 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRan Xu
UniControl: A Unified Diffusion Model for Controllable Visual Generation In the Wild
May 25, 2023

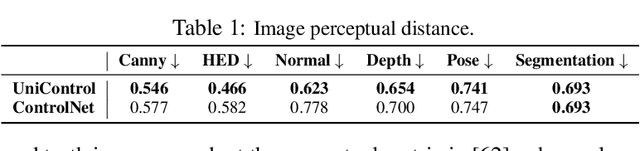
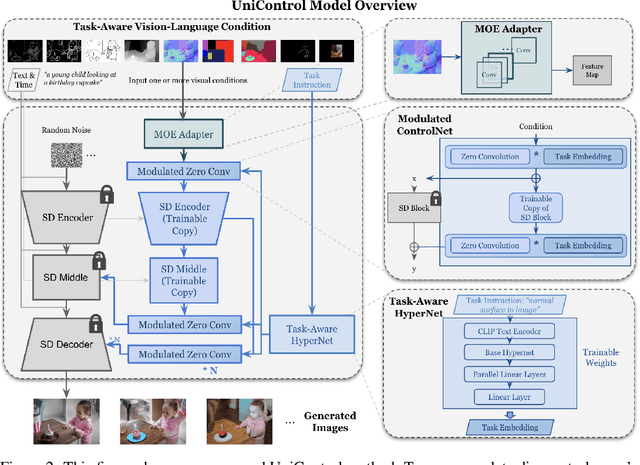

Achieving machine autonomy and human control often represent divergent objectives in the design of interactive AI systems. Visual generative foundation models such as Stable Diffusion show promise in navigating these goals, especially when prompted with arbitrary languages. However, they often fall short in generating images with spatial, structural, or geometric controls. The integration of such controls, which can accommodate various visual conditions in a single unified model, remains an unaddressed challenge. In response, we introduce UniControl, a new generative foundation model that consolidates a wide array of controllable condition-to-image (C2I) tasks within a singular framework, while still allowing for arbitrary language prompts. UniControl enables pixel-level-precise image generation, where visual conditions primarily influence the generated structures and language prompts guide the style and context. To equip UniControl with the capacity to handle diverse visual conditions, we augment pretrained text-to-image diffusion models and introduce a task-aware HyperNet to modulate the diffusion models, enabling the adaptation to different C2I tasks simultaneously. Trained on nine unique C2I tasks, UniControl demonstrates impressive zero-shot generation abilities with unseen visual conditions. Experimental results show that UniControl often surpasses the performance of single-task-controlled methods of comparable model sizes. This control versatility positions UniControl as a significant advancement in the realm of controllable visual generation.
ULIP-2: Towards Scalable Multimodal Pre-training for 3D Understanding
May 18, 2023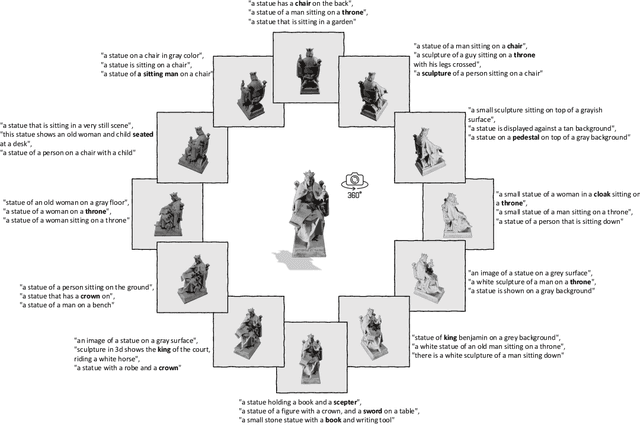

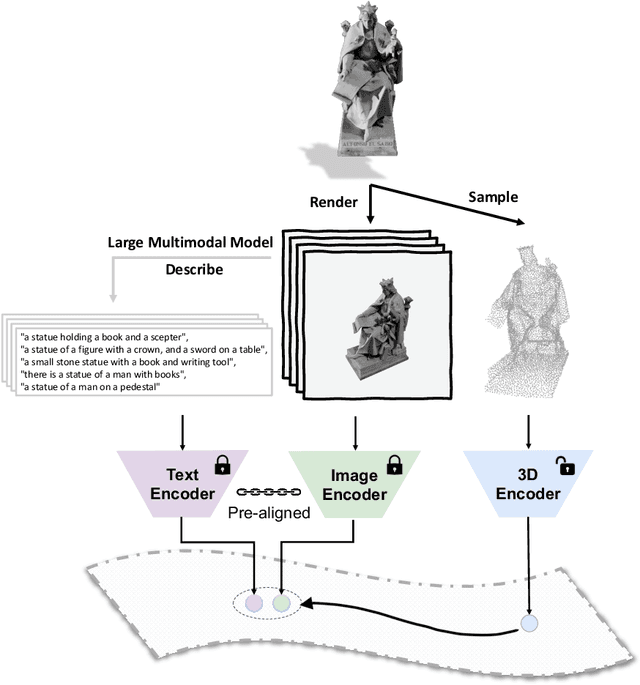
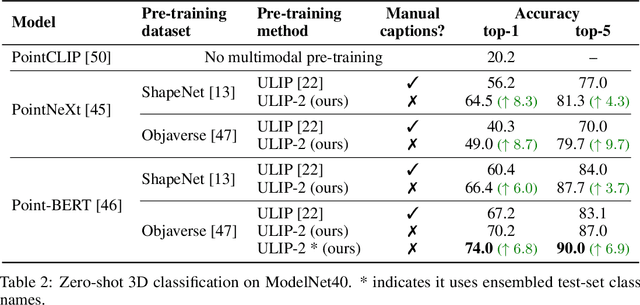
Recent advancements in multimodal pre-training methods have shown promising efficacy in 3D representation learning by aligning multimodal features across 3D shapes, their 2D counterparts, and language descriptions. However, the methods used by existing multimodal pre-training frameworks to gather multimodal data for 3D applications lack scalability and comprehensiveness, potentially constraining the full potential of multimodal learning. The main bottleneck lies in the language modality's scalability and comprehensiveness. To address this, we introduce ULIP-2, a