 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipServ: Fast and Memory-Efficient LLM Inference with Hardware-Aware Lossless Compression
Mar 18, 2026Lossless model compression holds tremendous promise for alleviating the memory and bandwidth bottlenecks in bit-exact Large Language Model (LLM) serving. However, existing approaches often result in substantial inference slowdowns due to fundamental design mismatches with GPU architectures: at the kernel level, variable-length bitstreams produced by traditional entropy codecs break SIMT parallelism; at the system level, decoupled pipelines lead to redundant memory traffic. We present ZipServ, a lossless compression framework co-designed for efficient LLM inference. ZipServ introduces Tensor-Core-Aware Triple Bitmap Encoding (TCA-TBE), a novel fixed-length format that enables constant-time, parallel decoding, together with a fused decompression-GEMM (ZipGEMM) kernel that decompresses weights on-the-fly directly into Tensor Core registers. This "load-compressed, compute-decompressed" design eliminates intermediate buffers and maximizes compute intensity. Experiments show that ZipServ reduces the model size by up to 30%, achieves up to 2.21x kernel-level speedup over NVIDIA's cuBLAS, and expedites end-to-end inference by an average of 1.22x over vLLM. ZipServ is the first lossless compression system that provides both storage savings and substantial acceleration for LLM inference on GPUs.
Efficient MoE Inference with Fine-Grained Scheduling of Disaggregated Expert Parallelism
Dec 25, 2025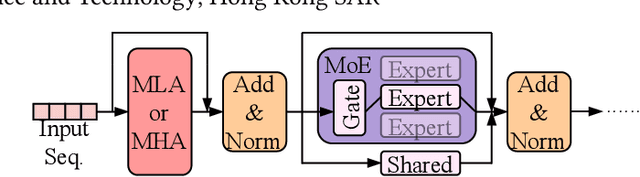

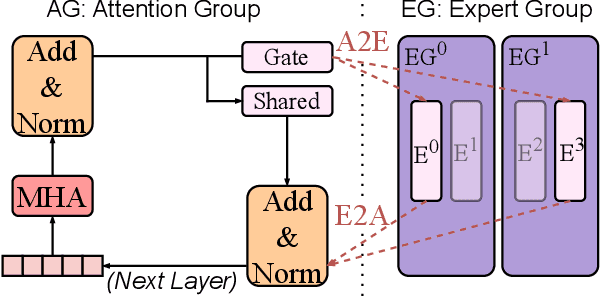
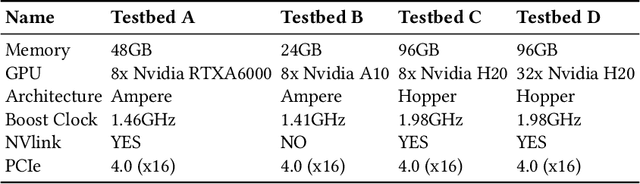
The mixture-of-experts (MoE) architecture scales model size with sublinear computational increase but suffers from memory-intensive inference due to KV caches and sparse expert activation. Recent disaggregated expert parallelism (DEP) distributes attention and experts to dedicated GPU groups but lacks support for shared experts and efficient task scheduling, limiting performance. We propose FinDEP, a fine-grained task scheduling algorithm for DEP that maximizes task overlap to improve MoE inference throughput. FinDEP introduces three innovations: 1) partitioning computation/communication into smaller tasks for fine-grained pipelining, 2) formulating a scheduling optimization supporting variable granularity and ordering, and 3) developing an efficient solver for this large search space. Experiments on four GPU systems with DeepSeek-V2 and Qwen3-MoE show FinDEP improves throughput by up to 1.61x over prior methods, achieving up to 1.24x speedup on a 32-GPU system.
Mediator: Memory-efficient LLM Merging with Less Parameter Conflicts and Uncertainty Based Routing
Feb 06, 2025Model merging aggregates Large Language Models (LLMs) finetuned on different tasks into a stronger one. However, parameter conflicts between models leads to performance degradation in averaging. While model routing addresses this issue by selecting individual models during inference, it imposes excessive storage and compute costs, and fails to leverage the common knowledge from different models. In this work, we observe that different layers exhibit varying levels of parameter conflicts. Building on this insight, we average layers with minimal parameter conflicts and use a novel task-level expert routing for layers with significant conflicts. To further reduce storage costs, inspired by task arithmetic sparsity, we decouple multiple fine-tuned experts into a dense expert and several sparse experts. Considering the out-of-distribution samples, we select and merge appropriate experts based on the task uncertainty of the input data. We conduct extensive experiments on both LLaMA and Qwen with varying parameter scales, and evaluate on real-world reasoning tasks. Results demonstrate that our method consistently achieves significant performance improvements while requiring less system cost compared to existing methods.
FSMoE: A Flexible and Scalable Training System for Sparse Mixture-of-Experts Models
Jan 18, 2025



