 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Quantum-Classical Spatiotemporal Forecasting for 3D Cloud Fields
Mar 31, 2026Accurate forecasting of three-dimensional (3D) cloud fields is important for atmospheric analysis and short-range numerical weather prediction, yet it remains challenging because cloud evolution involves cross-layer interactions, nonlocal dependencies, and multiscale spatiotemporal dynamics. Existing spatiotemporal prediction models based on convolutions, recurrence, or attention often rely on locality-biased representations and therefore struggle to preserve fine cloud structures in volumetric forecasting tasks. To address this issue, we propose QENO, a hybrid quantum-inspired spatiotemporal forecasting framework for 3D cloud fields. The proposed architecture consists of four components: a classical spatiotemporal encoder for compact latent representation, a topology-aware quantum enhancement block for modeling nonlocal couplings in latent space, a dynamic fusion temporal unit for integrating measurement-derived quantum features with recurrent memory, and a decoder for reconstructing future cloud volumes. Experiments on CMA-MESO 3D cloud fields show that QENO consistently outperforms representative baselines, including ConvLSTM, PredRNN++, Earthformer, TAU, and SimVP variants, in terms of MSE, MAE, RMSE, SSIM, and threshold-based detection metrics. In particular, QENO achieves an MSE of 0.2038, an RMSE of 0.4514, and an SSIM of 0.6291, while also maintaining a compact parameter budget. These results indicate that topology-aware hybrid quantum-classical feature modeling is a promising direction for 3D cloud structure forecasting and atmospheric Earth observation data analysis.
ZipServ: Fast and Memory-Efficient LLM Inference with Hardware-Aware Lossless Compression
Mar 18, 2026Lossless model compression holds tremendous promise for alleviating the memory and bandwidth bottlenecks in bit-exact Large Language Model (LLM) serving. However, existing approaches often result in substantial inference slowdowns due to fundamental design mismatches with GPU architectures: at the kernel level, variable-length bitstreams produced by traditional entropy codecs break SIMT parallelism; at the system level, decoupled pipelines lead to redundant memory traffic. We present ZipServ, a lossless compression framework co-designed for efficient LLM inference. ZipServ introduces Tensor-Core-Aware Triple Bitmap Encoding (TCA-TBE), a novel fixed-length format that enables constant-time, parallel decoding, together with a fused decompression-GEMM (ZipGEMM) kernel that decompresses weights on-the-fly directly into Tensor Core registers. This "load-compressed, compute-decompressed" design eliminates intermediate buffers and maximizes compute intensity. Experiments show that ZipServ reduces the model size by up to 30%, achieves up to 2.21x kernel-level speedup over NVIDIA's cuBLAS, and expedites end-to-end inference by an average of 1.22x over vLLM. ZipServ is the first lossless compression system that provides both storage savings and substantial acceleration for LLM inference on GPUs.
Are Dilemmas and Conflicts in LLM Alignment Solvable? A View from Priority Graph
Mar 16, 2026As Large Language Models (LLMs) become more powerful and autonomous, they increasingly face conflicts and dilemmas in many scenarios. We first summarize and taxonomize these diverse conflicts. Then, we model the LLM's preferences to make different choices as a priority graph, where instructions and values are nodes, and the edges represent context-specific priorities determined by the model's output distribution. This graph reveals that a unified stable LLM alignment is very challenging, because the graph is neither static nor necessarily consistent in different contexts. Besides, it also reveals a potential vulnerability: priority hacking, where adversaries can craft deceptive contexts to manipulate the graph and bypass safety alignments. To counter this, we propose a runtime verification mechanism, enabling LLMs to query external sources to ground their context and resist manipulation. While this approach enhances robustness, we also acknowledge that many ethical and value dilemmas are philosophically irreducible, posing a long-term, open challenge for the future of AI alignment.
