 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialBGM: A Benchmark for Background Music Recommendation from Everyday Multi-Turn Dialogues
Apr 09, 2026Selecting an appropriate background music (BGM) that supports natural human conversation is a common production step in media and interactive systems. In this paper, we introduce dialogue-conditioned BGM recommendation, where a model should select non-intrusive, fitting music for a multi-turn conversation that often contains no music descriptors. To study this novel problem, we present DialBGM, a benchmark of 1,200 open-domain daily dialogues, each paired with four candidate music clips and annotated with human preference rankings. Rankings are determined by background suitability criteria, including contextual relevance, non-intrusiveness, and consistency. We evaluate a wide range of open-source and proprietary models, including audio-language models and multimodal LLMs, and show that current models fall far short of human judgments; no model exceeds 35% Hit@1 when selecting the top-ranked clip. DialBGM provides a standardized benchmark for developing discourse-aware methods for BGM selection and for evaluating both retrieval-based and generative models.
SMMILE: An Expert-Driven Benchmark for Multimodal Medical In-Context Learning
Jun 26, 2025



Multimodal in-context learning (ICL) remains underexplored despite significant potential for domains such as medicine. Clinicians routinely encounter diverse, specialized tasks requiring adaptation from limited examples, such as drawing insights from a few relevant prior cases or considering a constrained set of differential diagnoses. While multimodal large language models (MLLMs) have shown advances in medical visual question answering (VQA), their ability to learn multimodal tasks from context is largely unknown. We introduce SMMILE, the first expert-driven multimodal ICL benchmark for medical tasks. Eleven medical experts curated problems, each including a multimodal query and multimodal in-context examples as task demonstrations. SMMILE encompasses 111 problems (517 question-image-answer triplets) covering 6 medical specialties and 13 imaging modalities. We further introduce SMMILE++, an augmented variant with 1038 permuted problems. A comprehensive evaluation of 15 MLLMs demonstrates that most models exhibit moderate to poor multimodal ICL ability in medical tasks. In open-ended evaluations, ICL contributes only 8% average improvement over zero-shot on SMMILE and 9.4% on SMMILE++. We observe a susceptibility for irrelevant in-context examples: even a single noisy or irrelevant example can degrade performance by up to 9.5%. Moreover, example ordering exhibits a recency bias, i.e., placing the most relevant example last can lead to substantial performance improvements by up to 71%. Our findings highlight critical limitations and biases in current MLLMs when learning multimodal medical tasks from context.
PRISM: Complete Online Decentralized Multi-Agent Pathfinding with Rapid Information Sharing using Motion Constraints
May 12, 2025We introduce PRISM (Pathfinding with Rapid Information Sharing using Motion Constraints), a decentralized algorithm designed to address the multi-task multi-agent pathfinding (MT-MAPF) problem. PRISM enables large teams of agents to concurrently plan safe and efficient paths for multiple tasks while avoiding collisions. It employs a rapid communication strategy that uses information packets to exchange motion constraint information, enhancing cooperative pathfinding and situational awareness, even in scenarios without direct communication. We prove that PRISM resolves and avoids all deadlock scenarios when possible, a critical challenge in decentralized pathfinding. Empirically, we evaluate PRISM across five environments and 25 random scenarios, benchmarking it against the centralized Conflict-Based Search (CBS) and the decentralized Token Passing with Task Swaps (TPTS) algorithms. PRISM demonstrates scalability and solution quality, supporting 3.4 times more agents than CBS and handling up to 2.5 times more tasks in narrow passage environments than TPTS. Additionally, PRISM matches CBS in solution quality while achieving faster computation times, even under low-connectivity conditions. Its decentralized design reduces the computational burden on individual agents, making it scalable for large environments. These results confirm PRISM's robustness, scalability, and effectiveness in complex and dynamic pathfinding scenarios.
Deepfake-Eval-2024: A Multi-Modal In-the-Wild Benchmark of Deepfakes Circulated in 2024
Mar 05, 2025


