 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025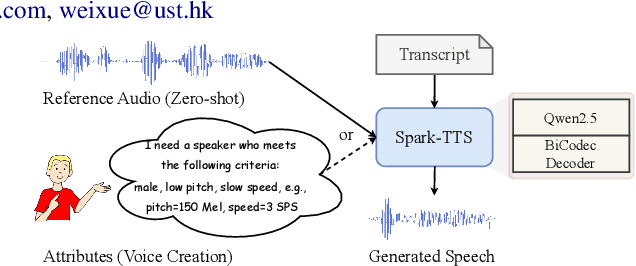



Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.
Debt Collection Negotiations with Large Language Models: An Evaluation System and Optimizing Decision Making with Multi-Agent
Feb 25, 2025



Debt collection negotiations (DCN) are vital for managing non-performing loans (NPLs) and reducing creditor losses. Traditional methods are labor-intensive, while large language models (LLMs) offer promising automation potential. However, prior systems lacked dynamic negotiation and real-time decision-making capabilities. This paper explores LLMs in automating DCN and proposes a novel evaluation framework with 13 metrics across 4 aspects. Our experiments reveal that LLMs tend to over-concede compared to human negotiators. To address this, we propose the Multi-Agent Debt Negotiation (MADeN) framework, incorporating planning and judging modules to improve decision rationality. We also apply post-training techniques, including DPO with rejection sampling, to optimize performance. Our studies provide valuable insights for practitioners and researchers seeking to enhance efficiency and outcomes in this domain.
A Novel Riemannian Sparse Representation Learning Network for Polarimetric SAR Image Classification
Feb 21, 2025



Deep learning is an effective end-to-end method for Polarimetric Synthetic Aperture Radar(PolSAR) image classification, but it lacks the guidance of related mathematical principle and is essentially a black-box model. In addition, existing deep models learn features in Euclidean space, where PolSAR complex matrix is commonly converted into a complex-valued vector as the network input, distorting matrix structure and channel relationship. However, the complex covariance matrix is Hermitian positive definite (HPD), and resides on a Riemannian manifold instead of a Euclidean one. Existing methods cannot measure the geometric distance of HPD matrices and easily cause some misclassifications due to inappropriate Euclidean measures. To address these issues, we propose a novel Riemannian Sparse Representation Learning Network (SRSR CNN) for PolSAR images. Firstly, a superpixel-based Riemannian Sparse Representation (SRSR) model is designed to learn the sparse features with Riemannian metric. Then, the optimization procedure of the SRSR model is inferred and further unfolded into an SRSRnet, which can automatically learn the sparse coefficients and dictionary atoms. Furthermore, to learn contextual high-level features, a CNN-enhanced module is added to improve classification performance. The proposed network is a Sparse Representation (SR) guided deep learning model, which can directly utilize the covariance matrix as the network input, and utilize Riemannian metric to learn geometric structure and sparse features of complex matrices in Riemannian space. Experiments on three real PolSAR datasets demonstrate that the proposed method surpasses state-of-the-art techniques in ensuring accurate edge details and correct region homogeneity for classification.
Graph Federated Learning Based Proactive Content Caching in Edge Computing
Feb 07, 2025



With the rapid growth of mobile data traffic and the increasing prevalence of video streaming, proactive content caching in edge computing has become crucial for reducing latency and alleviating network congestion. However, traditional caching strategies such as FIFO, LRU, and LFU fail to effectively predict future content popularity, while existing proactive caching approaches often require users to upload data to a central server, raising concerns regarding privacy and scalability. To address these challenges, this paper proposes a Graph Federated Learning-based Proactive Content Caching (GFPCC) scheme that enhances caching efficiency while preserving user privacy. The proposed approach integrates federated learning and graph neural networks, enabling users to locally train Light Graph Convolutional Networks (LightGCN) to capture user-item relationships and predict content popularity. Instead of sharing raw data, only the trained model parameters are transmitted to the central server, where a federated averaging algorithm aggregates updates, refines the global model, and selects the most popular files for proactive caching. Experimental evaluations on real-world datasets, such as MovieLens, demonstrate that GFPCC outperforms baseline caching algorithms by achieving higher cache efficiency through more accurate content popularity predictions. Moreover, the federated learning framework strengthens privacy protection while maintaining efficient model training; however, scalability remains a challenge in large-scale networks with dynamic user preferences.
From Uncertain to Safe: Conformal Fine-Tuning of Diffusion Models for Safe PDE Control
Feb 04, 2025



The application of deep learning for partial differential equation (PDE)-constrained control is gaining increasing attention. However, existing methods rarely consider safety requirements crucial in real-world applications. To address this limitation, we propose Safe Diffusion Models for PDE Control (SafeDiffCon), which introduce the uncertainty quantile as model uncertainty quantification to achieve optimal control under safety constraints through both post-training and inference phases. Firstly, our approach post-trains a pre-trained diffusion model to generate control sequences that better satisfy safety constraints while achieving improved control objectives via a reweighted diffusion loss, which incorporates the uncertainty quantile estimated using conformal prediction. Secondly, during inference, the diffusion model dynamically adjusts both its generation process and parameters through iterative guidance and fine-tuning, conditioned on control targets while simultaneously integrating the estimated uncertainty quantile. We evaluate SafeDiffCon on three control tasks: 1D Burgers' equation, 2D incompressible fluid, and controlled nuclear fusion problem. Results demonstrate that SafeDiffCon is the only method that satisfies all safety constraints, whereas other classical and deep learning baselines fail. Furthermore, while adhering to safety constraints, SafeDiffCon achieves the best control performance.
Thoughts Are All Over the Place: On the Underthinking of o1-Like LLMs
Jan 30, 2025



