 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-to-Product: Generative Assembly via Bimanual Manipulation
Aug 28, 2025



Creating assembly products demands significant manual effort and expert knowledge in 1) designing the assembly and 2) constructing the product. This paper introduces Prompt-to-Product, an automated pipeline that generates real-world assembly products from natural language prompts. Specifically, we leverage LEGO bricks as the assembly platform and automate the process of creating brick assembly structures. Given the user design requirements, Prompt-to-Product generates physically buildable brick designs, and then leverages a bimanual robotic system to construct the real assembly products, bringing user imaginations into the real world. We conduct a comprehensive user study, and the results demonstrate that Prompt-to-Product significantly lowers the barrier and reduces manual effort in creating assembly products from imaginative ideas.
CaTE Data Curation for Trustworthy AI
Aug 20, 2025This report provides practical guidance to teams designing or developing AI-enabled systems for how to promote trustworthiness during the data curation phase of development. In this report, the authors first define data, the data curation phase, and trustworthiness. We then describe a series of steps that the development team, especially data scientists, can take to build a trustworthy AI-enabled system. We enumerate the sequence of core steps and trace parallel paths where alternatives exist. The descriptions of these steps include strengths, weaknesses, preconditions, outcomes, and relevant open-source software tool implementations. In total, this report is a synthesis of data curation tools and approaches from relevant academic literature, and our goal is to equip readers with a diverse yet coherent set of practices for improving AI trustworthiness.
The FACTS Grounding Leaderboard: Benchmarking LLMs' Ability to Ground Responses to Long-Form Input
Jan 06, 2025



We introduce FACTS Grounding, an online leaderboard and associated benchmark that evaluates language models' ability to generate text that is factually accurate with respect to given context in the user prompt. In our benchmark, each prompt includes a user request and a full document, with a maximum length of 32k tokens, requiring long-form responses. The long-form responses are required to be fully grounded in the provided context document while fulfilling the user request. Models are evaluated using automated judge models in two phases: (1) responses are disqualified if they do not fulfill the user request; (2) they are judged as accurate if the response is fully grounded in the provided document. The automated judge models were comprehensively evaluated against a held-out test-set to pick the best prompt template, and the final factuality score is an aggregate of multiple judge models to mitigate evaluation bias. The FACTS Grounding leaderboard will be actively maintained over time, and contains both public and private splits to allow for external participation while guarding the integrity of the leaderboard. It can be found at https://www.kaggle.com/facts-leaderboard.
Adaptive Tensor Learning with Tensor Networks
Aug 12, 2020

