 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination Index: An Image Quality Metric for Generative Reconstruction Models
Jul 17, 2024Generative image reconstruction algorithms such as measurement conditioned diffusion models are increasingly popular in the field of medical imaging. These powerful models can transform low signal-to-noise ratio (SNR) inputs into outputs with the appearance of high SNR. However, the outputs can have a new type of error called hallucinations. In medical imaging, these hallucinations may not be obvious to a Radiologist but could cause diagnostic errors. Generally, hallucination refers to error in estimation of object structure caused by a machine learning model, but there is no widely accepted method to evaluate hallucination magnitude. In this work, we propose a new image quality metric called the hallucination index. Our approach is to compute the Hellinger distance from the distribution of reconstructed images to a zero hallucination reference distribution. To evaluate our approach, we conducted a numerical experiment with electron microscopy images, simulated noisy measurements, and applied diffusion based reconstructions. We sampled the measurements and the generative reconstructions repeatedly to compute the sample mean and covariance. For the zero hallucination reference, we used the forward diffusion process applied to ground truth. Our results show that higher measurement SNR leads to lower hallucination index for the same apparent image quality. We also evaluated the impact of early stopping in the reverse diffusion process and found that more modest denoising strengths can reduce hallucination. We believe this metric could be useful for evaluation of generative image reconstructions or as a warning label to inform radiologists about the degree of hallucinations in medical images.
Bora: Biomedical Generalist Video Generation Model
Jul 12, 2024



Generative models hold promise for revolutionizing medical education, robot-assisted surgery, and data augmentation for medical AI development. Diffusion models can now generate realistic images from text prompts, while recent advancements have demonstrated their ability to create diverse, high-quality videos. However, these models often struggle with generating accurate representations of medical procedures and detailed anatomical structures. This paper introduces Bora, the first spatio-temporal diffusion probabilistic model designed for text-guided biomedical video generation. Bora leverages Transformer architecture and is pre-trained on general-purpose video generation tasks. It is fine-tuned through model alignment and instruction tuning using a newly established medical video corpus, which includes paired text-video data from various biomedical fields. To the best of our knowledge, this is the first attempt to establish such a comprehensive annotated biomedical video dataset. Bora is capable of generating high-quality video data across four distinct biomedical domains, adhering to medical expert standards and demonstrating consistency and diversity. This generalist video generative model holds significant potential for enhancing medical consultation and decision-making, particularly in resource-limited settings. Additionally, Bora could pave the way for immersive medical training and procedure planning. Extensive experiments on distinct medical modalities such as endoscopy, ultrasound, MRI, and cell tracking validate the effectiveness of our model in understanding biomedical instructions and its superior performance across subjects compared to state-of-the-art generation models.
Cross Prompting Consistency with Segment Anything Model for Semi-supervised Medical Image Segmentation
Jul 07, 2024



Semi-supervised learning (SSL) has achieved notable progress in medical image segmentation. To achieve effective SSL, a model needs to be able to efficiently learn from limited labeled data and effectively exploiting knowledge from abundant unlabeled data. Recent developments in visual foundation models, such as the Segment Anything Model (SAM), have demonstrated remarkable adaptability with improved sample efficiency. To harness the power of foundation models for application in SSL, we propose a cross prompting consistency method with segment anything model (CPC-SAM) for semi-supervised medical image segmentation. Our method employs SAM's unique prompt design and innovates a cross-prompting strategy within a dual-branch framework to automatically generate prompts and supervisions across two decoder branches, enabling effectively learning from both scarce labeled and valuable unlabeled data. We further design a novel prompt consistency regularization, to reduce the prompt position sensitivity and to enhance the output invariance under different prompts. We validate our method on two medical image segmentation tasks. The extensive experiments with different labeled-data ratios and modalities demonstrate the superiority of our proposed method over the state-of-the-art SSL methods, with more than 9% Dice improvement on the breast cancer segmentation task.
FM-OSD: Foundation Model-Enabled One-Shot Detection of Anatomical Landmarks
Jul 07, 2024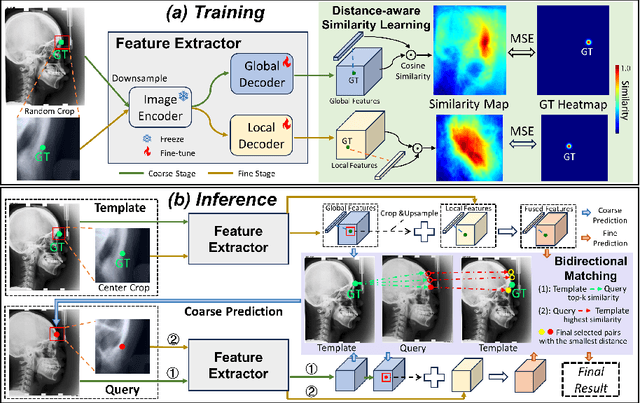