Recent large language models (LLMs) have tended to leverage sparsity to reduce computations, employing the sparsely activated mixture-of-experts (MoE) technique. MoE introduces four modules, including token routing, token communication, expert computation, and expert parallelism, that impact model quality and training efficiency. To enable versatile usage of MoE models, we introduce FSMoE, a flexible training system optimizing task scheduling with three novel techniques: 1) Unified abstraction and online profiling of MoE modules for task scheduling across various MoE implementations. 2) Co-scheduling intra-node and inter-node communications with computations to minimize communication overheads. 3) To support near-optimal task scheduling, we design an adaptive gradient partitioning method for gradient aggregation and a schedule to adaptively pipeline communications and computations. We conduct extensive experiments with configured MoE layers and real-world MoE models on two GPU clusters. Experimental results show that 1) our FSMoE supports four popular types of MoE routing functions and is more efficient than existing implementations (with up to a 1.42$\times$ speedup), and 2) FSMoE outperforms the state-of-the-art MoE training systems (DeepSpeed-MoE and Tutel) by 1.18$\times$-1.22$\times$ on 1458 MoE layers and 1.19$\times$-3.01$\times$ on real-world MoE models based on GPT-2 and Mixtral using a popular routing function.
Should We Really Edit Language Models? On the Evaluation of Edited Language Models
Oct 24, 2024



Model editing has become an increasingly popular alternative for efficiently updating knowledge within language models. Current methods mainly focus on reliability, generalization, and locality, with many methods excelling across these criteria. Some recent works disclose the pitfalls of these editing methods such as knowledge distortion or conflict. However, the general abilities of post-edited language models remain unexplored. In this paper, we perform a comprehensive evaluation on various editing methods and different language models, and have following findings. (1) Existing editing methods lead to inevitable performance deterioration on general benchmarks, indicating that existing editing methods maintain the general abilities of the model within only a few dozen edits. When the number of edits is slightly large, the intrinsic knowledge structure of the model is disrupted or even completely damaged. (2) Instruction-tuned models are more robust to editing, showing less performance drop on general knowledge after editing. (3) Language model with large scale is more resistant to editing compared to small model. (4) The safety of the edited model, is significantly weakened, even for those safety-aligned models. Our findings indicate that current editing methods are only suitable for small-scale knowledge updates within language models, which motivates further research on more practical and reliable editing methods. The details of code and reproduction can be found in https://github.com/lqinfdim/EditingEvaluation.
FusionLLM: A Decentralized LLM Training System on Geo-distributed GPUs with Adaptive Compression
Oct 16, 2024



To alleviate hardware scarcity in training large deep neural networks (DNNs), particularly large language models (LLMs), we present FusionLLM, a decentralized training system designed and implemented for training DNNs using geo-distributed GPUs across different computing clusters or individual devices. Decentralized training faces significant challenges regarding system design and efficiency, including: 1) the need for remote automatic differentiation (RAD), 2) support for flexible model definitions and heterogeneous software, 3) heterogeneous hardware leading to low resource utilization or the straggler problem, and 4) slow network communication. To address these challenges, in the system design, we represent the model as a directed acyclic graph of operators (OP-DAG). Each node in the DAG represents the operator in the DNNs, while the edge represents the data dependency between operators. Based on this design, 1) users are allowed to customize any DNN without caring low-level operator implementation; 2) we enable the task scheduling with the more fine-grained sub-tasks, offering more optimization space; 3) a DAG runtime executor can implement RAD withour requiring the consistent low-level ML framework versions. To enhance system efficiency, we implement a workload estimator and design an OP-Fence scheduler to cluster devices with similar bandwidths together and partition the DAG to increase throughput. Additionally, we propose an AdaTopK compressor to adaptively compress intermediate activations and gradients at the slowest communication links. To evaluate the convergence and efficiency of our system and algorithms, we train ResNet-101 and GPT-2 on three real-world testbeds using 48 GPUs connected with 8 Mbps~10 Gbps networks. Experimental results demonstrate that our system and method can achieve 1.45 - 9.39x speedup compared to baseline methods while ensuring convergence.
Multi-Task Domain Adaptation for Language Grounding with 3D Objects
Jul 03, 2024



