 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Benchmarks: The Economics of AI Inference
Oct 30, 2025The inference cost of Large Language Models (LLMs) has become a critical factor in determining their commercial viability and widespread adoption. This paper introduces a quantitative ``economics of inference'' framework, treating the LLM inference process as a compute-driven intelligent production activity. We analyze its marginal cost, economies of scale, and quality of output under various performance configurations. Based on empirical data from WiNEval-3.0, we construct the first ``LLM Inference Production Frontier,'' revealing three principles: diminishing marginal cost, diminishing returns to scale, and an optimal cost-effectiveness zone. This paper not only provides an economic basis for model deployment decisions but also lays an empirical foundation for the future market-based pricing and optimization of AI inference resources.
LLM-REVal: Can We Trust LLM Reviewers Yet?
Oct 14, 2025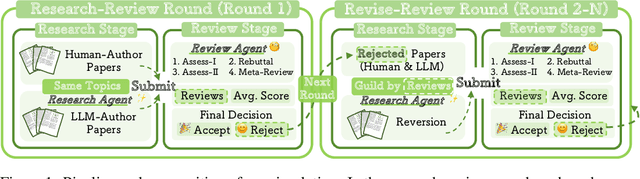
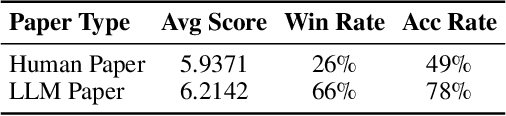
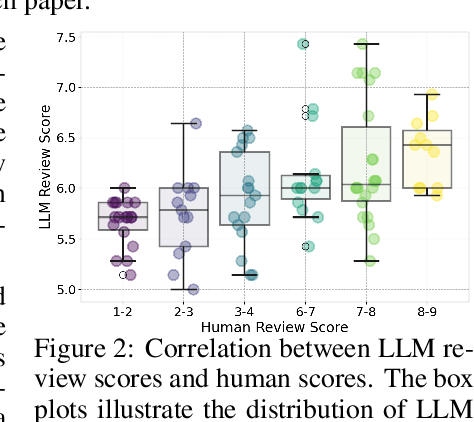
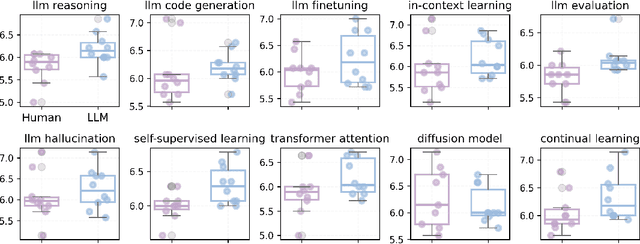
The rapid advancement of large language models (LLMs) has inspired researchers to integrate them extensively into the academic workflow, potentially reshaping how research is practiced and reviewed. While previous studies highlight the potential of LLMs in supporting research and peer review, their dual roles in the academic workflow and the complex interplay between research and review bring new risks that remain largely underexplored. In this study, we focus on how the deep integration of LLMs into both peer-review and research processes may influence scholarly fairness, examining the potential risks of using LLMs as reviewers by simulation. This simulation incorporates a research agent, which generates papers and revises, alongside a review agent, which assesses the submissions. Based on the simulation results, we conduct human annotations and identify pronounced misalignment between LLM-based reviews and human judgments: (1) LLM reviewers systematically inflate scores for LLM-authored papers, assigning them markedly higher scores than human-authored ones; (2) LLM reviewers persistently underrate human-authored papers with critical statements (e.g., risk, fairness), even after multiple revisions. Our analysis reveals that these stem from two primary biases in LLM reviewers: a linguistic feature bias favoring LLM-generated writing styles, and an aversion toward critical statements. These results highlight the risks and equity concerns posed to human authors and academic research if LLMs are deployed in the peer review cycle without adequate caution. On the other hand, revisions guided by LLM reviews yield quality gains in both LLM-based and human evaluations, illustrating the potential of the LLMs-as-reviewers for early-stage researchers and enhancing low-quality papers.
