fills an important gap because existing benchmarks significantly under-represent acrobatic motions while web-collected datasets raise copyright and privacy concerns. Experiments on our synthetic dataset and the Motion-X Fitness benchmark show that our text-to-skeleton model outperforms prior methods on FID, R-precision, and motion diversity. Our pose-to-video model also achieves the best results among all compared methods on VBench metrics for temporal consistency, motion smoothness, and subject preservation.
EvoFSM: Controllable Self-Evolution for Deep Research with Finite State Machines
Jan 14, 2026While LLM-based agents have shown promise for deep research, most existing approaches rely on fixed workflows that struggle to adapt to real-world, open-ended queries. Recent work therefore explores self-evolution by allowing agents to rewrite their own code or prompts to improve problem-solving ability, but unconstrained optimization often triggers instability, hallucinations, and instruction drift. We propose EvoFSM, a structured self-evolving framework that achieves both adaptability and control by evolving an explicit Finite State Machine (FSM) instead of relying on free-form rewriting. EvoFSM decouples the optimization space into macroscopic Flow (state-transition logic) and microscopic Skill (state-specific behaviors), enabling targeted improvements under clear behavioral boundaries. Guided by a critic mechanism, EvoFSM refines the FSM through a small set of constrained operations, and further incorporates a self-evolving memory that distills successful trajectories as reusable priors and failure patterns as constraints for future queries. Extensive evaluations on five multi-hop QA benchmarks demonstrate the effectiveness of EvoFSM. In particular, EvoFSM reaches 58.0% accuracy on the DeepSearch benchmark. Additional results on interactive decision-making tasks further validate its generalization.
LatentMove: Towards Complex Human Movement Video Generation
May 28, 2025Image-to-video (I2V) generation seeks to produce realistic motion sequences from a single reference image. Although recent methods exhibit strong temporal consistency, they often struggle when dealing with complex, non-repetitive human movements, leading to unnatural deformations. To tackle this issue, we present LatentMove, a DiT-based framework specifically tailored for highly dynamic human animation. Our architecture incorporates a conditional control branch and learnable face/body tokens to preserve consistency as well as fine-grained details across frames. We introduce Complex-Human-Videos (CHV), a dataset featuring diverse, challenging human motions designed to benchmark the robustness of I2V systems. We also introduce two metrics to assess the flow and silhouette consistency of generated videos with their ground truth. Experimental results indicate that LatentMove substantially improves human animation quality--particularly when handling rapid, intricate movements--thereby pushing the boundaries of I2V generation. The code, the CHV dataset, and the evaluation metrics will be available at https://github.com/ --.
Watch and Listen: Understanding Audio-Visual-Speech Moments with Multimodal LLM
May 23, 2025Humans naturally understand moments in a video by integrating visual and auditory cues. For example, localizing a scene in the video like "A scientist passionately speaks on wildlife conservation as dramatic orchestral music plays, with the audience nodding and applauding" requires simultaneous processing of visual, audio, and speech signals. However, existing models often struggle to effectively fuse and interpret audio information, limiting their capacity for comprehensive video temporal understanding. To address this, we present TriSense, a triple-modality large language model designed for holistic video temporal understanding through the integration of visual, audio, and speech modalities. Central to TriSense is a Query-Based Connector that adaptively reweights modality contributions based on the input query, enabling robust performance under modality dropout and allowing flexible combinations of available inputs. To support TriSense's multimodal capabilities, we introduce TriSense-2M, a high-quality dataset of over 2 million curated samples generated via an automated pipeline powered by fine-tuned LLMs. TriSense-2M includes long-form videos and diverse modality combinations, facilitating broad generalization. Extensive experiments across multiple benchmarks demonstrate the effectiveness of TriSense and its potential to advance multimodal video analysis. Code and dataset will be publicly released.