Janus-Q: End-to-End Event-Driven Trading via Hierarchical-Gated Reward Modeling
Feb 23, 2026Financial market movements are often driven by discrete financial events conveyed through news, whose impacts are heterogeneous, abrupt, and difficult to capture under purely numerical prediction objectives. These limitations have motivated growing interest in using textual information as the primary source of trading signals in learning-based systems. Two key challenges hinder existing approaches: (1) the absence of large-scale, event-centric datasets that jointly model news semantics and statistically grounded market reactions, and (2) the misalignment between language model reasoning and financially valid trading behavior under dynamic market conditions. To address these challenges, we propose Janus-Q, an end-to-end event-driven trading framework that elevates financial news events from auxiliary signals to primary decision units. Janus-Q unifies event-centric data construction and model optimization under a two-stage paradigm. Stage I focuses on event-centric data construction, building a large-scale financial news event dataset comprising 62,400 articles annotated with 10 fine-grained event types, associated stocks, sentiment labels, and event-driven cumulative abnormal return (CAR). Stage II performs decision-oriented fine-tuning, combining supervised learning with reinforcement learning guided by a Hierarchical Gated Reward Model (HGRM), which explicitly captures trade-offs among multiple trading objectives. Extensive experiments demonstrate that Janus-Q achieves more consistent, interpretable, and profitable trading decisions than market indices and LLM baselines, improving the Sharpe Ratio by up to 102.0% while increasing direction accuracy by over 17.5% compared to the strongest competing strategies.
OmniReview: A Large-scale Benchmark and LLM-enhanced Framework for Realistic Reviewer Recommendation
Feb 09, 2026Academic peer review remains the cornerstone of scholarly validation, yet the field faces some challenges in data and methods. From the data perspective, existing research is hindered by the scarcity of large-scale, verified benchmarks and oversimplified evaluation metrics that fail to reflect real-world editorial workflows. To bridge this gap, we present OmniReview, a comprehensive dataset constructed by integrating multi-source academic platforms encompassing comprehensive scholarly profiles through the disambiguation pipeline, yielding 202, 756 verified review records. Based on this data, we introduce a three-tier hierarchical evaluaion framework to assess recommendations from recall to precise expert identification. From the method perspective, existing embedding-based approaches suffer from the information bottleneck of semantic compression and limited interpretability. To resolve these method limitations, we propose Profiling Scholars with Multi-gate Mixture-of-Experts (Pro-MMoE), a novel framework that synergizes Large Language Models (LLMs) with Multi-task Learning. Specifically, it utilizes LLM-generated semantic profiles to preserve fine-grained expertise nuances and interpretability, while employing a Task-Adaptive MMoE architecture to dynamically balance conflicting evaluation goals. Comprehensive experiments demonstrate that Pro-MMoE achieves state-of-the-art performance across six of seven metrics, establishing a new benchmark for realistic reviewer recommendation.
Dissecting Outlier Dynamics in LLM NVFP4 Pretraining
Feb 02, 2026Training large language models using 4-bit arithmetic enhances throughput and memory efficiency. Yet, the limited dynamic range of FP4 increases sensitivity to outliers. While NVFP4 mitigates quantization error via hierarchical microscaling, a persistent loss gap remains compared to BF16. This study conducts a longitudinal analysis of outlier dynamics across architecture during NVFP4 pretraining, focusing on where they localize, why they occur, and how they evolve temporally. We find that, compared with Softmax Attention (SA), Linear Attention (LA) reduces per-tensor heavy tails but still exhibits persistent block-level spikes under block quantization. Our analysis attributes outliers to specific architectural components: Softmax in SA, gating in LA, and SwiGLU in FFN, with "post-QK" operations exhibiting higher sensitivity to quantization. Notably, outliers evolve from transient spikes early in training to a small set of persistent hot channels (i.e., channels with persistently large magnitudes) in later stages. Based on these findings, we introduce Hot-Channel Patch (HCP), an online compensation mechanism that identifies hot channels and reinjects residuals using hardware-efficient kernels. We then develop CHON, an NVFP4 training recipe integrating HCP with post-QK operation protection. On GLA-1.3B model trained for 60B tokens, CHON reduces the loss gap to BF16 from 0.94% to 0.58% while maintaining downstream accuracy.
On the Spectral Flattening of Quantized Embeddings
Feb 01, 2026Training Large Language Models (LLMs) at ultra-low precision is critically impeded by instability rooted in the conflict between discrete quantization constraints and the intrinsic heavy-tailed spectral nature of linguistic data. By formalizing the connection between Zipfian statistics and random matrix theory, we prove that the power-law decay in the singular value spectra of embeddings is a fundamental requisite for semantic encoding. We derive theoretical bounds showing that uniform quantization introduces a noise floor that disproportionately truncates this spectral tail, which induces spectral flattening and a strictly provable increase in the stable rank of representations. Empirical validation across diverse architectures including GPT-2 and TinyLlama corroborates that this geometric degradation precipitates representational collapse. This work not only quantifies the spectral sensitivity of LLMs but also establishes spectral fidelity as a necessary condition for stable low-bit optimization.
