 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEM: Multi-Scale Embodied Memory for Vision Language Action Models
Mar 04, 2026Conventionally, memory in end-to-end robotic learning involves inputting a sequence of past observations into the learned policy. However, in complex multi-stage real-world tasks, the robot's memory must represent past events at multiple levels of granularity: from long-term memory that captures abstracted semantic concepts (e.g., a robot cooking dinner should remember which stages of the recipe are already done) to short-term memory that captures recent events and compensates for occlusions (e.g., a robot remembering the object it wants to pick up once its arm occludes it). In this work, our main insight is that an effective memory architecture for long-horizon robotic control should combine multiple modalities to capture these different levels of abstraction. We introduce Multi-Scale Embodied Memory (MEM), an approach for mixed-modal long-horizon memory in robot policies. MEM combines video-based short-horizon memory, compressed via a video encoder, with text-based long-horizon memory. Together, they enable robot policies to perform tasks that span up to fifteen minutes, like cleaning up a kitchen, or preparing a grilled cheese sandwich. Additionally, we find that memory enables MEM policies to intelligently adapt manipulation strategies in-context.
SteerVLA: Steering Vision-Language-Action Models in Long-Tail Driving Scenarios
Feb 09, 2026A fundamental challenge in autonomous driving is the integration of high-level, semantic reasoning for long-tail events with low-level, reactive control for robust driving. While large vision-language models (VLMs) trained on web-scale data offer powerful common-sense reasoning, they lack the grounded experience necessary for safe vehicle control. We posit that an effective autonomous agent should leverage the world knowledge of VLMs to guide a steerable driving policy toward robust control in driving scenarios. To this end, we propose SteerVLA, which leverages the reasoning capabilities of VLMs to produce fine-grained language instructions that steer a vision-language-action (VLA) driving policy. Key to our method is this rich language interface between the high-level VLM and low-level VLA, which allows the high-level policy to more effectively ground its reasoning in the control outputs of the low-level policy. To provide fine-grained language supervision aligned with vehicle control, we leverage a VLM to augment existing driving data with detailed language annotations, which we find to be essential for effective reasoning and steerability. We evaluate SteerVLA on a challenging closed-loop benchmark, where it outperforms state-of-the-art methods by 4.77 points in overall driving score and by 8.04 points on a long-tail subset. The project website is available at: https://steervla.github.io/.
$π^{*}_{0.6}$: a VLA That Learns From Experience
Nov 19, 2025We study how vision-language-action (VLA) models can improve through real-world deployments via reinforcement learning (RL). We present a general-purpose method, RL with Experience and Corrections via Advantage-conditioned Policies (RECAP), that provides for RL training of VLAs via advantage conditioning. Our method incorporates heterogeneous data into the self-improvement process, including demonstrations, data from on-policy collection, and expert teleoperated interventions provided during autonomous execution. RECAP starts by pre-training a generalist VLA with offline RL, which we call $π^{*}_{0.6}$, that can then be specialized to attain high performance on downstream tasks through on-robot data collection. We show that the $π^{*}_{0.6}$ model trained with the full RECAP method can fold laundry in real homes, reliably assemble boxes, and make espresso drinks using a professional espresso machine. On some of the hardest tasks, RECAP more than doubles task throughput and roughly halves the task failure rate.
Learning to Drive Anywhere with Model-Based Reannotation11
May 08, 2025Developing broadly generalizable visual navigation policies for robots is a significant challenge, primarily constrained by the availability of large-scale, diverse training data. While curated datasets collected by researchers offer high quality, their limited size restricts policy generalization. To overcome this, we explore leveraging abundant, passively collected data sources, including large volumes of crowd-sourced teleoperation data and unlabeled YouTube videos, despite their potential for lower quality or missing action labels. We propose Model-Based ReAnnotation (MBRA), a framework that utilizes a learned short-horizon, model-based expert model to relabel or generate high-quality actions for these passive datasets. This relabeled data is then distilled into LogoNav, a long-horizon navigation policy conditioned on visual goals or GPS waypoints. We demonstrate that LogoNav, trained using MBRA-processed data, achieves state-of-the-art performance, enabling robust navigation over distances exceeding 300 meters in previously unseen indoor and outdoor environments. Our extensive real-world evaluations, conducted across a fleet of robots (including quadrupeds) in six cities on three continents, validate the policy's ability to generalize and navigate effectively even amidst pedestrians in crowded settings.