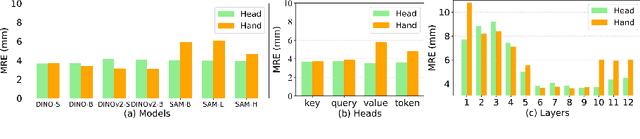
One-shot detection of anatomical landmarks is gaining significant attention for its efficiency in using minimal labeled data to produce promising results. However, the success of current methods heavily relies on the employment of extensive unlabeled data to pre-train an effective feature extractor, which limits their applicability in scenarios where a substantial amount of unlabeled data is unavailable. In this paper, we propose the first foundation model-enabled one-shot landmark detection (FM-OSD) framework for accurate landmark detection in medical images by utilizing solely a single template image without any additional unlabeled data. Specifically, we use the frozen image encoder of visual foundation models as the feature extractor, and introduce dual-branch global and local feature decoders to increase the resolution of extracted features in a coarse to fine manner. The introduced feature decoders are efficiently trained with a distance-aware similarity learning loss to incorporate domain knowledge from the single template image. Moreover, a novel bidirectional matching strategy is developed to improve both robustness and accuracy of landmark detection in the case of scattered similarity map obtained by foundation models. We validate our method on two public anatomical landmark detection datasets. By using solely a single template image, our method demonstrates significant superiority over strong state-of-the-art one-shot landmark detection methods.
Biomedical Visual Instruction Tuning with Clinician Preference Alignment
Jun 19, 2024



Recent advancements in multimodal foundation models have showcased impressive capabilities in understanding and reasoning with visual and textual information. Adapting these foundation models trained for general usage to specialized domains like biomedicine requires large-scale domain-specific instruction datasets. While existing works have explored curating such datasets automatically, the resultant datasets are not explicitly aligned with domain expertise. In this work, we propose a data-centric framework, Biomedical Visual Instruction Tuning with Clinician Preference Alignment (BioMed-VITAL), that incorporates clinician preferences into both stages of generating and selecting instruction data for tuning biomedical multimodal foundation models. First, during the generation stage, we prompt the GPT-4V generator with a diverse set of clinician-selected demonstrations for preference-aligned data candidate generation. Then, during the selection phase, we train a separate selection model, which explicitly distills clinician and policy-guided model preferences into a rating function to select high-quality data for medical instruction tuning. Results show that the model tuned with the instruction-following data from our method demonstrates a significant improvement in open visual chat (18.5% relatively) and medical VQA (win rate up to 81.73%). Our instruction-following data and models are available at BioMed-VITAL.github.io.
Dealing with All-stage Missing Modality: Towards A Universal Model with Robust Reconstruction and Personalization
Jun 04, 2024