SONIC: Segmented Optimized Nexus for Information Compression in Key-Value Caching
Jan 29, 2026The linear growth of Key-Value (KV) cache remains a bottleneck for multi-turn LLM deployment. Existing KV cache compression methods often fail to account for the structural properties of multi-turn dialogues, relying on heuristic eviction that risks losing critical context. We propose \textbf{SONIC}, a learning-based framework that compresses historical segments into compact and semantically rich \textbf{Nexus} tokens. By integrating dynamic budget training, SONIC allows flexible adaptation to varying memory constraints without retraining. Experiments show that at compression ratios of 80\% and 50\%, SONIC consistently outperforms baselines such as H2O and StreamingLLM on four diverse multi-turn benchmarks. Specifically, on the widely used MTBench101 benchmark, SONIC achieves an average score improvement of 35.55\% over state-of-the-art baselines, validating its effectiveness in sustaining coherent multi-turn dialogues. Furthermore, SONIC enhances deployment efficiency, accelerating the overall inference process by 50.1\% compared to full-context generation.
Efficient MoE Inference with Fine-Grained Scheduling of Disaggregated Expert Parallelism
Dec 25, 2025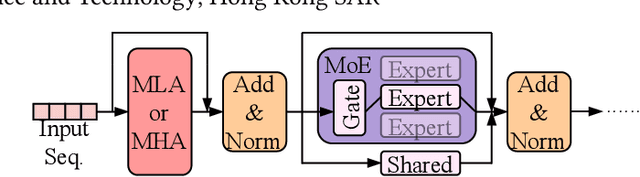

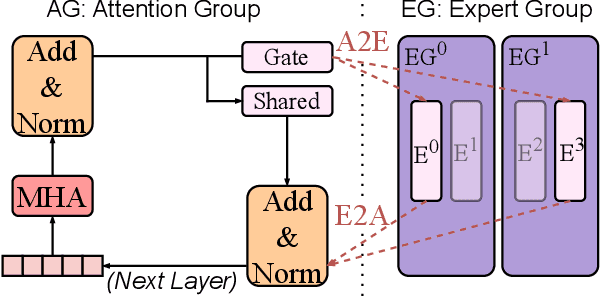
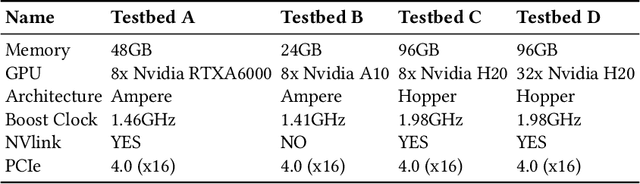
The mixture-of-experts (MoE) architecture scales model size with sublinear computational increase but suffers from memory-intensive inference due to KV caches and sparse expert activation. Recent disaggregated expert parallelism (DEP) distributes attention and experts to dedicated GPU groups but lacks support for shared experts and efficient task scheduling, limiting performance. We propose FinDEP, a fine-grained task scheduling algorithm for DEP that maximizes task overlap to improve MoE inference throughput. FinDEP introduces three innovations: 1) partitioning computation/communication into smaller tasks for fine-grained pipelining, 2) formulating a scheduling optimization supporting variable granularity and ordering, and 3) developing an efficient solver for this large search space. Experiments on four GPU systems with DeepSeek-V2 and Qwen3-MoE show FinDEP improves throughput by up to 1.61x over prior methods, achieving up to 1.24x speedup on a 32-GPU system.
Venus: An Efficient Edge Memory-and-Retrieval System for VLM-based Online Video Understanding
Dec 08, 2025



Vision-language models (VLMs) have demonstrated impressive multimodal comprehension capabilities and are being deployed in an increasing number of online video understanding applications. While recent efforts extensively explore advancing VLMs' reasoning power in these cases, deployment constraints are overlooked, leading to overwhelming system overhead in real-world deployments. To address that, we propose Venus, an on-device memory-and-retrieval system for efficient online video understanding. Venus proposes an edge-cloud disaggregated architecture that sinks memory construction and keyframe retrieval from cloud to edge, operating in two stages. In the ingestion stage, Venus continuously processes streaming edge videos via scene segmentation and clustering, where the selected keyframes are embedded with a multimodal embedding model to build a hierarchical memory for efficient storage and retrieval. In the querying stage, Venus indexes incoming queries from memory, and employs a threshold-based progressive sampling algorithm for keyframe selection that enhances diversity and adaptively balances system cost and reasoning accuracy. Our extensive evaluation shows that Venus achieves a 15x-131x speedup in total response latency compared to state-of-the-art methods, enabling real-time responses within seconds while maintaining comparable or even superior reasoning accuracy.