Layer-Wise Feature Metric of Semantic-Pixel Matching for Few-Shot Learning
Nov 10, 2024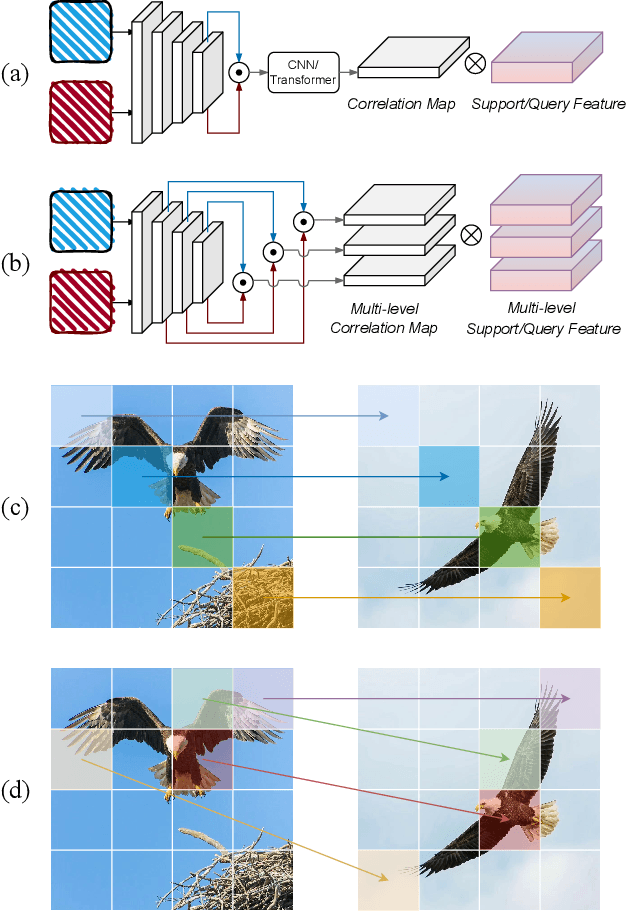
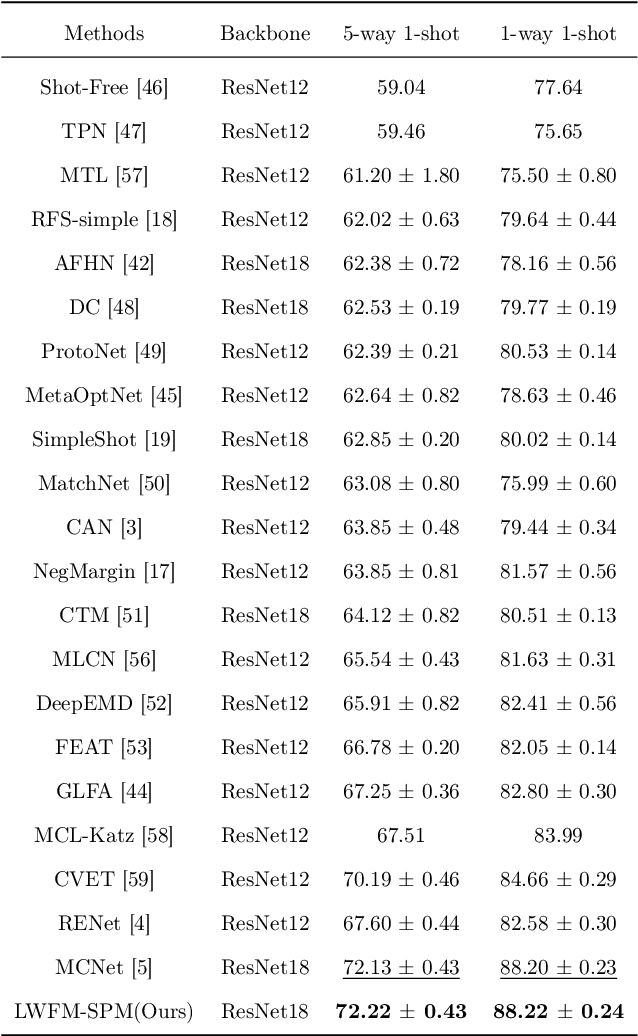
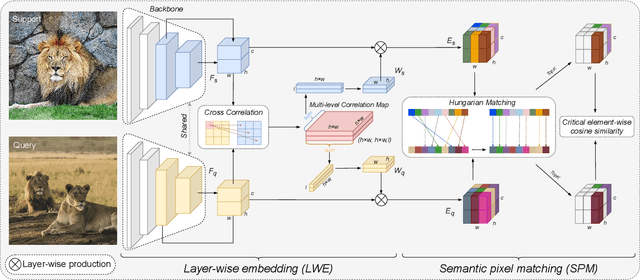
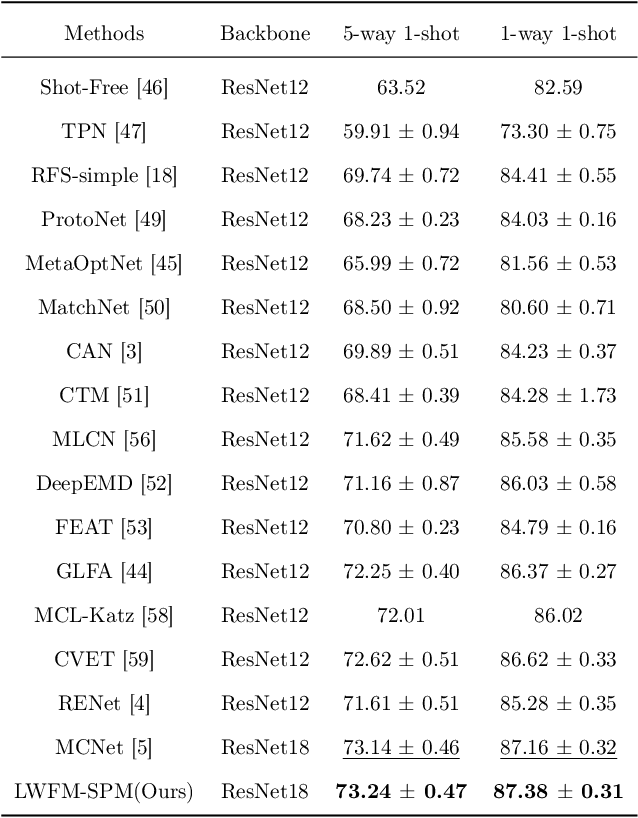
In Few-Shot Learning (FSL), traditional metric-based approaches often rely on global metrics to compute similarity. However, in natural scenes, the spatial arrangement of key instances is often inconsistent across images. This spatial misalignment can result in mismatched semantic pixels, leading to inaccurate similarity measurements. To address this issue, we propose a novel method called the Layer-Wise Features Metric of Semantic-Pixel Matching (LWFM-SPM) to make finer comparisons. Our method enhances model performance through two key modules: (1) the Layer-Wise Embedding (LWE) Module, which refines the cross-correlation of image pairs to generate well-focused feature maps for each layer; (2)the Semantic-Pixel Matching (SPM) Module, which aligns critical pixels based on semantic embeddings using an assignment algorithm. We conducted extensive experiments to evaluate our method on four widely used few-shot classification benchmarks: miniImageNet, tieredImageNet, CUB-200-2011, and CIFAR-FS. The results indicate that LWFM-SPM achieves competitive performance across these benchmarks. Our code will be publicly available on https://github.com/Halo2Tang/Code-for-LWFM-SPM.
Faster Image2Video Generation: A Closer Look at CLIP Image Embedding's Impact on Spatio-Temporal Cross-Attentions
Jul 27, 2024



This paper investigates the role of CLIP image embeddings within the Stable Video Diffusion (SVD) framework, focusing on their impact on video generation quality and computational efficiency. Our findings indicate that CLIP embeddings, while crucial for aesthetic quality, do not significantly contribute towards the subject and background consistency of video outputs. Moreover, the computationally expensive cross-attention mechanism can be effectively replaced by a simpler linear layer. This layer is computed only once at the first diffusion inference step, and its output is then cached and reused throughout the inference process, thereby enhancing efficiency while maintaining high-quality outputs. Building on these insights, we introduce the VCUT, a training-free approach optimized for efficiency within the SVD architecture. VCUT eliminates temporal cross-attention and replaces spatial cross-attention with a one-time computed linear layer, significantly reducing computational load. The implementation of VCUT leads to a reduction of up to 322T Multiple-Accumulate Operations (MACs) per video and a decrease in model parameters by up to 50M, achieving a 20% reduction in latency compared to the baseline. Our approach demonstrates that conditioning during the Semantic Binding stage is sufficient, eliminating the need for continuous computation across all inference steps and setting a new standard for efficient video generation.