tri-modal pre-training framework that leverages state-of-the-art large multimodal models to automatically generate holistic language counterparts for 3D objects. It does not require any 3D annotations, and is therefore scalable to large datasets. We conduct experiments on two large-scale 3D datasets, Objaverse and ShapeNet, and augment them with tri-modal datasets of 3D point clouds, images, and language for training ULIP-2. ULIP-2 achieves significant improvements on downstream zero-shot classification on ModelNet40 (74.0% in top-1 accuracy); on the real-world ScanObjectNN benchmark, it obtains 91.5% in overall accuracy with only 1.4 million parameters, signifying a breakthrough in scalable multimodal 3D representation learning without human 3D annotations. The code, along with the generated tri-modal datasets, can be found at https://github.com/salesforce/ULIP.
ULIP-2: Towards Scalable Multimodal Pre-training For 3D Understanding
May 14, 2023Recent advancements in multimodal pre-training methods have shown promising efficacy in 3D representation learning by aligning features across 3D modality, their 2D counterpart modality, and corresponding language modality. However, the methods used by existing multimodal pre-training frameworks to gather multimodal data for 3D applications lack scalability and comprehensiveness, potentially constraining the full potential of multimodal learning. The main bottleneck lies in the language modality's scalability and comprehensiveness. To address this bottleneck, we introduce ULIP-2, a multimodal pre-training framework that leverages state-of-the-art multimodal large language models (LLMs) pre-trained on extensive knowledge to automatically generate holistic language counterparts for 3D objects. We conduct experiments on two large-scale datasets, Objaverse and ShapeNet55, and release our generated three-modality triplet datasets (3D Point Cloud - Image - Language), named "ULIP-Objaverse Triplets" and "ULIP-ShapeNet Triplets". ULIP-2 requires only 3D data itself and eliminates the need for any manual annotation effort, demonstrating its scalability; and ULIP-2 achieves remarkable improvements on downstream zero-shot classification on ModelNet40 (74% Top1 Accuracy). Moreover, ULIP-2 sets a new record on the real-world ScanObjectNN benchmark (91.5% Overall Accuracy) while utilizing only 1.4 million parameters(~10x fewer than current SOTA), signifying a breakthrough in scalable multimodal 3D representation learning without human annotations. The code and datasets are available at https://github.com/salesforce/ULIP.