$π_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Apr 22, 2025



In order for robots to be useful, they must perform practically relevant tasks in the real world, outside of the lab. While vision-language-action (VLA) models have demonstrated impressive results for end-to-end robot control, it remains an open question how far such models can generalize in the wild. We describe $\pi_{0.5}$, a new model based on $\pi_{0}$ that uses co-training on heterogeneous tasks to enable broad generalization. $\pi_{0.5}$\ uses data from multiple robots, high-level semantic prediction, web data, and other sources to enable broadly generalizable real-world robotic manipulation. Our system uses a combination of co-training and hybrid multi-modal examples that combine image observations, language commands, object detections, semantic subtask prediction, and low-level actions. Our experiments show that this kind of knowledge transfer is essential for effective generalization, and we demonstrate for the first time that an end-to-end learning-enabled robotic system can perform long-horizon and dexterous manipulation skills, such as cleaning a kitchen or bedroom, in entirely new homes.
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Jan 16, 2025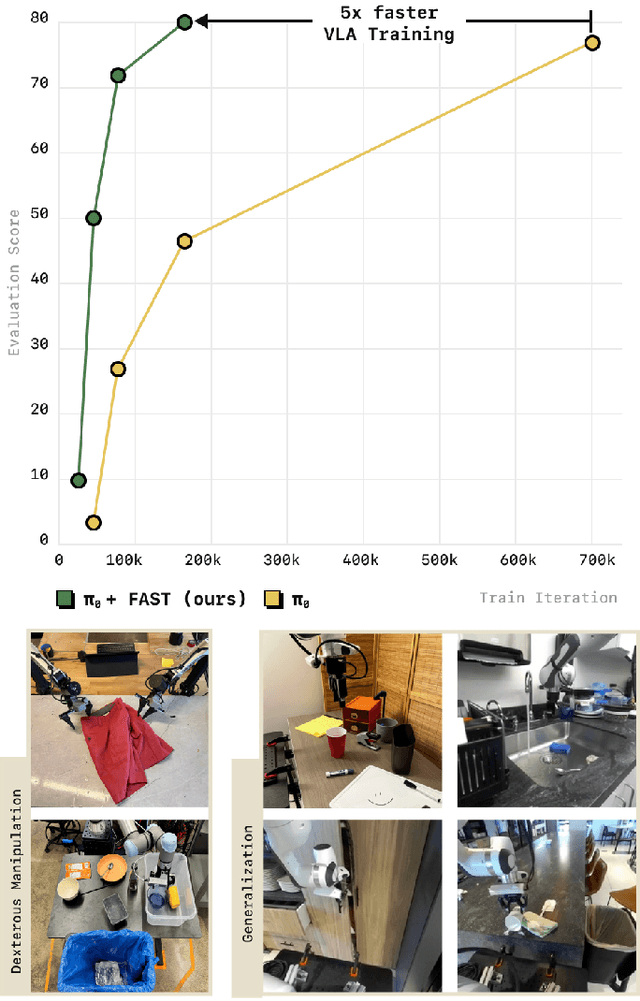

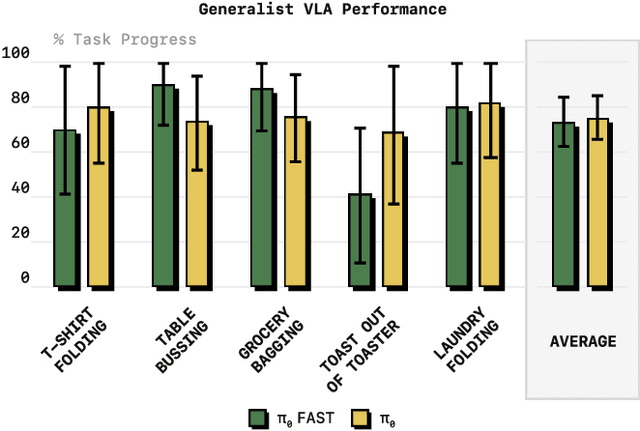
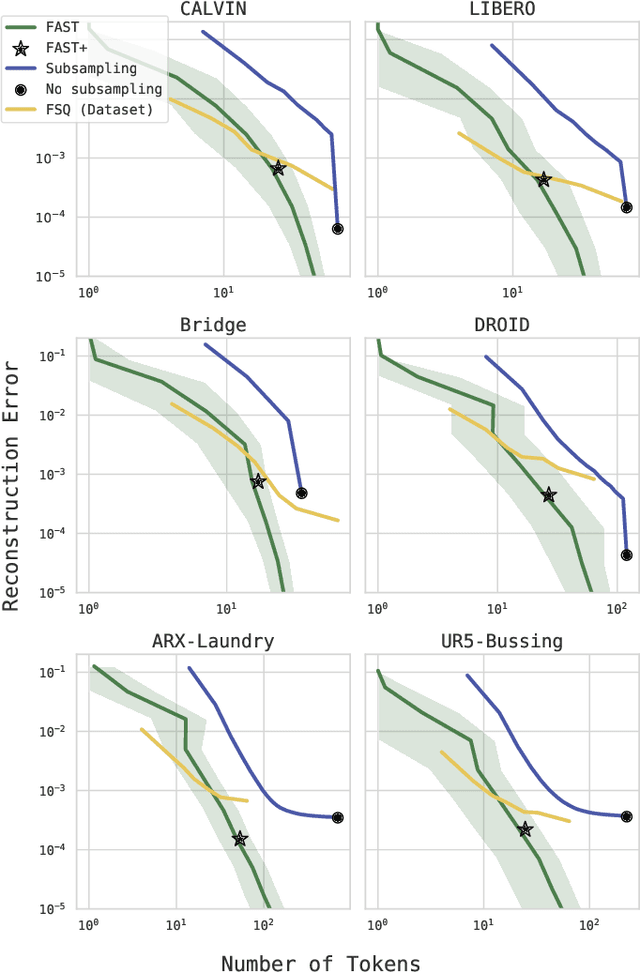
Autoregressive sequence models, such as Transformer-based vision-language action (VLA) policies, can be tremendously effective for capturing complex and generalizable robotic behaviors. However, such models require us to choose a tokenization of our continuous action signals, which determines how the discrete symbols predicted by the model map to continuous robot actions. We find that current approaches for robot action tokenization, based on simple per-dimension, per-timestep binning schemes, typically perform poorly when learning dexterous skills from high-frequency robot data. To address this challenge, we propose a new compression-based tokenization scheme for robot actions, based on the discrete cosine transform. Our tokenization approach, Frequency-space Action Sequence Tokenization (FAST), enables us to train