The existing works on object-level language grounding with 3D objects mostly focus on improving performance by utilizing the off-the-shelf pre-trained models to capture features, such as viewpoint selection or geometric priors. However, they have failed to consider exploring the cross-modal representation of language-vision alignment in the cross-domain field. To answer this problem, we propose a novel method called Domain Adaptation for Language Grounding (DA4LG) with 3D objects. Specifically, the proposed DA4LG consists of a visual adapter module with multi-task learning to realize vision-language alignment by comprehensive multimodal feature representation. Experimental results demonstrate that DA4LG competitively performs across visual and non-visual language descriptions, independent of the completeness of observation. DA4LG achieves state-of-the-art performance in the single-view setting and multi-view setting with the accuracy of 83.8% and 86.8% respectively in the language grounding benchmark SNARE. The simulation experiments show the well-practical and generalized performance of DA4LG compared to the existing methods. Our project is available at https://sites.google.com/view/da4lg.
Pruner-Zero: Evolving Symbolic Pruning Metric from scratch for Large Language Models
Jun 05, 2024



Despite the remarkable capabilities, Large Language Models (LLMs) face deployment challenges due to their extensive size. Pruning methods drop a subset of weights to accelerate, but many of them require retraining, which is prohibitively expensive and computationally demanding. Recently, post-training pruning approaches introduced novel metrics, enabling the pruning of LLMs without retraining. However, these metrics require the involvement of human experts and tedious trial and error. To efficiently identify superior pruning metrics, we develop an automatic framework for searching symbolic pruning metrics using genetic programming. In particular, we devise an elaborate search space encompassing the existing pruning metrics to discover the potential symbolic pruning metric. We propose an opposing operation simplification strategy to increase the diversity of the population. In this way, Pruner-Zero allows auto-generation of symbolic pruning metrics. Based on the searched results, we explore the correlation between pruning metrics and performance after pruning and summarize some principles. Extensive experiments on LLaMA and LLaMA-2 on language modeling and zero-shot tasks demonstrate that our Pruner-Zero obtains superior performance than SOTA post-training pruning methods. Code at: \url{https://github.com/pprp/Pruner-Zero}.
ParZC: Parametric Zero-Cost Proxies for Efficient NAS
Feb 03, 2024Recent advancements in Zero-shot Neural Architecture Search (NAS) highlight the efficacy of zero-cost proxies in various NAS benchmarks. Several studies propose the automated design of zero-cost proxies to achieve SOTA performance but require tedious searching progress. Furthermore, we identify a critical issue with current zero-cost proxies: they aggregate node-wise zero-cost statistics without considering the fact that not all nodes in a neural network equally impact performance estimation. Our observations reveal that node-wise zero-cost statistics significantly vary in their contributions to performance, with each node exhibiting a degree of uncertainty. Based on this insight, we introduce a novel method called Parametric Zero-Cost Proxies (ParZC) framework to enhance the adaptability of zero-cost proxies through parameterization. To address the node indiscrimination, we propose a Mixer Architecture with Bayesian Network (MABN) to explore the node-wise zero-cost statistics and estimate node-specific uncertainty. Moreover, we propose DiffKendall as a loss function to directly optimize Kendall's Tau coefficient in a differentiable manner so that our ParZC can better handle the discrepancies in ranking architectures. Comprehensive experiments on NAS-Bench-101, 201, and NDS demonstrate the superiority of our proposed ParZC compared to existing zero-shot NAS methods. Additionally, we demonstrate the versatility and adaptability of ParZC by transferring it to the Vision Transformer search space.
Dissecting the Runtime Performance of the Training, Fine-tuning, and Inference of Large Language Models
Nov 07, 2023Large Language Models (LLMs) have seen great advance in both academia and industry, and their popularity results in numerous open-source frameworks and techniques in accelerating LLM pre-training, fine-tuning, and inference. Training and deploying LLMs are expensive as it requires considerable computing resources and memory, hence many efficient approaches have been developed for improving system pipelines as well as operators. However, the runtime performance can vary significantly across hardware and software stacks, which makes it difficult to choose the best configuration. In this work, we aim to benchmark the performance from both macro and micro perspectives. First, we benchmark the end-to-end performance of pre-training, fine-tuning, and serving LLMs in different sizes , i.e., 7, 13, and 70 billion parameters (7B, 13B, and 70B) on three 8-GPU platforms with and without individual optimization techniques, including ZeRO, quantization, recomputation, FlashAttention. Then, we dive deeper to provide a detailed runtime analysis of the sub-modules, including computing and communication operators in LLMs. For end users, our benchmark and findings help better understand different optimization techniques, training and inference frameworks, together with hardware platforms in choosing configurations for deploying LLMs. For researchers, our in-depth module-wise analyses discover potential opportunities for future work to further optimize the runtime performance of LLMs.