Mask-free OVIS: Open-Vocabulary Instance Segmentation without Manual Mask Annotations
Mar 29, 2023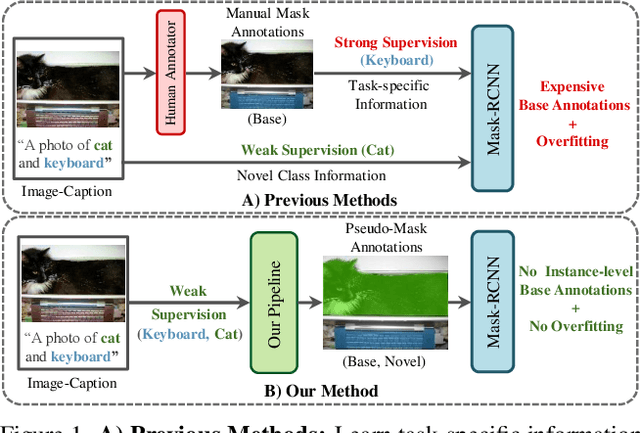
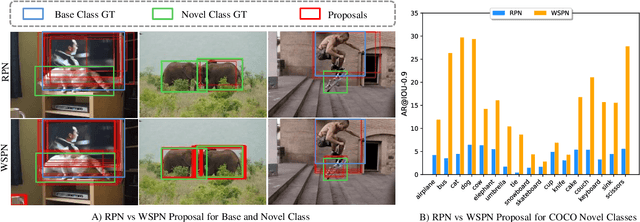
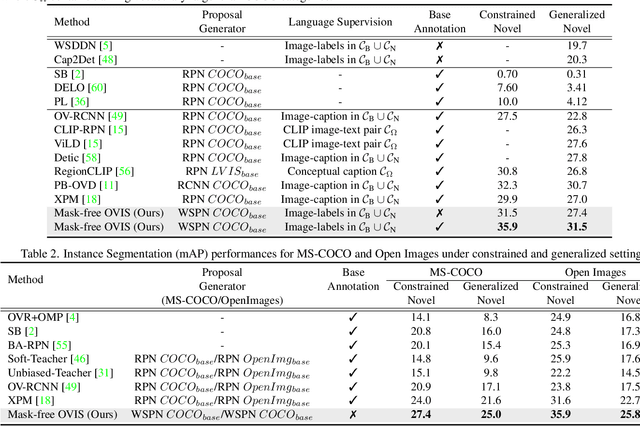
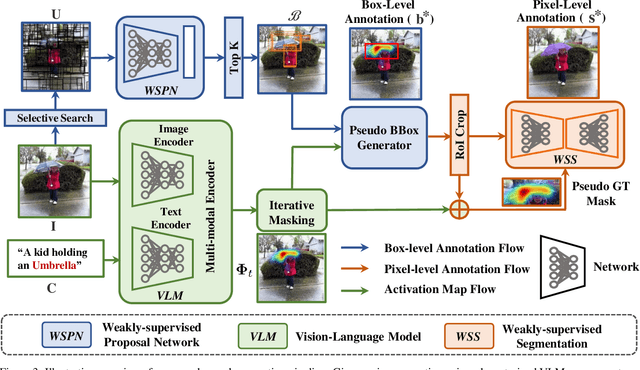
Existing instance segmentation models learn task-specific information using manual mask annotations from base (training) categories. These mask annotations require tremendous human effort, limiting the scalability to annotate novel (new) categories. To alleviate this problem, Open-Vocabulary (OV) methods leverage large-scale image-caption pairs and vision-language models to learn novel categories. In summary, an OV method learns task-specific information using strong supervision from base annotations and novel category information using weak supervision from image-captions pairs. This difference between strong and weak supervision leads to overfitting on base categories, resulting in poor generalization towards novel categories. In this work, we overcome this issue by learning both base and novel categories from pseudo-mask annotations generated by the vision-language model in a weakly supervised manner using our proposed Mask-free OVIS pipeline. Our method automatically generates pseudo-mask annotations by leveraging the localization ability of a pre-trained vision-language model for objects present in image-caption pairs. The generated pseudo-mask annotations are then used to supervise an instance segmentation model, freeing the entire pipeline from any labour-expensive instance-level annotations and overfitting. Our extensive experiments show that our method trained with just pseudo-masks significantly improves the mAP scores on the MS-COCO dataset and OpenImages dataset compared to the recent state-of-the-art methods trained with manual masks. Codes and models are provided in https://vibashan.github.io/ovis-web/.
