 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Text-Image Fusion Method with Data Augmentation Capabilities for Referring Medical Image Segmentation
Paper and Code
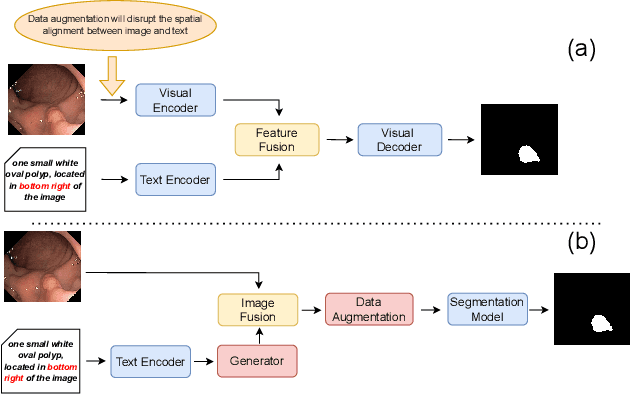
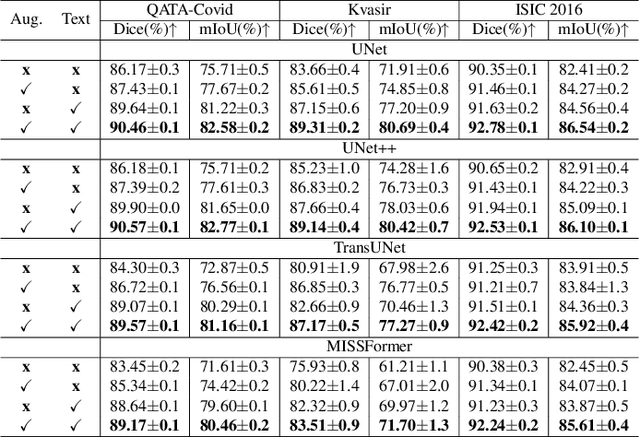
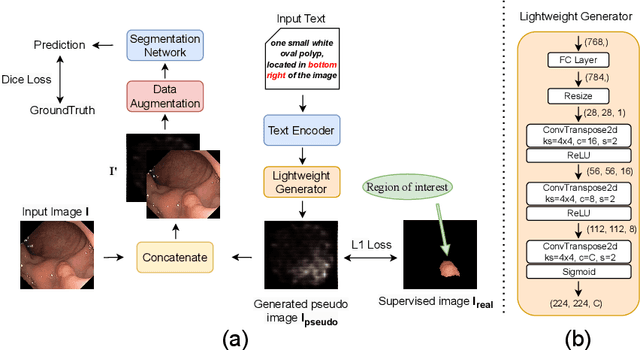

Deep learning relies heavily on data augmentation to mitigate limited data, especially in medical imaging. Recent multimodal learning integrates text and images for segmentation, known as referring or text-guided image segmentation. However, common augmentations like rotation and flipping disrupt spatial alignment between image and text, weakening performance. To address this, we propose an early fusion framework that combines text and visual features before augmentation, preserving spatial consistency. We also design a lightweight generator that projects text embeddings into visual space, bridging semantic gaps. Visualization of generated pseudo-images shows accurate region localization. Our method is evaluated on three medical imaging tasks and four segmentation frameworks, achieving state-of-the-art results. Code is publicly available on GitHub: https://github.com/11yxk/MedSeg_EarlyFusion.