autoregressive VLAs for highly dexterous and high-frequency tasks where standard discretization methods fail completely. Based on FAST, we release FAST+, a universal robot action tokenizer, trained on 1M real robot action trajectories. It can be used as a black-box tokenizer for a wide range of robot action sequences, with diverse action spaces and control frequencies. Finally, we show that, when combined with the pi0 VLA, our method can scale to training on 10k hours of robot data and match the performance of diffusion VLAs, while reducing training time by up to 5x.
Beyond Sight: Finetuning Generalist Robot Policies with Heterogeneous Sensors via Language Grounding
Jan 08, 2025Interacting with the world is a multi-sensory experience: achieving effective general-purpose interaction requires making use of all available modalities -- including vision, touch, and audio -- to fill in gaps from partial observation. For example, when vision is occluded reaching into a bag, a robot should rely on its senses of touch and sound. However, state-of-the-art generalist robot policies are typically trained on large datasets to predict robot actions solely from visual and proprioceptive observations. In this work, we propose FuSe, a novel approach that enables finetuning visuomotor generalist policies on heterogeneous sensor modalities for which large datasets are not readily available by leveraging natural language as a common cross-modal grounding. We combine a multimodal contrastive loss with a sensory-grounded language generation loss to encode high-level semantics. In the context of robot manipulation, we show that FuSe enables performing challenging tasks that require reasoning jointly over modalities such as vision, touch, and sound in a zero-shot setting, such as multimodal prompting, compositional cross-modal prompting, and descriptions of objects it interacts with. We show that the same recipe is applicable to widely different generalist policies, including both diffusion-based generalist policies and large vision-language-action (VLA) models. Extensive experiments in the real world show that FuSeis able to increase success rates by over 20% compared to all considered baselines.