GlueGen: Plug and Play Multi-modal Encoders for X-to-image Generation
Mar 17, 2023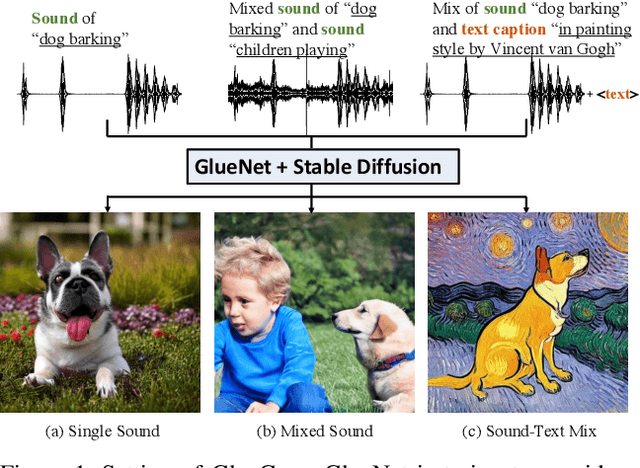
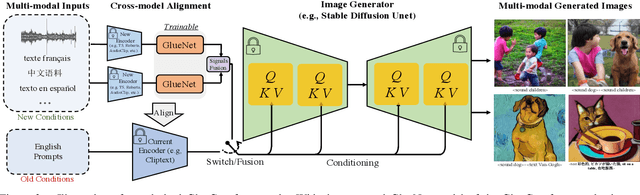

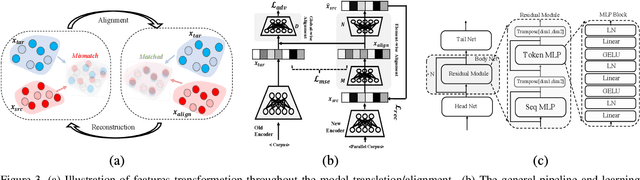
Text-to-image (T2I) models based on diffusion processes have achieved remarkable success in controllable image generation using user-provided captions. However, the tight coupling between the current text encoder and image decoder in T2I models makes it challenging to replace or upgrade. Such changes often require massive fine-tuning or even training from scratch with the prohibitive expense. To address this problem, we propose GlueGen, which applies a newly proposed GlueNet model to align features from single-modal or multi-modal encoders with the latent space of an existing T2I model. The approach introduces a new training objective that leverages parallel corpora to align the representation spaces of different encoders. Empirical results show that GlueNet can be trained efficiently and enables various capabilities beyond previous state-of-the-art models: 1) multilingual language models such as XLM-Roberta can be aligned with existing T2I models, allowing for the generation of high-quality images from captions beyond English; 2) GlueNet can align multi-modal encoders such as AudioCLIP with the Stable Diffusion model, enabling sound-to-image generation; 3) it can also upgrade the current text encoder of the latent diffusion model for challenging case generation. By the alignment of various feature representations, the GlueNet allows for flexible and efficient integration of new functionality into existing T2I models and sheds light on X-to-image (X2I) generation.
HIVE: Harnessing Human Feedback for Instructional Visual Editing
Mar 16, 2023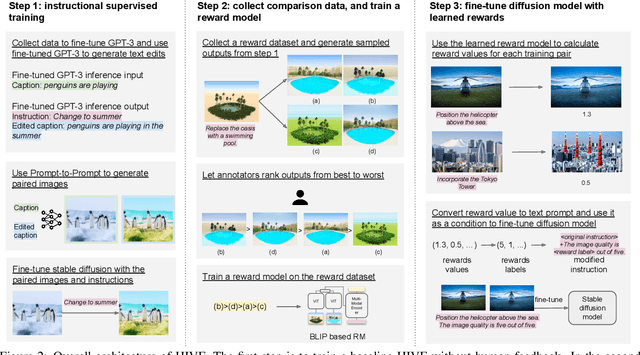
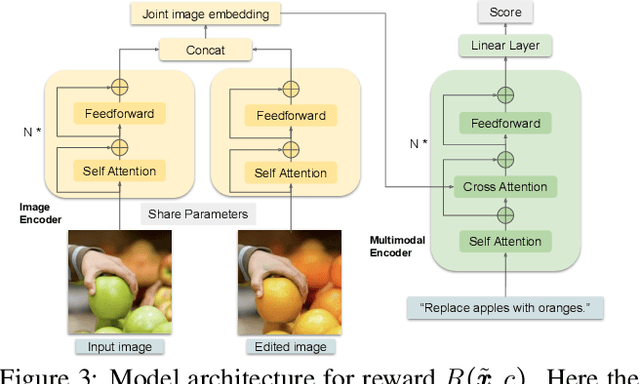


Incorporating human feedback has been shown to be crucial to align text generated by large language models to human preferences. We hypothesize that state-of-the-art instructional image editing models, where outputs are generated based on an input image and an editing instruction, could similarly benefit from human feedback, as their outputs may not adhere to the correct instructions and preferences of users. In this paper, we present a novel framework to harness human feedback for instructional visual editing (HIVE). Specifically, we collect human feedback on the edited images and learn a reward function to capture the underlying user preferences. We then introduce scalable diffusion model fine-tuning methods that can incorporate human preferences based on the estimated reward. Besides, to mitigate the bias brought by the limitation of data, we contribute a new 1M training dataset, a 3.6K reward dataset for rewards learning, and a 1K evaluation dataset to boost the performance of instructional image editing. We conduct extensive empirical experiments quantitatively and qualitatively, showing that HIVE is favored over previous state-of-the-art instructional image editing approaches by a large margin.
