 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESICA: A Scalable Framework for Text-Guided 3D Medical Image Segmentation
Apr 27, 2026Text guided 3D medical image segmentation offers a flexible alternative to class based and spatial prompt based models by allowing users to specify regions of interest directly in natural language. This paradigm avoids reliance on predefined label sets, reduces ambiguous outputs, and aligns more naturally with clinical workflows. However, existing text guided frameworks are often computationally expensive, exhibit weak text volume feature alignment, and fail to capture fine anatomical details. We propose ESICA, a lightweight and scalable framework that addresses these challenges through three innovations: (1) a similarity matrix based mask prediction formulation that enhances semantic alignment, (2) an efficient decomposed decoder with adapter modules for accurate volumetric decoding, and (3) a two pass refinement strategy that sharpens boundaries and resolves uncertain regions. To improve training stability and generalization, ESICA adopts a two stage scheme consisting of positive only pretraining followed by balanced fine tuning. On the CVPR BiomedSegFM benchmark spanning five imaging modalities (CT, MRI, PET, ultrasound, and microscopy), ESICA achieves state of the art segmentation accuracy, while the compact ESICA4 Lite variant attains similar segmentation performance with substantially fewer parameters, yielding a superior efficiency accuracy trade off. Our framework advances text guided segmentation toward efficient, scalable, and clinically deployable systems. Code will be made publicly available at https://github.com/mirthAI/ESICA.
Structure-Adaptive Sparse Diffusion in Voxel Space for 3D Medical Image Enhancement
Apr 20, 2026Three-dimensional (3D) medical image enhancement, including denoising and super-resolution, is critical for clinical diagnosis in CT, PET, and MRI. Although diffusion models have shown remarkable success in 2D medical imaging, scaling them to high-resolution 3D volumes remains computationally prohibitive due to lengthy diffusion trajectories over high-dimensional volumetric data. We observe that in conditional enhancement, strong anatomical priors in the degraded input render dense noise schedules largely redundant. Leveraging this insight, we propose a sparse voxel-space diffusion framework that trains and samples on a compact set of uniformly subsampled timesteps. The network predicts clean data directly on the data manifold, supervised in velocity space for stable gradient scaling. A lightweight Structure-aware Trajectory Modulation (STM) module recalibrates time embeddings at each network block based on local anatomical content, enabling structure-adaptive denoising over the shared sparse schedule. Operating directly in voxel space, our framework preserves fine anatomical detail without lossy compression while achieving up to $10\times$ training acceleration. Experiments on four datasets spanning CT, PET, and MRI demonstrate state-of-the-art performance on both denoising and super-resolution tasks. Our code is publicly available at: https://github.com/mirthAI/sparse-3d-diffusion.
REVEAL: Multimodal Vision-Language Alignment of Retinal Morphometry and Clinical Risks for Incident AD and Dementia Prediction
Apr 20, 2026The retina provides a unique, noninvasive window into Alzheimer's disease (AD) and dementia, capturing early structural changes through morphometric features, while systemic and lifestyle risk factors reflect well-established contributors to disease susceptibility long before clinical symptom onset. However, current retinal analysis frameworks typically model imaging and risk factors separately, limiting their ability to capture joint multimodal patterns critical for early risk prediction. Moreover, existing methods rarely incorporate mechanisms to organize or align patients with similar retinal and clinical characteristics, constraining the learning of coherent cross-modal associations. To address these limitations, we introduce REVEAL (REtinal-risk Vision-Language Early Alzheimer's Learning), a framework that aligns color fundus photographs with individualized disease-specific risk profiles for predicting incident AD and dementia, on average 8 years before diagnosis (range: 1-11 years). Because real-world risk factors are structured questionnaire data, we translate them into clinically interpretable narratives compatible with pretrained vision-language models (VLMs). We further propose a group-aware contrastive learning (GACL) strategy that clusters patients with similar retinal morphometry and risk factors as positive pairs, strengthening multimodal alignment. This unified representation learning framework substantially outperforms state-of-the-art retinal imaging models paired with clinical text encoders, as well as general-purpose VLMs, demonstrating the value of jointly modeling retinal biomarkers and clinical risk factors. By providing a generalizable and noninvasive approach for early AD and dementia risk stratification, REVEAL has the potential to enable earlier intervention and improve preventive care at the population level.