Addressing missing modalities presents a critical challenge in multimodal learning. Current approaches focus on developing models that can handle modality-incomplete inputs during inference, assuming that the full set of modalities are available for all the data during training. This reliance on full-modality data for training limits the use of abundant modality-incomplete samples that are often encountered in practical settings. In this paper, we propose a robust universal model with modality reconstruction and model personalization, which can effectively tackle the missing modality at both training and testing stages. Our method leverages a multimodal masked autoencoder to reconstruct the missing modality and masked patches simultaneously, incorporating an innovative distribution approximation mechanism to fully utilize both modality-complete and modality-incomplete data. The reconstructed modalities then contributes to our designed data-model co-distillation scheme to guide the model learning in the presence of missing modalities. Moreover, we propose a CLIP-driven hyper-network to personalize partial model parameters, enabling the model to adapt to each distinct missing modality scenario. Our method has been extensively validated on two brain tumor segmentation benchmarks. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches under the all-stage missing modality settings with different missing ratios. Code will be available.
Nuclear Medicine Artificial Intelligence in Action: The Bethesda Report (AI Summit 2024)
Jun 03, 2024
The 2nd SNMMI Artificial Intelligence (AI) Summit, organized by the SNMMI AI Task Force, took place in Bethesda, MD, on February 29 - March 1, 2024. Bringing together various community members and stakeholders, and following up on a prior successful 2022 AI Summit, the summit theme was: AI in Action. Six key topics included (i) an overview of prior and ongoing efforts by the AI task force, (ii) emerging needs and tools for computational nuclear oncology, (iii) new frontiers in large language and generative models, (iv) defining the value proposition for the use of AI in nuclear medicine, (v) open science including efforts for data and model repositories, and (vi) issues of reimbursement and funding. The primary efforts, findings, challenges, and next steps are summarized in this manuscript.
Contrastive Learning Via Equivariant Representation
Jun 01, 2024



Invariant-based Contrastive Learning (ICL) methods have achieved impressive performance across various domains. However, the absence of latent space representation for distortion (augmentation)-related information in the latent space makes ICL sub-optimal regarding training efficiency and robustness in downstream tasks. Recent studies suggest that introducing equivariance into Contrastive Learning (CL) can improve overall performance. In this paper, we rethink the roles of augmentation strategies and equivariance in improving CL efficacy. We propose a novel Equivariant-based Contrastive Learning (ECL) framework, CLeVER (Contrastive Learning Via Equivariant Representation), compatible with augmentation strategies of arbitrary complexity for various mainstream CL methods and model frameworks. Experimental results demonstrate that CLeVER effectively extracts and incorporates equivariant information from data, thereby improving the training efficiency and robustness of baseline models in downstream tasks.
Autonomous Robotic Ultrasound System for Liver Follow-up Diagnosis: Pilot Phantom Study
May 09, 2024



The paper introduces a novel autonomous robot ultrasound (US) system targeting liver follow-up scans for outpatients in local communities. Given a computed tomography (CT) image with specific target regions of interest, the proposed system carries out the autonomous follow-up scan in three steps: (i) initial robot contact to surface, (ii) coordinate mapping between CT image and robot, and (iii) target US scan. Utilizing 3D US-CT registration and deep learning-based segmentation networks, we can achieve precise imaging of 3D hepatic veins, facilitating accurate coordinate mapping between CT and the robot. This enables the automatic localization of follow-up targets within the CT image, allowing the robot to navigate precisely to the target's surface. Evaluation of the ultrasound phantom confirms the quality of the US-CT registration and shows the robot reliably locates the targets in repeated trials. The proposed framework holds the potential to significantly reduce time and costs for healthcare providers, clinicians, and follow-up patients, thereby addressing the increasing healthcare burden associated with chronic disease in local communities.
Prompt-driven Universal Model for View-Agnostic Echocardiography Analysis
Apr 09, 2024Echocardiography segmentation for cardiac analysis is time-consuming and resource-intensive due to the variability in image quality and the necessity to process scans from various standard views. While current automated segmentation methods in echocardiography show promising performance, they are trained on specific scan views to analyze corresponding data. However, this solution has a limitation as the number of required models increases with the number of standard views. To address this, in this paper, we present a prompt-driven universal method for view-agnostic echocardiography analysis. Considering the domain shift between standard views, we first introduce a method called prompt matching, aimed at learning prompts specific to different views by matching prompts and querying input embeddings using a pre-trained vision model. Then, we utilized a pre-trained medical language model to align textual information with pixel data for accurate segmentation. Extensive experiments on three standard views showed that our approach significantly outperforms the state-of-the-art universal methods and achieves comparable or even better performances over the segmentation model trained and tested on same views.