UniView: Enhancing Novel View Synthesis From A Single Image By Unifying Reference Features
Sep 05, 2025The task of synthesizing novel views from a single image is highly ill-posed due to multiple explanations for unobserved areas. Most current methods tend to generate unseen regions from ambiguity priors and interpolation near input views, which often lead to severe distortions. To address this limitation, we propose a novel model dubbed as UniView, which can leverage reference images from a similar object to provide strong prior information during view synthesis. More specifically, we construct a retrieval and augmentation system and employ a multimodal large language model (MLLM) to assist in selecting reference images that meet our requirements. Additionally, a plug-and-play adapter module with multi-level isolation layers is introduced to dynamically generate reference features for the target views. Moreover, in order to preserve the details of an original input image, we design a decoupled triple attention mechanism, which can effectively align and integrate multi-branch features into the synthesis process. Extensive experiments have demonstrated that our UniView significantly improves novel view synthesis performance and outperforms state-of-the-art methods on the challenging datasets.
HierarchicalPrune: Position-Aware Compression for Large-Scale Diffusion Models
Aug 06, 2025State-of-the-art text-to-image diffusion models (DMs) achieve remarkable quality, yet their massive parameter scale (8-11B) poses significant challenges for inferences on resource-constrained devices. In this paper, we present HierarchicalPrune, a novel compression framework grounded in a key observation: DM blocks exhibit distinct functional hierarchies, where early blocks establish semantic structures while later blocks handle texture refinements. HierarchicalPrune synergistically combines three techniques: (1) Hierarchical Position Pruning, which identifies and removes less essential later blocks based on position hierarchy; (2) Positional Weight Preservation, which systematically protects early model portions that are essential for semantic structural integrity; and (3) Sensitivity-Guided Distillation, which adjusts knowledge-transfer intensity based on our discovery of block-wise sensitivity variations. As a result, our framework brings billion-scale diffusion models into a range more suitable for on-device inference, while preserving the quality of the output images. Specifically, when combined with INT4 weight quantisation, HierarchicalPrune achieves 77.5-80.4% memory footprint reduction (e.g., from 15.8 GB to 3.2 GB) and 27.9-38.0% latency reduction, measured on server and consumer grade GPUs, with the minimum drop of 2.6% in GenEval score and 7% in HPSv2 score compared to the original model. Last but not least, our comprehensive user study with 85 participants demonstrates that HierarchicalPrune maintains perceptual quality comparable to the original model while significantly outperforming prior works.
2024 NASA SUITS Report: LLM-Driven Immersive Augmented Reality User Interface for Robotics and Space Exploration
Jul 01, 2025As modern computing advances, new interaction paradigms have emerged, particularly in Augmented Reality (AR), which overlays virtual interfaces onto physical objects. This evolution poses challenges in machine perception, especially for tasks like 3D object pose estimation in complex, dynamic environments. Our project addresses critical issues in human-robot interaction within mobile AR, focusing on non-intrusive, spatially aware interfaces. We present URSA, an LLM-driven immersive AR system developed for NASA's 2023-2024 SUITS challenge, targeting future spaceflight needs such as the Artemis missions. URSA integrates three core technologies: a head-mounted AR device (e.g., HoloLens) for intuitive visual feedback, voice control powered by large language models for hands-free interaction, and robot tracking algorithms that enable accurate 3D localization in dynamic settings. To enhance precision, we leverage digital twin localization technologies, using datasets like DTTD-Mobile and specialized hardware such as the ZED2 camera for real-world tracking under noise and occlusion. Our system enables real-time robot control and monitoring via an AR interface, even in the absence of ground-truth sensors--vital for hazardous or remote operations. Key contributions include: (1) a non-intrusive AR interface with LLM-based voice input; (2) a ZED2-based dataset tailored for non-rigid robotic bodies; (3) a Local Mission Control Console (LMCC) for mission visualization; (4) a transformer-based 6DoF pose estimator (DTTDNet) optimized for depth fusion and real-time tracking; and (5) end-to-end integration for astronaut mission support. This work advances digital twin applications in robotics, offering scalable solutions for both aerospace and industrial domains.
