 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient MoE Inference with Fine-Grained Scheduling of Disaggregated Expert Parallelism
Dec 25, 2025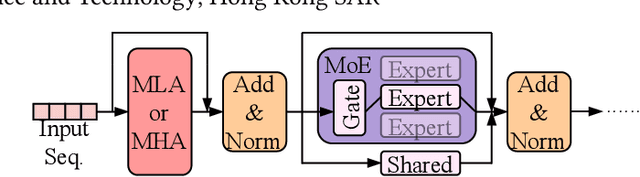

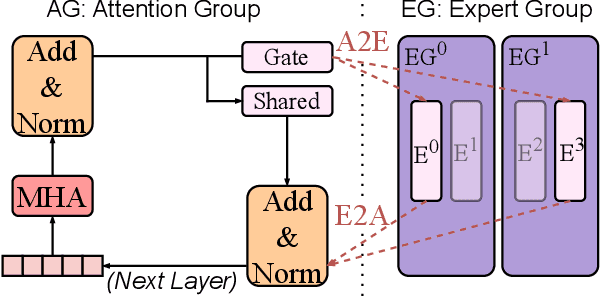
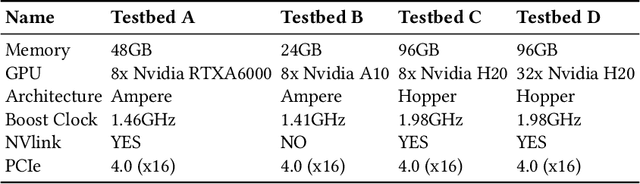
The mixture-of-experts (MoE) architecture scales model size with sublinear computational increase but suffers from memory-intensive inference due to KV caches and sparse expert activation. Recent disaggregated expert parallelism (DEP) distributes attention and experts to dedicated GPU groups but lacks support for shared experts and efficient task scheduling, limiting performance. We propose FinDEP, a fine-grained task scheduling algorithm for DEP that maximizes task overlap to improve MoE inference throughput. FinDEP introduces three innovations: 1) partitioning computation/communication into smaller tasks for fine-grained pipelining, 2) formulating a scheduling optimization supporting variable granularity and ordering, and 3) developing an efficient solver for this large search space. Experiments on four GPU systems with DeepSeek-V2 and Qwen3-MoE show FinDEP improves throughput by up to 1.61x over prior methods, achieving up to 1.24x speedup on a 32-GPU system.
FSMoE: A Flexible and Scalable Training System for Sparse Mixture-of-Experts Models
Jan 18, 2025



Recent large language models (LLMs) have tended to leverage sparsity to reduce computations, employing the sparsely activated mixture-of-experts (MoE) technique. MoE introduces four modules, including token routing, token communication, expert computation, and expert parallelism, that impact model quality and training efficiency. To enable versatile usage of MoE models, we introduce FSMoE, a flexible training system optimizing task scheduling with three novel techniques: 1) Unified abstraction and online profiling of MoE modules for task scheduling across various MoE implementations. 2) Co-scheduling intra-node and inter-node communications with computations to minimize communication overheads. 3) To support near-optimal task scheduling, we design an adaptive gradient partitioning method for gradient aggregation and a schedule to adaptively pipeline communications and computations. We conduct extensive experiments with configured MoE layers and real-world MoE models on two GPU clusters. Experimental results show that 1) our FSMoE supports four popular types of MoE routing functions and is more efficient than existing implementations (with up to a 1.42$\times$ speedup), and 2) FSMoE outperforms the state-of-the-art MoE training systems (DeepSpeed-MoE and Tutel) by 1.18$\times$-1.22$\times$ on 1458 MoE layers and 1.19$\times$-3.01$\times$ on real-world MoE models based on GPT-2 and Mixtral using a popular routing function.