QEAN: Quaternion-Enhanced Attention Network for Visual Dance Generation
Mar 18, 2024The study of music-generated dance is a novel and challenging Image generation task. It aims to input a piece of music and seed motions, then generate natural dance movements for the subsequent music. Transformer-based methods face challenges in time series prediction tasks related to human movements and music due to their struggle in capturing the nonlinear relationship and temporal aspects. This can lead to issues like joint deformation, role deviation, floating, and inconsistencies in dance movements generated in response to the music. In this paper, we propose a Quaternion-Enhanced Attention Network (QEAN) for visual dance synthesis from a quaternion perspective, which consists of a Spin Position Embedding (SPE) module and a Quaternion Rotary Attention (QRA) module. First, SPE embeds position information into self-attention in a rotational manner, leading to better learning of features of movement sequences and audio sequences, and improved understanding of the connection between music and dance. Second, QRA represents and fuses 3D motion features and audio features in the form of a series of quaternions, enabling the model to better learn the temporal coordination of music and dance under the complex temporal cycle conditions of dance generation. Finally, we conducted experiments on the dataset AIST++, and the results show that our approach achieves better and more robust performance in generating accurate, high-quality dance movements. Our source code and dataset can be available from https://github.com/MarasyZZ/QEAN and https://google.github.io/aistplusplus_dataset respectively.
CLIP Guided Image-perceptive Prompt Learning for Image Enhancement
Nov 07, 2023



Image enhancement is a significant research area in the fields of computer vision and image processing. In recent years, many learning-based methods for image enhancement have been developed, where the Look-up-table (LUT) has proven to be an effective tool. In this paper, we delve into the potential of Contrastive Language-Image Pre-Training (CLIP) Guided Prompt Learning, proposing a simple structure called CLIP-LUT for image enhancement. We found that the prior knowledge of CLIP can effectively discern the quality of degraded images, which can provide reliable guidance. To be specific, We initially learn image-perceptive prompts to distinguish between original and target images using CLIP model, in the meanwhile, we introduce a very simple network by incorporating a simple baseline to predict the weights of three different LUT as enhancement network. The obtained prompts are used to steer the enhancement network like a loss function and improve the performance of model. We demonstrate that by simply combining a straightforward method with CLIP, we can obtain satisfactory results.
UWFormer: Underwater Image Enhancement via a Semi-Supervised Multi-Scale Transformer
Oct 31, 2023



Underwater images often exhibit poor quality, imbalanced coloration, and low contrast due to the complex and intricate interaction of light, water, and objects. Despite the significant contributions of previous underwater enhancement techniques, there exist several problems that demand further improvement: (i) Current deep learning methodologies depend on Convolutional Neural Networks (CNNs) that lack multi-scale enhancement and also have limited global perception fields. (ii) The scarcity of paired real-world underwater datasets poses a considerable challenge, and the utilization of synthetic image pairs risks overfitting. To address the aforementioned issues, this paper presents a Multi-scale Transformer-based Network called UWFormer for enhancing images at multiple frequencies via semi-supervised learning, in which we propose a Nonlinear Frequency-aware Attention mechanism and a Multi-Scale Fusion Feed-forward Network for low-frequency enhancement. Additionally, we introduce a specialized underwater semi-supervised training strategy, proposing a Subaqueous Perceptual Loss function to generate reliable pseudo labels. Experiments using full-reference and non-reference underwater benchmarks demonstrate that our method outperforms state-of-the-art methods in terms of both quantity and visual quality.