Large language models (LLMs) such as OpenAI's o1 have demonstrated remarkable abilities in complex reasoning tasks by scaling test-time compute and exhibiting human-like deep thinking. However, we identify a phenomenon we term underthinking, where o1-like LLMs frequently switch between different reasoning thoughts without sufficiently exploring promising paths to reach a correct solution. This behavior leads to inadequate depth of reasoning and decreased performance, particularly on challenging mathematical problems. To systematically analyze this issue, we conduct experiments on three challenging test sets and two representative open-source o1-like models, revealing that frequent thought switching correlates with incorrect responses. We introduce a novel metric to quantify underthinking by measuring token efficiency in incorrect answers. To address underthinking, we propose a decoding strategy with thought switching penalty TIP that discourages premature transitions between thoughts, encouraging deeper exploration of each reasoning path. Experimental results demonstrate that our approach improves accuracy across challenging datasets without requiring model fine-tuning. Our findings contribute to understanding reasoning inefficiencies in o1-like LLMs and offer a practical solution to enhance their problem-solving capabilities.
Do Large Language Models Truly Understand Geometric Structures?
Jan 23, 2025



Geometric ability is a significant challenge for large language models (LLMs) due to the need for advanced spatial comprehension and abstract thinking. Existing datasets primarily evaluate LLMs on their final answers, but they cannot truly measure their true understanding of geometric structures, as LLMs can arrive at correct answers by coincidence. To fill this gap, we introduce the GeomRel dataset, designed to evaluate LLMs' understanding of geometric structures by isolating the core step of geometric relationship identification in problem-solving. Using this benchmark, we conduct thorough evaluations of diverse LLMs and identify key limitations in understanding geometric structures. We further propose the Geometry Chain-of-Thought (GeoCoT) method, which enhances LLMs' ability to identify geometric relationships, resulting in significant performance improvements.
FSMoE: A Flexible and Scalable Training System for Sparse Mixture-of-Experts Models
Jan 18, 2025



Recent large language models (LLMs) have tended to leverage sparsity to reduce computations, employing the sparsely activated mixture-of-experts (MoE) technique. MoE introduces four modules, including token routing, token communication, expert computation, and expert parallelism, that impact model quality and training efficiency. To enable versatile usage of MoE models, we introduce FSMoE, a flexible training system optimizing task scheduling with three novel techniques: 1) Unified abstraction and online profiling of MoE modules for task scheduling across various MoE implementations. 2) Co-scheduling intra-node and inter-node communications with computations to minimize communication overheads. 3) To support near-optimal task scheduling, we design an adaptive gradient partitioning method for gradient aggregation and a schedule to adaptively pipeline communications and computations. We conduct extensive experiments with configured MoE layers and real-world MoE models on two GPU clusters. Experimental results show that 1) our FSMoE supports four popular types of MoE routing functions and is more efficient than existing implementations (with up to a 1.42$\times$ speedup), and 2) FSMoE outperforms the state-of-the-art MoE training systems (DeepSpeed-MoE and Tutel) by 1.18$\times$-1.22$\times$ on 1458 MoE layers and 1.19$\times$-3.01$\times$ on real-world MoE models based on GPT-2 and Mixtral using a popular routing function.
Neural Honeytrace: A Robust Plug-and-Play Watermarking Framework against Model Extraction Attacks
Jan 16, 2025Developing high-performance deep learning models is resource-intensive, leading model owners to utilize Machine Learning as a Service (MLaaS) platforms instead of publicly releasing their models. However, malicious users may exploit query interfaces to execute model extraction attacks, reconstructing the target model's functionality locally. While prior research has investigated triggerable watermarking techniques for asserting ownership, existing methods face significant challenges: (1) most approaches require additional training, resulting in high overhead and limited flexibility, and (2) they often fail to account for advanced attackers, leaving them vulnerable to adaptive attacks. In this paper, we propose Neural Honeytrace, a robust plug-and-play watermarking framework against model extraction attacks. We first formulate a watermark transmission model from an information-theoretic perspective, providing an interpretable account of the principles and limitations of existing triggerable watermarking. Guided by the model, we further introduce: (1) a similarity-based training-free watermarking method for plug-and-play and flexible watermarking, and (2) a distribution-based multi-step watermark information transmission strategy for robust watermarking. Comprehensive experiments on four datasets demonstrate that Neural Honeytrace outperforms previous methods in efficiency and resisting adaptive attacks. Neural Honeytrace reduces the average number of samples required for a worst-case t-Test-based copyright claim from $12,000$ to $200$ with zero training cost.
The FACTS Grounding Leaderboard: Benchmarking LLMs' Ability to Ground Responses to Long-Form Input
Jan 06, 2025



We introduce FACTS Grounding, an online leaderboard and associated benchmark that evaluates language models' ability to generate text that is factually accurate with respect to given context in the user prompt. In our benchmark, each prompt includes a user request and a full document, with a maximum length of 32k tokens, requiring long-form responses. The long-form responses are required to be fully grounded in the provided context document while fulfilling the user request. Models are evaluated using automated judge models in two phases: (1) responses are disqualified if they do not fulfill the user request; (2) they are judged as accurate if the response is fully grounded in the provided document. The automated judge models were comprehensively evaluated against a held-out test-set to pick the best prompt template, and the final factuality score is an aggregate of multiple judge models to mitigate evaluation bias. The FACTS Grounding leaderboard will be actively maintained over time, and contains both public and private splits to allow for external participation while guarding the integrity of the leaderboard. It can be found at https://www.kaggle.com/facts-leaderboard.