Beyond the Embedding Bottleneck: Adaptive Retrieval-Augmented 3D CT Report Generation
Mar 16, 2026Automated radiology report generation from 3D CT volumes often suffers from incomplete pathology coverage. We provide empirical evidence that this limitation stems from a representational bottleneck: contrastive 3D CT embeddings encode discriminative pathology signals, yet exhibit severe dimensional concentration, with as few as 2 effective dimensions out of 512. Corroborating this, scaling the language model yields no measurable improvement, suggesting that the bottleneck lies in the visual representation rather than the generator. This bottleneck limits both generation and retrieval; naive static retrieval fails to improve clinical efficacy and can even degrade performance. We propose \textbf{AdaRAG-CT}, an adaptive augmentation framework that compensates for this visual bottleneck by introducing supplementary textual information through controlled retrieval and selectively integrating it during generation. On the CT-RATE benchmark, AdaRAG-CT achieves state-of-the-art clinical efficacy, improving Clinical F1 from 0.420 (CT-Agent) to 0.480 (+6 points); ablation studies confirm that both the retrieval and generation components contribute to the improvement. Code is available at https://github.com/renjie-liang/Adaptive-RAG-for-3DCT-Report-Generation.
MedVL-SAM2: A unified 3D medical vision-language model for multimodal reasoning and prompt-driven segmentation
Jan 14, 2026Recent progress in medical vision-language models (VLMs) has achieved strong performance on image-level text-centric tasks such as report generation and visual question answering (VQA). However, achieving fine-grained visual grounding and volumetric spatial reasoning in 3D medical VLMs remains challenging, particularly when aiming to unify these capabilities within a single, generalizable framework. To address this challenge, we proposed MedVL-SAM2, a unified 3D medical multimodal model that concurrently supports report generation, VQA, and multi-paradigm segmentation, including semantic, referring, and interactive segmentation. MedVL-SAM2 integrates image-level reasoning and pixel-level perception through a cohesive architecture tailored for 3D medical imaging, and incorporates a SAM2-based volumetric segmentation module to enable precise multi-granular spatial reasoning. The model is trained in a multi-stage pipeline: it is first pre-trained on a large-scale corpus of 3D CT image-text pairs to align volumetric visual features with radiology-language embeddings. It is then jointly optimized with both language-understanding and segmentation objectives using a comprehensive 3D CT segmentation dataset. This joint training enables flexible interaction via language, point, or box prompts, thereby unifying high-level visual reasoning with spatially precise localization. Our unified architecture delivers state-of-the-art performance across report generation, VQA, and multiple 3D segmentation tasks. Extensive analyses further show that the model provides reliable 3D visual grounding, controllable interactive segmentation, and robust cross-modal reasoning, demonstrating that high-level semantic reasoning and precise 3D localization can be jointly achieved within a unified 3D medical VLM.
Patlak Parametric Image Estimation from Dynamic PET Using Diffusion Model Prior
Dec 22, 2025Dynamic PET enables the quantitative estimation of physiology-related parameters and is widely utilized in research and increasingly adopted in clinical settings. Parametric imaging in dynamic PET requires kinetic modeling to estimate voxel-wise physiological parameters based on specific kinetic models. However, parametric images estimated through kinetic model fitting often suffer from low image quality due to the inherently ill-posed nature of the fitting process and the limited counts resulting from non-continuous data acquisition across multiple bed positions in whole-body PET. In this work, we proposed a diffusion model-based kinetic modeling framework for parametric image estimation, using the Patlak model as an example. The score function of the diffusion model was pre-trained on static total-body PET images and served as a prior for both Patlak slope and intercept images by leveraging their patch-wise similarity. During inference, the kinetic model was incorporated as a data-consistency constraint to guide the parametric image estimation. The proposed framework was evaluated on total-body dynamic PET datasets with different dose levels, demonstrating the feasibility and promising performance of the proposed framework in improving parametric image quality.
