 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Search to Synthesis: Training LLMs as Zero-Shot Workflow Generators
Jun 29, 2026Large language models (LLMs) excel across a wide range of tasks, yet their instance-specific solutions often lack the structural consistency needed for reliable deployment. Workflows that encode recurring algorithmic patterns at the task level provide a principled framework, offering robustness across instance variations, interpretable traces for debugging, and reusability across problem instances. However, manually designing such workflows requires significant expertise and effort, limiting their broader application. While automatic workflow generation could address this bottleneck, existing methods either produce instance-specific solutions without learning task-level patterns, or cannot generalize beyond their training configurations. We present MetaFlow, which casts workflow generation as a meta-learning problem: given a task and an operator set, the model learns to compose solution strategies. MetaFlow trains in two stages: supervised fine-tuning on synthetic workflow data, followed by reinforcement learning with verifiable rewards (RLVR) that uses execution feedback across problem instances in the task to improve end-to-end success. The resulting model produces effective workflows for trained tasks and exhibits strong generalization to untrained tasks and novel operator sets. Across benchmarks in question answering, code generation, and mathematical reasoning, MetaFlow achieves performance comparable to state-of-the-art baselines on in-domain tasks with single inference, while demonstrating remarkable zero-shot generalization capabilities on out-of-domain tasks and operator sets.
Iteris: Agentic Research Loops for Computational Mathematics
Jun 01, 2026Recent advances in large language models and agentic AI systems have enabled significant progress in mathematical discovery, from solving competition problems to tackling research-level conjectures. However, open problems in computational mathematics have received comparatively less attention: research in this area often requires not only proofs but also numerical experimentation, adversarial constructions, and algorithm design. In this paper, we introduce an agentic research system, Iteris, designed for open problems in computational mathematics. We apply Iteris to two open problems from a recent Simons Workshop collection (arXiv:2602.05394). In these case studies, Iteris generated numerical evidence, constructions, and proof drafts that led, after expert review and correction, to verified results. The first result is a phase diagram for the asymptotic comparison between conjugate gradient and randomized coordinate descent on power-law spectra; the second is a counterexample showing that QR factorization with column pivoting can fail to select well-conditioned submatrices even under low coherence. These case studies suggest that agentic AI systems can participate meaningfully in research workflows for open problems in computational mathematics, while human validation remains essential.
LeanSearch v2: Global Premise Retrieval for Lean 4 Theorem Proving
May 14, 2026Proving theorems in Lean 4 often requires identifying a scattered set of library lemmas whose joint use enables a concise proof -- a task we call global premise retrieval. Existing tools address adjacent problems: semantic search engines find individual declarations matching a query, while premise-selection systems predict useful lemmas one tactic step at a time. Neither recovers the full premise set an entire theorem requires. We present LeanSearch v2, a two-mode retrieval system for this task. Its standard mode applies a hierarchy-informalized Mathlib corpus with an embedding-reranker pipeline, achieving state-of-the-art single-query retrieval without domain-specific fine-tuning (nDCG@10 of 0.62 vs. 0.53 for the next-best system). Its reasoning mode builds on standard mode as its retrieval substrate, targeting global premise retrieval through iterative sketch-retrieve-reflect cycles. On a 69-query benchmark of research-level Mathlib theorems, reasoning mode recovers 46.1% of ground-truth premise groups within 10 retrieved candidates, outperforming strong reasoning retrieval systems (38.0%) and premise-selection baselines (9.3%) on the same benchmark. In a controlled downstream evaluation with a fixed prover loop, replacing alternative retrievers with LeanSearch v2 yields the highest proof success (20% vs. 16% for the next-best system and 4% without retrieval), confirming that retrieval quality propagates to proof generation. We have open-sourced all code, data, and benchmarks. Code and data: https://github.com/frenzymath/LeanSearch-v2 . The standard mode is publicly available with API access at https://leansearch.net/ .