Deformer: Dynamic Fusion Transformer for Robust Hand Pose Estimation
Mar 09, 2023
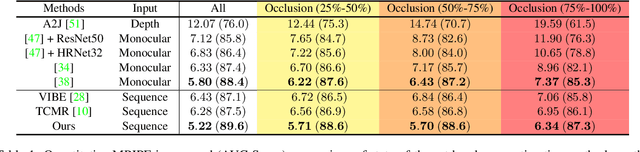
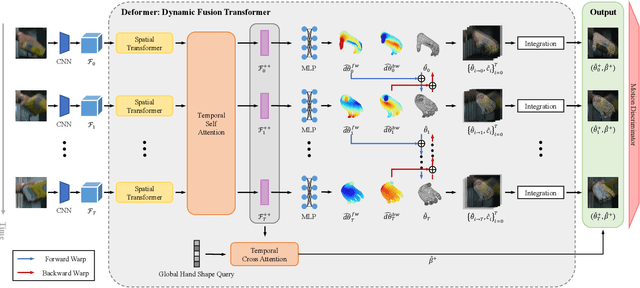

Accurately estimating 3D hand pose is crucial for understanding how humans interact with the world. Despite remarkable progress, existing methods often struggle to generate plausible hand poses when the hand is heavily occluded or blurred. In videos, the movements of the hand allow us to observe various parts of the hand that may be occluded or blurred in a single frame. To adaptively leverage the visual clue before and after the occlusion or blurring for robust hand pose estimation, we propose the Deformer: a framework that implicitly reasons about the relationship between hand parts within the same image (spatial dimension) and different timesteps (temporal dimension). We show that a naive application of the transformer self-attention mechanism is not sufficient because motion blur or occlusions in certain frames can lead to heavily distorted hand features and generate imprecise keys and queries. To address this challenge, we incorporate a Dynamic Fusion Module into Deformer, which predicts the deformation of the hand and warps the hand mesh predictions from nearby frames to explicitly support the current frame estimation. Furthermore, we have observed that errors are unevenly distributed across different hand parts, with vertices around fingertips having disproportionately higher errors than those around the palm. We mitigate this issue by introducing a new loss function called maxMSE that automatically adjusts the weight of every vertex to focus the model on critical hand parts. Extensive experiments show that our method significantly outperforms state-of-the-art methods by 10%, and is more robust to occlusions (over 14%).