Traversability-Aware Legged Navigation by Learning from Real-World Visual Data
Oct 14, 2024The enhanced mobility brought by legged locomotion empowers quadrupedal robots to navigate through complex and unstructured environments. However, optimizing agile locomotion while accounting for the varying energy costs of traversing different terrains remains an open challenge. Most previous work focuses on planning trajectories with traversability cost estimation based on human-labeled environmental features. However, this human-centric approach is insufficient because it does not account for the varying capabilities of the robot locomotion controllers over challenging terrains. To address this, we develop a novel traversability estimator in a robot-centric manner, based on the value function of the robot's locomotion controller. This estimator is integrated into a new learning-based RGBD navigation framework. The framework develops a planner that guides the robot in avoiding obstacles and hard-to-traverse terrains while reaching its goals. The training of the navigation planner is directly performed in the real world using a sample efficient reinforcement learning method. Through extensive benchmarking, we demonstrate that the proposed framework achieves the best performance in accurate traversability cost estimation and efficient learning from multi-modal data (the robot's color and depth vision, and proprioceptive feedback) for real-world training. Using the proposed method, a quadrupedal robot learns to perform traversability-aware navigation through trial and error in various real-world environments with challenging terrains that are difficult to classify using depth vision alone.
RACER: Epistemic Risk-Sensitive RL Enables Fast Driving with Fewer Crashes
May 07, 2024



Reinforcement learning provides an appealing framework for robotic control due to its ability to learn expressive policies purely through real-world interaction. However, this requires addressing real-world constraints and avoiding catastrophic failures during training, which might severely impede both learning progress and the performance of the final policy. In many robotics settings, this amounts to avoiding certain "unsafe" states. The high-speed off-road driving task represents a particularly challenging instantiation of this problem: a high-return policy should drive as aggressively and as quickly as possible, which often requires getting close to the edge of the set of "safe" states, and therefore places a particular burden on the method to avoid frequent failures. To both learn highly performant policies and avoid excessive failures, we propose a reinforcement learning framework that combines risk-sensitive control with an adaptive action space curriculum. Furthermore, we show that our risk-sensitive objective automatically avoids out-of-distribution states when equipped with an estimator for epistemic uncertainty. We implement our algorithm on a small-scale rally car and show that it is capable of learning high-speed policies for a real-world off-road driving task. We show that our method greatly reduces the number of safety violations during the training process, and actually leads to higher-performance policies in both driving and non-driving simulation environments with similar challenges.
SELFI: Autonomous Self-Improvement with Reinforcement Learning for Social Navigation
Mar 01, 2024Autonomous self-improving robots that interact and improve with experience are key to the real-world deployment of robotic systems. In this paper, we propose an online learning method, SELFI, that leverages online robot experience to rapidly fine-tune pre-trained control policies efficiently. SELFI applies online model-free reinforcement learning on top of offline model-based learning to bring out the best parts of both learning paradigms. Specifically, SELFI stabilizes the online learning process by incorporating the same model-based learning objective from offline pre-training into the Q-values learned with online model-free reinforcement learning. We evaluate SELFI in multiple real-world environments and report improvements in terms of collision avoidance, as well as more socially compliant behavior, measured by a human user study. SELFI enables us to quickly learn useful robotic behaviors with less human interventions such as pre-emptive behavior for the pedestrians, collision avoidance for small and transparent objects, and avoiding travel on uneven floor surfaces. We provide supplementary videos to demonstrate the performance of our fine-tuned policy on our project page.