Matlas: A Semantic Search Engine for Mathematics
Apr 19, 2026Retrieving mathematical knowledge is a central task in both human-driven research, such as determining whether a result already exists, finding related results, and identifying historical origins, and in emerging AI systems for mathematics, where reliable grounding is essential. However, the scale and structure of the mathematical literature pose significant challenges: results are distributed across millions of documents, and individual statements are often difficult to interpret in isolation due to their dependence on prior definitions and theorems. In this paper, we introduce Matlas, a semantic search engine for mathematical statements. Matlas is built on a large-scale corpus of 8.07 million statements extracted from 435K peer-reviewed papers spanning 1826 to 2025, drawn from a curated set of 180 journals selected using an ICM citation-based criterion, together with 1.9K textbooks. From these sources, we extract mathematical statements together with their dependencies, construct document-level dependency graphs, and recursively unfold statements in topological order to produce more self-contained representations. On top of this corpus, we develop a semantic retrieval system that enables efficient search for mathematical results using natural language queries. We hope that Matlas can improve the efficiency of theorem retrieval for mathematicians and provide a structured source of grounding for AI systems tackling research-level mathematical problems, and serve as part of the infrastructure for mathematical knowledge retrieval.
Automated Conjecture Resolution with Formal Verification
Apr 04, 2026Recent advances in large language models have significantly improved their ability to perform mathematical reasoning, extending from elementary problem solving to increasingly capable performance on research-level problems. However, reliably solving and verifying such problems remains challenging due to the inherent ambiguity of natural language reasoning. In this paper, we propose an automated framework for tackling research-level mathematical problems that integrates natural language reasoning with formal verification, enabling end-to-end problem solving with minimal human intervention. Our framework consists of two components: an informal reasoning agent, Rethlas, and a formal verification agent, Archon. Rethlas mimics the workflow of human mathematicians by combining reasoning primitives with our theorem search engine, Matlas, to explore solution strategies and construct candidate proofs. Archon, equipped with our formal theorem search engine LeanSearch, translates informal arguments into formalized Lean 4 projects through structured task decomposition, iterative refinement, and automated proof synthesis, ensuring machine-checkable correctness. Using this framework, we automatically resolve an open problem in commutative algebra and formally verify the resulting proof in Lean 4 with essentially no human involvement. Our experiments demonstrate that strong theorem retrieval tools enable the discovery and application of cross-domain mathematical techniques, while the formal agent is capable of autonomously filling nontrivial gaps in informal arguments. More broadly, our work illustrates a promising paradigm for mathematical research in which informal and formal reasoning systems, equipped with theorem retrieval tools, operate in tandem to produce verifiable results, substantially reduce human effort, and offer a concrete instantiation of human-AI collaborative mathematical research.
From Atoms to Trees: Building a Structured Feature Forest with Hierarchical Sparse Autoencoders
Feb 12, 2026Sparse autoencoders (SAEs) have proven effective for extracting monosemantic features from large language models (LLMs), yet these features are typically identified in isolation. However, broad evidence suggests that LLMs capture the intrinsic structure of natural language, where the phenomenon of "feature splitting" in particular indicates that such structure is hierarchical. To capture this, we propose the Hierarchical Sparse Autoencoder (HSAE), which jointly learns a series of SAEs and the parent-child relationships between their features. HSAE strengthens the alignment between parent and child features through two novel mechanisms: a structural constraint loss and a random feature perturbation mechanism. Extensive experiments across various LLMs and layers demonstrate that HSAE consistently recovers semantically meaningful hierarchies, supported by both qualitative case studies and rigorous quantitative metrics. At the same time, HSAE preserves the reconstruction fidelity and interpretability of standard SAEs across different dictionary sizes. Our work provides a powerful, scalable tool for discovering and analyzing the multi-scale conceptual structures embedded in LLM representations.