Neighborhood-Regularized Self-Training for Learning with Few Labels
Jan 10, 2023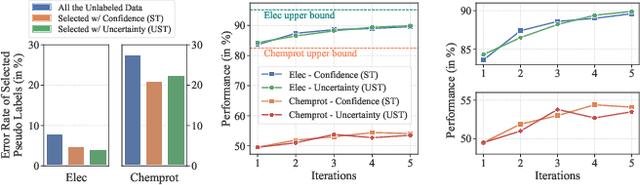
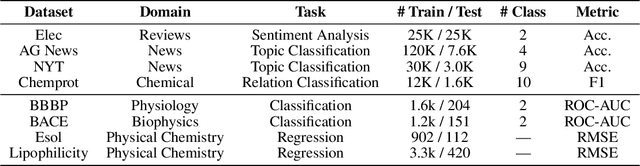
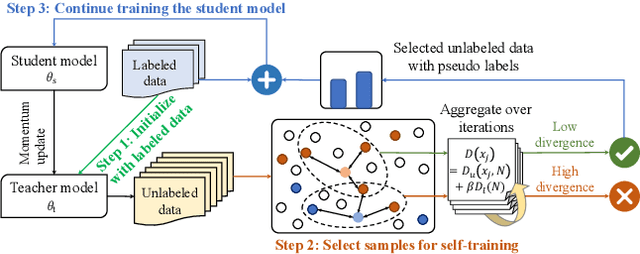
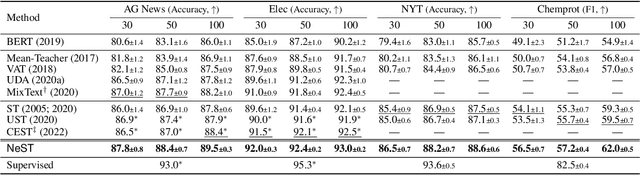
Training deep neural networks (DNNs) with limited supervision has been a popular research topic as it can significantly alleviate the annotation burden. Self-training has been successfully applied in semi-supervised learning tasks, but one drawback of self-training is that it is vulnerable to the label noise from incorrect pseudo labels. Inspired by the fact that samples with similar labels tend to share similar representations, we develop a neighborhood-based sample selection approach to tackle the issue of noisy pseudo labels. We further stabilize self-training via aggregating the predictions from different rounds during sample selection. Experiments on eight tasks show that our proposed method outperforms the strongest self-training baseline with 1.83% and 2.51% performance gain for text and graph datasets on average. Our further analysis demonstrates that our proposed data selection strategy reduces the noise of pseudo labels by 36.8% and saves 57.3% of the time when compared with the best baseline. Our code and appendices will be uploaded to https://github.com/ritaranx/NeST.
Model-Agnostic Hierarchical Attention for 3D Object Detection
Jan 06, 2023
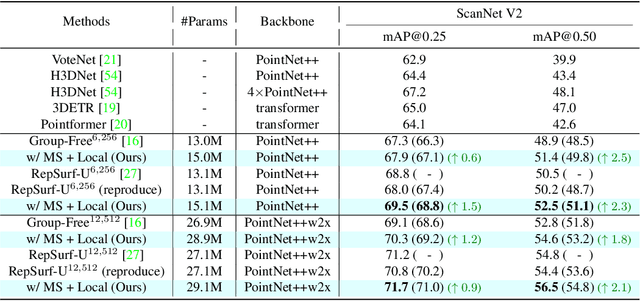
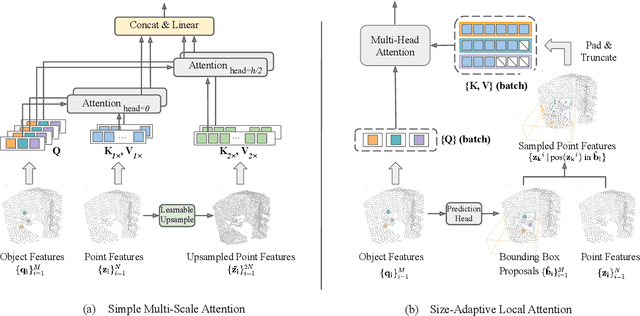
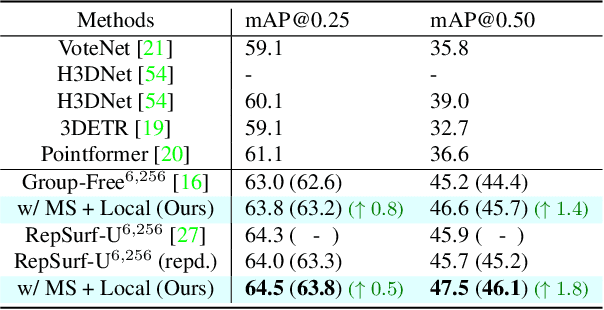
Transformers as versatile network architectures have recently seen great success in 3D point cloud object detection. However, the lack of hierarchy in a plain transformer makes it difficult to learn features at different scales and restrains its ability to extract localized features. Such limitation makes them have imbalanced performance on objects of different sizes, with inferior performance on smaller ones. In this work, we propose two novel attention mechanisms as modularized hierarchical designs for transformer-based 3D detectors. To enable feature learning at different scales, we propose Simple Multi-Scale Attention that builds multi-scale tokens from a single-scale input feature. For localized feature aggregation, we propose Size-Adaptive Local Attention with adaptive attention ranges for every bounding box proposal. Both of our attention modules are model-agnostic network layers that can be plugged into existing point cloud transformers for end-to-end training. We evaluate our method on two widely used indoor 3D point cloud object detection benchmarks. By plugging our proposed modules into the state-of-the-art transformer-based 3D detector, we improve the previous best results on both benchmarks, with the largest improvement margin on small objects.