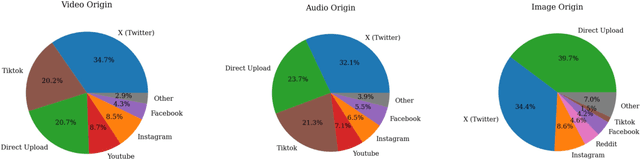
In the age of increasingly realistic generative AI, robust deepfake detection is essential for mitigating fraud and disinformation. While many deepfake detectors report high accuracy on academic datasets, we show that these academic benchmarks are out of date and not representative of real-world deepfakes. We introduce Deepfake-Eval-2024, a new deepfake detection benchmark consisting of in-the-wild deepfakes collected from social media and deepfake detection platform users in 2024. Deepfake-Eval-2024 consists of 45 hours of videos, 56.5 hours of audio, and 1,975 images, encompassing the latest manipulation technologies. The benchmark contains diverse media content from 88 different websites in 52 different languages. We find that the performance of open-source state-of-the-art deepfake detection models drops precipitously when evaluated on Deepfake-Eval-2024, with AUC decreasing by 50\% for video, 48\% for audio, and 45\% for image models compared to previous benchmarks. We also evaluate commercial deepfake detection models and models finetuned on Deepfake-Eval-2024, and find that they have superior performance to off-the-shelf open-source models, but do not yet reach the accuracy of deepfake forensic analysts. The dataset is available at https://github.com/nuriachandra/Deepfake-Eval-2024.
BLIP3-KALE: Knowledge Augmented Large-Scale Dense Captions
Nov 12, 2024



We introduce BLIP3-KALE, a dataset of 218 million image-text pairs that bridges the gap between descriptive synthetic captions and factual web-scale alt-text. KALE augments synthetic dense image captions with web-scale alt-text to generate factually grounded image captions. Our two-stage approach leverages large vision-language models and language models to create knowledge-augmented captions, which are then used to train a specialized VLM for scaling up the dataset. We train vision-language models on KALE and demonstrate improvements on vision-language tasks. Our experiments show the utility of KALE for training more capable and knowledgeable multimodal models. We release the KALE dataset at https://huggingface.co/datasets/Salesforce/blip3-kale
The Tug-of-War Between Deepfake Generation and Detection
Jul 08, 2024
Multimodal generative models are rapidly evolving, leading to a surge in the generation of realistic video and audio that offers exciting possibilities but also serious risks. Deepfake videos, which can convincingly impersonate individuals, have particularly garnered attention due to their potential misuse in spreading misinformation and creating fraudulent content. This survey paper examines the dual landscape of deepfake video generation and detection, emphasizing the need for effective countermeasures against potential abuses. We provide a comprehensive overview of current deepfake generation techniques, including face swapping, reenactment, and audio-driven animation, which leverage cutting-edge technologies like generative adversarial networks and diffusion models to produce highly realistic fake videos. Additionally, we analyze various detection approaches designed to differentiate authentic from altered videos, from detecting visual artifacts to deploying advanced algorithms that pinpoint inconsistencies across video and audio signals. The effectiveness of these detection methods heavily relies on the diversity and quality of datasets used for training and evaluation. We discuss the evolution of deepfake datasets, highlighting the importance of robust, diverse, and frequently updated collections to enhance the detection accuracy and generalizability. As deepfakes become increasingly indistinguishable from authentic content, developing advanced detection techniques that can keep pace with generation technologies is crucial. We advocate for a proactive approach in the "tug-of-war" between deepfake creators and detectors, emphasizing the need for continuous research collaboration, standardization of evaluation metrics, and the creation of comprehensive benchmarks.
MINT-1T: Scaling Open-Source Multimodal Data by 10x: A Multimodal Dataset with One Trillion Tokens
Jun 17, 2024



Multimodal interleaved datasets featuring free-form interleaved sequences of images and text are crucial for training frontier large multimodal models (LMMs). Despite the rapid progression of open-source LMMs, there remains a pronounced scarcity of large-scale, diverse open-source multimodal interleaved datasets. In response, we introduce MINT-1T, the most extensive and diverse open-source Multimodal INTerleaved dataset to date. MINT-1T comprises one trillion text tokens and three billion images, a 10x scale-up from existing open-source datasets. Additionally, we include previously untapped sources such as PDFs and ArXiv papers. As scaling multimodal interleaved datasets requires substantial engineering effort, sharing the data curation process and releasing the dataset greatly benefits the community. Our experiments show that LMMs trained on MINT-1T rival the performance of models trained on the previous leading dataset, OBELICS. Our data and code will be released at https://github.com/mlfoundations/MINT-1T.