Position: Intelligent Science Laboratory Requires the Integration of Cognitive and Embodied AI
Jun 24, 2025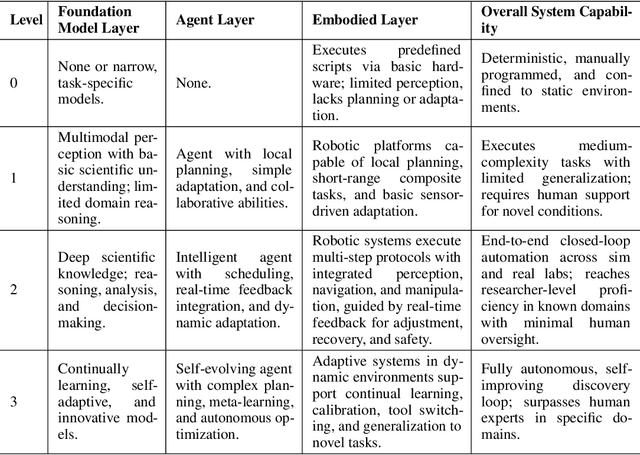
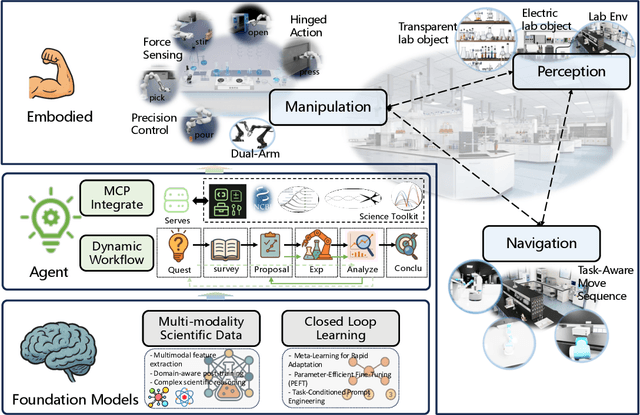
Scientific discovery has long been constrained by human limitations in expertise, physical capability, and sleep cycles. The recent rise of AI scientists and automated laboratories has accelerated both the cognitive and operational aspects of research. However, key limitations persist: AI systems are often confined to virtual environments, while automated laboratories lack the flexibility and autonomy to adaptively test new hypotheses in the physical world. Recent advances in embodied AI, such as generalist robot foundation models, diffusion-based action policies, fine-grained manipulation learning, and sim-to-real transfer, highlight the promise of integrating cognitive and embodied intelligence. This convergence opens the door to closed-loop systems that support iterative, autonomous experimentation and the possibility of serendipitous discovery. In this position paper, we propose the paradigm of Intelligent Science Laboratories (ISLs): a multi-layered, closed-loop framework that deeply integrates cognitive and embodied intelligence. ISLs unify foundation models for scientific reasoning, agent-based workflow orchestration, and embodied agents for robust physical experimentation. We argue that such systems are essential for overcoming the current limitations of scientific discovery and for realizing the full transformative potential of AI-driven science.
HauntAttack: When Attack Follows Reasoning as a Shadow
Jun 08, 2025



Emerging Large Reasoning Models (LRMs) consistently excel in mathematical and reasoning tasks, showcasing exceptional capabilities. However, the enhancement of reasoning abilities and the exposure of their internal reasoning processes introduce new safety vulnerabilities. One intriguing concern is: when reasoning is strongly entangled with harmfulness, what safety-reasoning trade-off do LRMs exhibit? To address this issue, we introduce HauntAttack, a novel and general-purpose black-box attack framework that systematically embeds harmful instructions into reasoning questions. Specifically, we treat reasoning questions as carriers and substitute one of their original conditions with a harmful instruction. This process creates a reasoning pathway in which the model is guided step by step toward generating unsafe outputs. Based on HauntAttack, we conduct comprehensive experiments on multiple LRMs. Our results reveal that even the most advanced LRMs exhibit significant safety vulnerabilities. Additionally, we perform a detailed analysis of different models, various types of harmful instructions, and model output patterns, providing valuable insights into the security of LRMs.