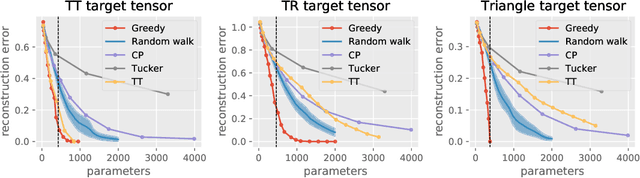
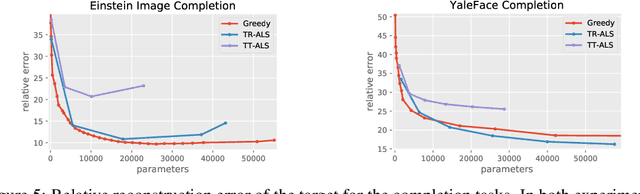
Tensor decomposition techniques have shown great successes in machine learning and data science by extending classical algorithms based on matrix factorization to multi-modal and multi-way data. However, there exist many tensor decomposition models~(CP, Tucker, Tensor Train, etc.) and the rank of such a decomposition is typically a collection of integers rather than a unique number, making model and hyper-parameter selection a tedious and costly task. At the same time, tensor network methods are powerful tools developed in the physics community which have recently shown their potential for machine learning applications and offer a unifying view of the various tensor decomposition models. In this paper, we leverage the tensor network formalism to develop a generic and efficient adaptive algorithm for tensor learning. Our method is based on a simple greedy approach optimizing a differentiable loss function starting from a rank one tensor and successively identifying the most promising tensor network edges for small rank increments. Our algorithm can adaptively identify tensor network structures with small number of parameters that effectively optimize the objective function from data. The framework we introduce is very broad and encompasses many common tensor optimization problems. Experiments on tensor decomposition and tensor completion tasks with both synthetic and real world data demonstrate the effectiveness of the proposed algorithm.
Simultaneous shot inversion for nonuniform geometries using fast data interpolation
Apr 23, 2018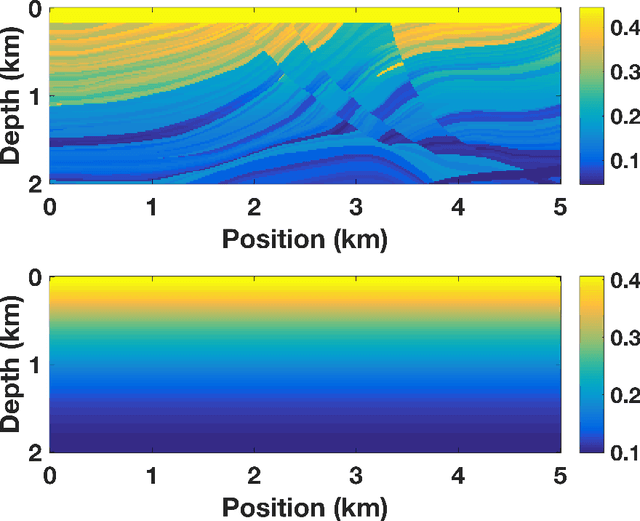
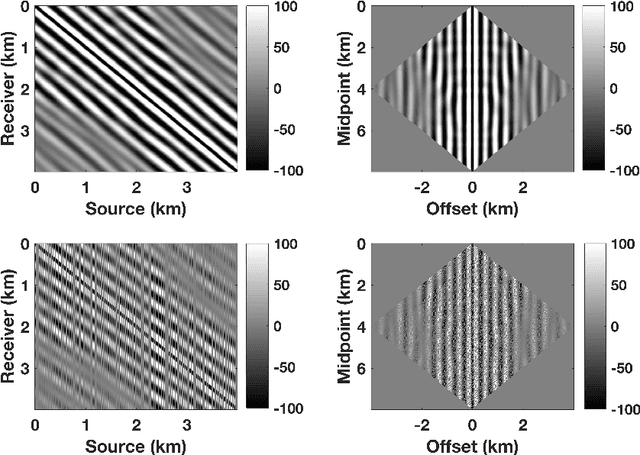
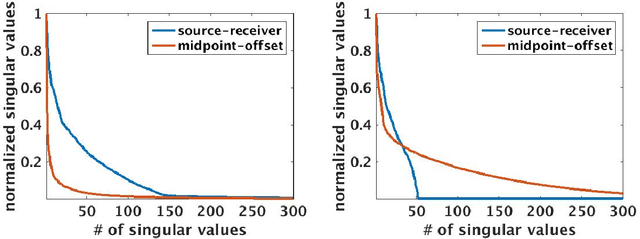
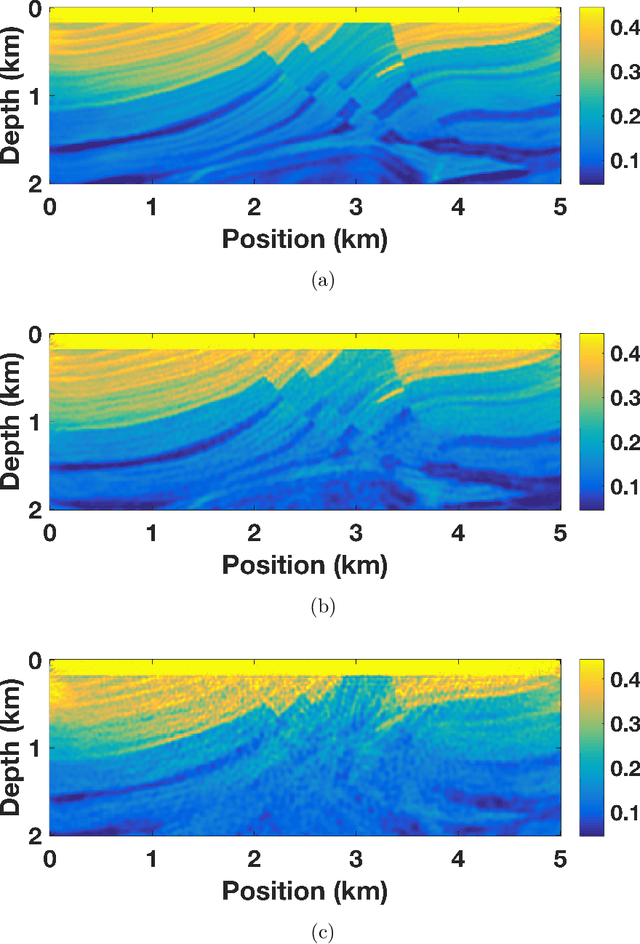
Stochastic optimization is key to efficient inversion in PDE-constrained optimization. Using 'simultaneous shots', or random superposition of source terms, works very well in simple acquisition geometries where all sources see all receivers, but this rarely occurs in practice. We develop an approach that interpolates data to an ideal acquisition geometry while solving the inverse problem using simultaneous shots. The approach is formulated as a joint inverse problem, combining ideas from low-rank interpolation with full-waveform inversion. Results using synthetic experiments illustrate the flexibility and efficiency of the approach.
What Words Do We Use to Lie?: Word Choice in Deceptive Messages
Oct 01, 2017Text messaging is the most widely used form of computer- mediated communication (CMC). Previous findings have shown that linguistic factors can reliably indicate messages as deceptive. For example, users take longer and use more words to craft deceptive messages than they do truthful messages. Existing research has also examined how factors, such as student status and gender, affect rates of deception and word choice in deceptive messages. However, this research has been limited by small sample sizes and has returned contradicting findings. This paper aims to address these issues by using a dataset of text messages collected from a large and varied set of participants using an Android messaging application. The results of this paper show significant differences in word choice and frequency of deceptive messages between male and female participants, as well as between students and non-students.