Translating Informal Proofs into Formal Proofs Using a Chain of States
Dec 12, 2025



We address the problem of translating informal mathematical proofs expressed in natural language into formal proofs in Lean4 under a constrained computational budget. Our approach is grounded in two key insights. First, informal proofs tend to proceed via a sequence of logical transitions - often implications or equivalences - without explicitly specifying intermediate results or auxiliary lemmas. In contrast, formal systems like Lean require an explicit representation of each proof state and the tactics that connect them. Second, each informal reasoning step can be viewed as an abstract transformation between proof states, but identifying the corresponding formal tactics often requires nontrivial domain knowledge and precise control over proof context. To bridge this gap, we propose a two stage framework. Rather than generating formal tactics directly, we first extract a Chain of States (CoS), a sequence of intermediate formal proof states aligned with the logical structure of the informal argument. We then generate tactics to transition between adjacent states in the CoS, thereby constructing the full formal proof. This intermediate representation significantly reduces the complexity of tactic generation and improves alignment with informal reasoning patterns. We build dedicated datasets and benchmarks for training and evaluation, and introduce an interactive framework to support tactic generation from formal states. Empirical results show that our method substantially outperforms existing baselines, achieving higher proof success rates.
SciAgent: A Unified Multi-Agent System for Generalistic Scientific Reasoning
Nov 17, 2025Recent advances in large language models have enabled AI systems to achieve expert-level performance on domain-specific scientific tasks, yet these systems remain narrow and handcrafted. We introduce SciAgent, a unified multi-agent system designed for generalistic scientific reasoning-the ability to adapt reasoning strategies across disciplines and difficulty levels. SciAgent organizes problem solving as a hierarchical process: a Coordinator Agent interprets each problem's domain and complexity, dynamically orchestrating specialized Worker Systems, each composed of interacting reasoning Sub-agents for symbolic deduction, conceptual modeling, numerical computation, and verification. These agents collaboratively assemble and refine reasoning pipelines tailored to each task. Across mathematics and physics Olympiads (IMO, IMC, IPhO, CPhO), SciAgent consistently attains or surpasses human gold-medalist performance, demonstrating both domain generality and reasoning adaptability. Additionally, SciAgent has been tested on the International Chemistry Olympiad (IChO) and selected problems from the Humanity's Last Exam (HLE) benchmark, further confirming the system's ability to generalize across diverse scientific domains. This work establishes SciAgent as a concrete step toward generalistic scientific intelligence-AI systems capable of coherent, cross-disciplinary reasoning at expert levels.
MorphoBench: A Benchmark with Difficulty Adaptive to Model Reasoning
Oct 16, 2025

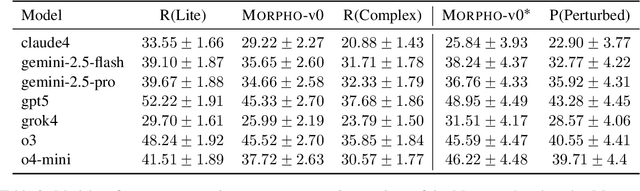
With the advancement of powerful large-scale reasoning models, effectively evaluating the reasoning capabilities of these models has become increasingly important. However, existing benchmarks designed to assess the reasoning abilities of large models tend to be limited in scope and lack the flexibility to adapt their difficulty according to the evolving reasoning capacities of the models. To address this, we propose MorphoBench, a benchmark that incorporates multidisciplinary questions to evaluate the reasoning capabilities of large models and can adjust and update question difficulty based on the reasoning abilities of advanced models. Specifically, we curate the benchmark by selecting and collecting complex reasoning questions from existing benchmarks and sources such as Olympiad-level competitions. Additionally, MorphoBench adaptively modifies the analytical challenge of questions by leveraging key statements generated during the model's reasoning process. Furthermore, it includes questions generated using simulation software, enabling dynamic adjustment of benchmark difficulty with minimal resource consumption. We have gathered over 1,300 test questions and iteratively adjusted the difficulty of MorphoBench based on the reasoning capabilities of models such as o3 and GPT-5. MorphoBench enhances the comprehensiveness and validity of model reasoning evaluation, providing reliable guidance for improving both the reasoning abilities and scientific robustness of large models. The code has been released in https://github.com/OpenDCAI/MorphoBench.