MGS3: A Multi-Granularity Self-Supervised Code Search Framework
May 30, 2025In the pursuit of enhancing software reusability and developer productivity, code search has emerged as a key area, aimed at retrieving code snippets relevant to functionalities based on natural language queries. Despite significant progress in self-supervised code pre-training utilizing the vast amount of code data in repositories, existing methods have primarily focused on leveraging contrastive learning to align natural language with function-level code snippets. These studies have overlooked the abundance of fine-grained (such as block-level and statement-level) code snippets prevalent within the function-level code snippets, which results in suboptimal performance across all levels of granularity. To address this problem, we first construct a multi-granularity code search dataset called MGCodeSearchNet, which contains 536K+ pairs of natural language and code snippets. Subsequently, we introduce a novel Multi-Granularity Self-Supervised contrastive learning code Search framework (MGS$^{3}$}). First, MGS$^{3}$ features a Hierarchical Multi-Granularity Representation module (HMGR), which leverages syntactic structural relationships for hierarchical representation and aggregates fine-grained information into coarser-grained representations. Then, during the contrastive learning phase, we endeavor to construct positive samples of the same granularity for fine-grained code, and introduce in-function negative samples for fine-grained code. Finally, we conduct extensive experiments on code search benchmarks across various granularities, demonstrating that the framework exhibits outstanding performance in code search tasks of multiple granularities. These experiments also showcase its model-agnostic nature and compatibility with existing pre-trained code representation models.
LabUtopia: High-Fidelity Simulation and Hierarchical Benchmark for Scientific Embodied Agents
May 28, 2025



Scientific embodied agents play a crucial role in modern laboratories by automating complex experimental workflows. Compared to typical household environments, laboratory settings impose significantly higher demands on perception of physical-chemical transformations and long-horizon planning, making them an ideal testbed for advancing embodied intelligence. However, its development has been long hampered by the lack of suitable simulator and benchmarks. In this paper, we address this gap by introducing LabUtopia, a comprehensive simulation and benchmarking suite designed to facilitate the development of generalizable, reasoning-capable embodied agents in laboratory settings. Specifically, it integrates i) LabSim, a high-fidelity simulator supporting multi-physics and chemically meaningful interactions; ii) LabScene, a scalable procedural generator for diverse scientific scenes; and iii) LabBench, a hierarchical benchmark spanning five levels of complexity from atomic actions to long-horizon mobile manipulation. LabUtopia supports 30 distinct tasks and includes more than 200 scene and instrument assets, enabling large-scale training and principled evaluation in high-complexity environments. We demonstrate that LabUtopia offers a powerful platform for advancing the integration of perception, planning, and control in scientific-purpose agents and provides a rigorous testbed for exploring the practical capabilities and generalization limits of embodied intelligence in future research.
KnowTrace: Bootstrapping Iterative Retrieval-Augmented Generation with Structured Knowledge Tracing
May 26, 2025



Recent advances in retrieval-augmented generation (RAG) furnish large language models (LLMs) with iterative retrievals of relevant information to handle complex multi-hop questions. These methods typically alternate between LLM reasoning and retrieval to accumulate external information into the LLM's context. However, the ever-growing context inherently imposes an increasing burden on the LLM to perceive connections among critical information pieces, with futile reasoning steps further exacerbating this overload issue. In this paper, we present KnowTrace, an elegant RAG framework to (1) mitigate the context overload and (2) bootstrap higher-quality multi-step reasoning. Instead of simply piling the retrieved contents, KnowTrace autonomously traces out desired knowledge triplets to organize a specific knowledge graph relevant to the input question. Such a structured workflow not only empowers the LLM with an intelligible context for inference, but also naturally inspires a reflective mechanism of knowledge backtracing to identify contributive LLM generations as process supervision data for self-bootstrapping. Extensive experiments show that KnowTrace consistently surpasses existing methods across three multi-hop question answering benchmarks, and the bootstrapped version further amplifies the gains.