TauGenNet: Plasma-Driven Tau PET Image Synthesis via Text-Guided 3D Diffusion Models
Sep 04, 2025



Accurate quantification of tau pathology via tau positron emission tomography (PET) scan is crucial for diagnosing and monitoring Alzheimer's disease (AD). However, the high cost and limited availability of tau PET restrict its widespread use. In contrast, structural magnetic resonance imaging (MRI) and plasma-based biomarkers provide non-invasive and widely available complementary information related to brain anatomy and disease progression. In this work, we propose a text-guided 3D diffusion model for 3D tau PET image synthesis, leveraging multimodal conditions from both structural MRI and plasma measurement. Specifically, the textual prompt is from the plasma p-tau217 measurement, which is a key indicator of AD progression, while MRI provides anatomical structure constraints. The proposed framework is trained and evaluated using clinical AV1451 tau PET data from the Alzheimer's Disease Neuroimaging Initiative (ADNI) database. Experimental results demonstrate that our approach can generate realistic, clinically meaningful 3D tau PET across a range of disease stages. The proposed framework can help perform tau PET data augmentation under different settings, provide a non-invasive, cost-effective alternative for visualizing tau pathology, and support the simulation of disease progression under varying plasma biomarker levels and cognitive conditions.
SAM2-SGP: Enhancing SAM2 for Medical Image Segmentation via Support-Set Guided Prompting
Jun 24, 2025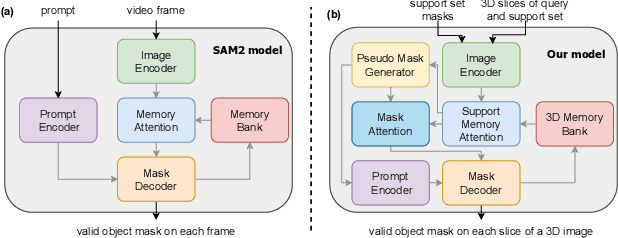
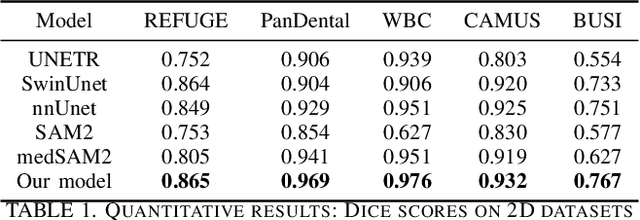
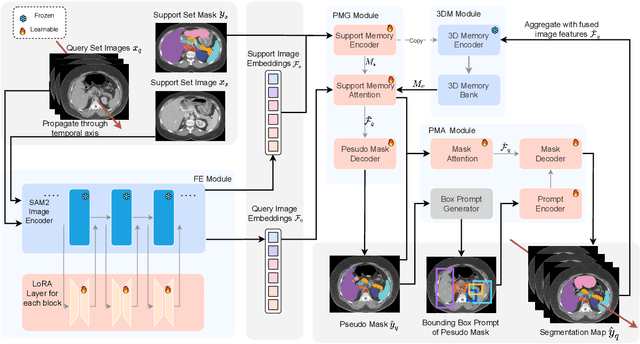
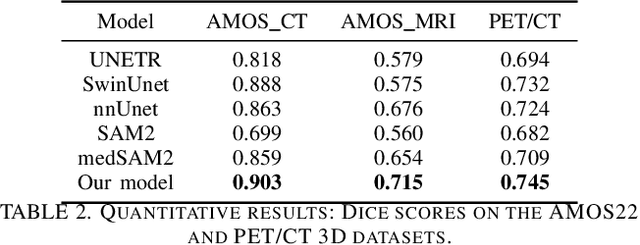
Although new vision foundation models such as Segment Anything Model 2 (SAM2) have significantly enhanced zero-shot image segmentation capabilities, reliance on human-provided prompts poses significant challenges in adapting SAM2 to medical image segmentation tasks. Moreover, SAM2's performance in medical image segmentation was limited by the domain shift issue, since it was originally trained on natural images and videos. To address these challenges, we proposed SAM2 with support-set guided prompting (SAM2-SGP), a framework that eliminated the need for manual prompts. The proposed model leveraged the memory mechanism of SAM2 to generate pseudo-masks using image-mask pairs from a support set via a Pseudo-mask Generation (PMG) module. We further introduced a novel Pseudo-mask Attention (PMA) module, which used these pseudo-masks to automatically generate bounding boxes and enhance localized feature extraction by guiding attention to relevant areas. Furthermore, a low-rank adaptation (LoRA) strategy was adopted to mitigate the domain shift issue. The proposed framework was evaluated on both 2D and 3D datasets across multiple medical imaging modalities, including fundus photography, X-ray, computed tomography (CT), magnetic resonance imaging (MRI), positron emission tomography (PET), and ultrasound. The results demonstrated a significant performance improvement over state-of-the-art models, such as nnUNet and SwinUNet, as well as foundation models, such as SAM2 and MedSAM2, underscoring the effectiveness of the proposed approach. Our code is publicly available at https://github.com/astlian9/SAM_Support.