Aligning Perception, Reasoning, Modeling and Interaction: A Survey on Physical AI
Oct 06, 2025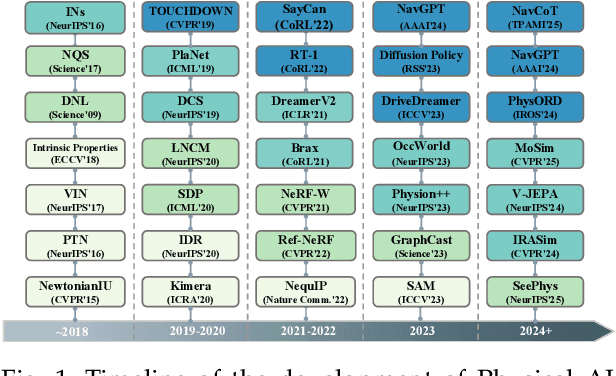
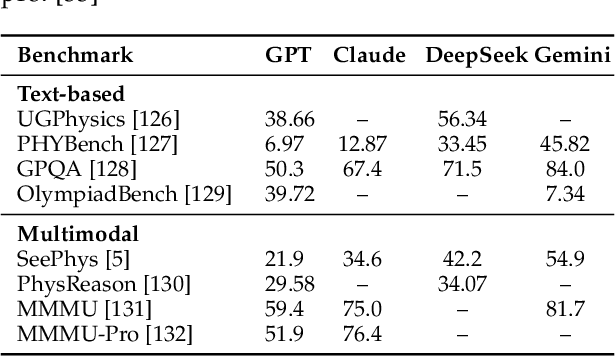
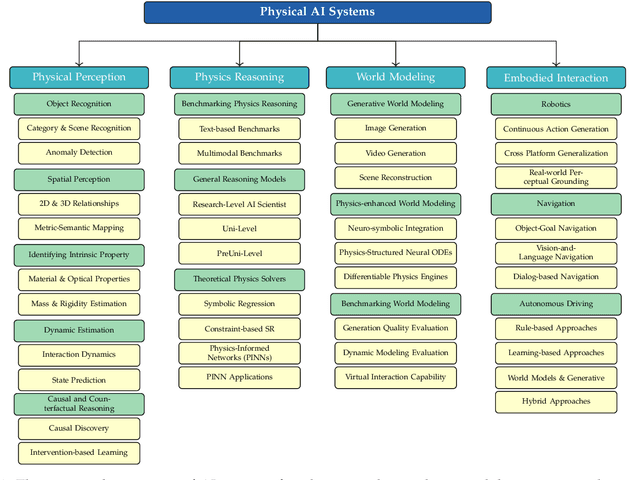
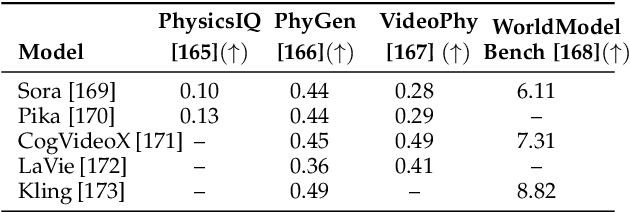
The rapid advancement of embodied intelligence and world models has intensified efforts to integrate physical laws into AI systems, yet physical perception and symbolic physics reasoning have developed along separate trajectories without a unified bridging framework. This work provides a comprehensive overview of physical AI, establishing clear distinctions between theoretical physics reasoning and applied physical understanding while systematically examining how physics-grounded methods enhance AI's real-world comprehension across structured symbolic reasoning, embodied systems, and generative models. Through rigorous analysis of recent advances, we advocate for intelligent systems that ground learning in both physical principles and embodied reasoning processes, transcending pattern recognition toward genuine understanding of physical laws. Our synthesis envisions next-generation world models capable of explaining physical phenomena and predicting future states, advancing safe, generalizable, and interpretable AI systems. We maintain a continuously updated resource at https://github.com/AI4Phys/Awesome-AI-for-Physics.