CDPDNet: Integrating Text Guidance with Hybrid Vision Encoders for Medical Image Segmentation
May 25, 2025



Most publicly available medical segmentation datasets are only partially labeled, with annotations provided for a subset of anatomical structures. When multiple datasets are combined for training, this incomplete annotation poses challenges, as it limits the model's ability to learn shared anatomical representations among datasets. Furthermore, vision-only frameworks often fail to capture complex anatomical relationships and task-specific distinctions, leading to reduced segmentation accuracy and poor generalizability to unseen datasets. In this study, we proposed a novel CLIP-DINO Prompt-Driven Segmentation Network (CDPDNet), which combined a self-supervised vision transformer with CLIP-based text embedding and introduced task-specific text prompts to tackle these challenges. Specifically, the framework was constructed upon a convolutional neural network (CNN) and incorporated DINOv2 to extract both fine-grained and global visual features, which were then fused using a multi-head cross-attention module to overcome the limited long-range modeling capability of CNNs. In addition, CLIP-derived text embeddings were projected into the visual space to help model complex relationships among organs and tumors. To further address the partial label challenge and enhance inter-task discriminative capability, a Text-based Task Prompt Generation (TTPG) module that generated task-specific prompts was designed to guide the segmentation. Extensive experiments on multiple medical imaging datasets demonstrated that CDPDNet consistently outperformed existing state-of-the-art segmentation methods. Code and pretrained model are available at: https://github.com/wujiong-hub/CDPDNet.git.
Med3DVLM: An Efficient Vision-Language Model for 3D Medical Image Analysis
Mar 25, 2025Vision-language models (VLMs) have shown promise in 2D medical image analysis, but extending them to 3D remains challenging due to the high computational demands of volumetric data and the difficulty of aligning 3D spatial features with clinical text. We present Med3DVLM, a 3D VLM designed to address these challenges through three key innovations: (1) DCFormer, an efficient encoder that uses decomposed 3D convolutions to capture fine-grained spatial features at scale; (2) SigLIP, a contrastive learning strategy with pairwise sigmoid loss that improves image-text alignment without relying on large negative batches; and (3) a dual-stream MLP-Mixer projector that fuses low- and high-level image features with text embeddings for richer multi-modal representations. We evaluate our model on the M3D dataset, which includes radiology reports and VQA data for 120,084 3D medical images. Results show that Med3DVLM achieves superior performance across multiple benchmarks. For image-text retrieval, it reaches 61.00% R@1 on 2,000 samples, significantly outperforming the current state-of-the-art M3D model (19.10%). For report generation, it achieves a METEOR score of 36.42% (vs. 14.38%). In open-ended visual question answering (VQA), it scores 36.76% METEOR (vs. 33.58%), and in closed-ended VQA, it achieves 79.95% accuracy (vs. 75.78%). These results highlight Med3DVLM's ability to bridge the gap between 3D imaging and language, enabling scalable, multi-task reasoning across clinical applications. Our code is publicly available at https://github.com/mirthAI/Med3DVLM.